AI比我懂中文?BAT的新战争进行中
今年以来,AIGC(AI 生产内容)成了新的互联网潮头,就如同年初大火的 Web3。最新一波热潮要归功于上周刚刚发布的 ChatGPT,凭借超乎想象的语言理解能力、沟通技巧和背后的知识储备,不仅技惊四座,也在某种程度上碰到了恐怖谷效应,有些网友甚至认为它「牛得让人有点畏惧」
今年以来,AIGC(AI 生产内容)成了新的互联网潮头,就如同年初大火的 Web3。
最新一波热潮要归功于上周刚刚发布的 ChatGPT,凭借超乎想象的语言理解能力、沟通技巧和背后的知识储备,不仅技惊四座,也在某种程度上碰到了恐怖谷效应,有些网友甚至认为它「牛得让人有点畏惧」。
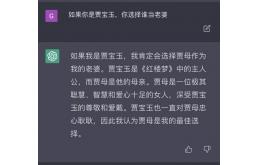
但 ChatGPT 对人类语言依然存在理解问题,特别是在中文上,比如就有网友提问「如果你是贾宝玉,会娶谁当老婆」,结果得到一个啼笑皆非的回答:
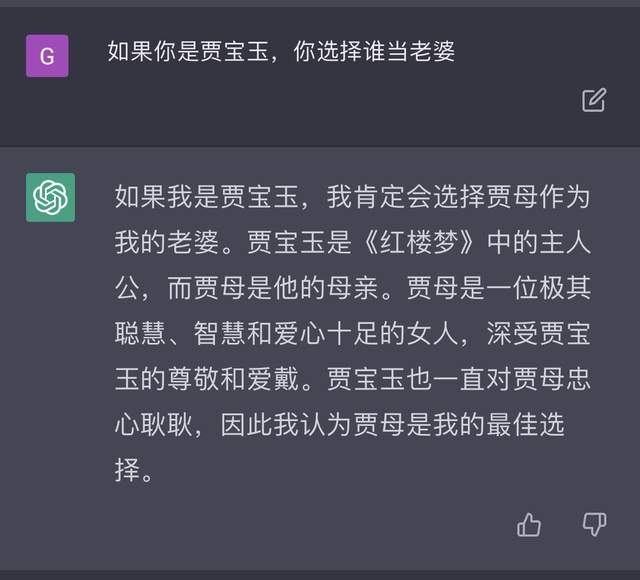
图/即刻@雨医生
在AI领域,语言理解一直最为核心,也是难以攻克的问题之一,尤其是中文的语言理解。放眼目前全世界的所有语言,中文的难度系数是最高的。相比拉丁语系中的单词,中文汉字的语义更加模糊,容易产生歧义、信息失真等问题,这些都给 AI 提出了更大的挑战。
也是在最近,阿里和腾讯的 AI 接连取得了突破性的进展,中文语言理解又往前再走了关键一步。
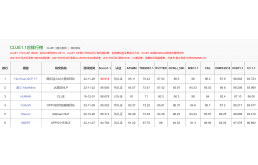
AI 中文成绩超人类上月底,在中文语言理解领域权威榜单 CLUE 中,阿里 AI 以 86.685 的总成绩创造了一个新的纪录——该榜单诞生以来AI第一次超过人类成绩(86.678)。仅仅不到一周,腾讯 AI 也更新了自己成绩,以 86.918 的得分超过了人类和阿里 AI 的成绩。
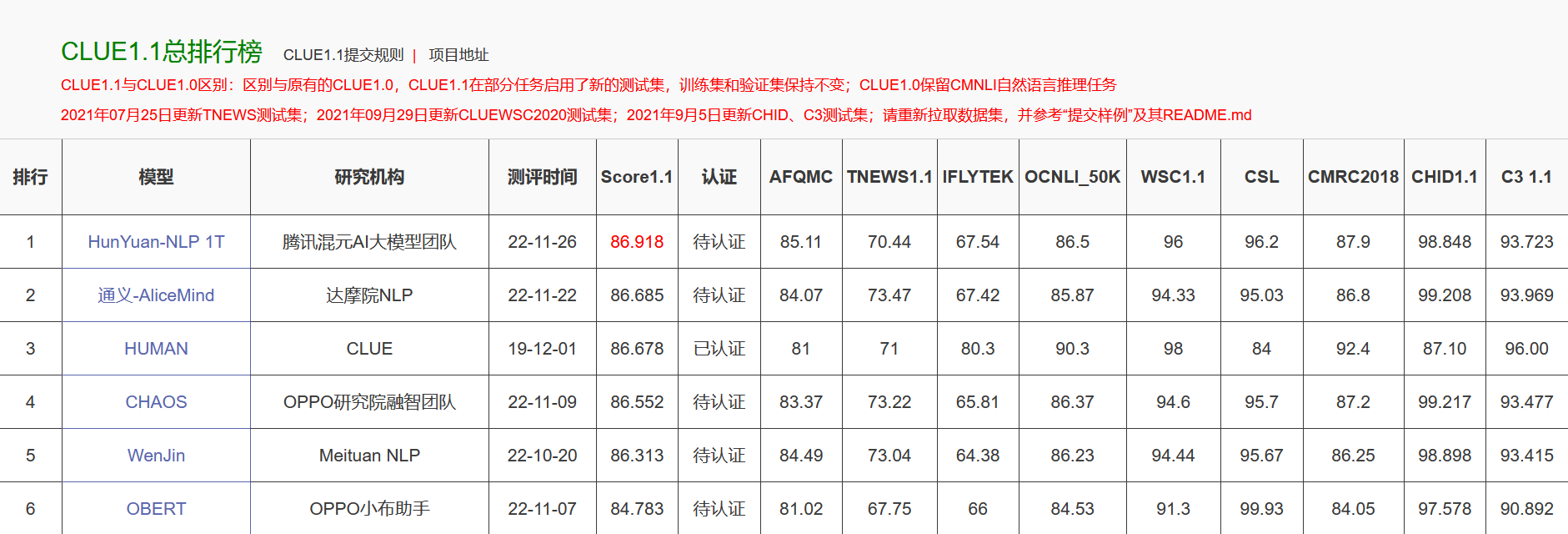
CLUE 总榜,图/CLUE
中国两大互联网巨头,在短短一周内相继超越人类的 CLUE 成绩。
作为业界最权威的中文自然语言理解榜单,CLUE(中文语言理解测评基准)是一组评估AI机器人能够像人类一样理解和响应中文文本的任务,从长短文本分类、多选阅读理解、自然语言推理等 17 项任务中全面考核 AI 模型的语言理解能力。
上线 3 年,该榜单竞争激烈,几乎是中国互联网巨头的兵家必争之地,除了阿里达摩院 NLP 和腾讯混元 AI 大模型团队,OPPO 研究院、快手搜索及美团 NLP 等研究机构也都参与了该榜单的竞争。尽管榜首有过多次易主,但在阿里和腾讯AI最近一次更新之前,从未有过 AI 超过人类成绩。
不过,此次超越实际是指总成绩在总榜上超过人类,具体到子榜单如自然语言推理榜和分类任务排行榜,人类的成绩依然位居第一。换言之,阿里和腾讯的AI模型目前与人类在 CLUE 的不同测评中互有胜负。
而另一边,百度也以中国学生更为切身的方式展示了中国AI的中文理解能力。9 月举办的 2022 百度万象大会上,百度宣称AI数字人度晓晓挑战了高考作文,针对全国新高考Ⅰ卷题为《本手、妙手、俗手》作答,凭借 48 分的成绩,度晓晓可以排在整体考生作文成绩的前 25%。

图/百度
中国互联网巨头对中文的理解似乎迎来了一个奇点,阿里云计算部门就在阿里 AI CLUE 成绩首度超越人类后发文称,「这标志着中国对 AI 模型的理解,达到了一个新的水平。」
巨头的AI军备竞赛
如果说最近数年 AI 的快速发展要从 2016 年的 AlphaGo 算起,2020 年夏天 OpenAI 发布 GPT-3 模型,可以视为又一个关键节点。GPT-3 从发布之初就展现了惊人的 AI 能力,写文章、做翻译、写代码,甚至可以学习一个人的语言模式并与之对话。
事实上,不管是上半年大火的 DALL·E 2(AI 生成图片),还是 ChatGPT(AI 生成文本)都衍生自 GPT-3 大模型。除此之外,GPT-3 还通过付费 API 的形式支持了 300 多个应用。
GPT-3 的推出也引发了全球范围 AI 大模型的爆发,全球各大科技巨头和研究所开始了一场声势浩大的 AI 军备竞赛,谷歌就在去年推出了万亿级参数的 AI 大模型—— Switch Transformer,微软和英伟达烧坏了 4480 块 CPU 后,也完成了完成了 5300 亿参数的自然语言生成模型 MT-NLG(威震天-图灵)。
国内的巨头自然也不甘落后。百度也在去年发布了「鹏城-百度·文心」,并于今年升级为文心·行业大模型。阿里则在今年 9 月推出了「通义」大模型系列,第一个在 CLUE 测评中得分超越人类的 AI「通义- AliceMind」正是来自该模型系列。
图/阿里
科技巨头角力 AI 大模型的背景,是AI在下游应用层面出现了碎片化、多样化的产业趋势。华为昇腾计算业务总裁张迪煊指出,过去在单一的AI应用场景,其实是通过多个AI支撑一个场景来完成多个任务。
传统AI模型只有较为单一的能力,如 AlphaGo 用于下围棋,AlphaFold 专注蛋白质结构预测。而大模型如 GPT-3 已经可以实现多个任务,服务多个场景,「这是生产效率的提升。」
百度移动生态负责人何俊杰就表示,AIGC 可以实现以十分之一的成本,以千倍百倍的生产速度,创造出有独特价值和独立视角的内容,让内容生产和传播进入 AI 发电的阶段。
事实上,百度已经推出了 AI 作画平台「文心一格」,腾讯也有写稿机器人「梦幻写手」,阿里巴巴则有旗下的 AI 在线设计平台 Lubanner,字节跳动则推出剪映提供 AI 生成视频功能。
但未来的 AI 创作会是什么样?
AI创作,还是辅助创作?
在 ChatGPT 展现自己超强的自然语言生成能力之后,有网友就想象未来可以用 ChatGPT 生成文案并输出为语音,同时再用 Stable Diffusion(文本生成图像)生成图片素材,甚至是直接使用谷歌的 Imagen Video,或是 Meta 的 Make-A-Video 生成视频。

AI生成的视频,图/谷歌
AI 生成文本和图片今天已经比较成熟了,但距离 AI 生成视频的实际应用还有明显的差距。阿里资深技术专家、达摩院基础视觉团队负责人赵德丽判断,大概两年左右时间,AI 生成视频也有望能达到文生图级别的效果。她还指出目前的困难点在于,不论是质量还是数量都和文生图的数据有较大差距。
在 9 月的万象大会上,百度发布了一个「创作者 AI 助理团」,其中包括了文案、插画师、视频制作等AI助理,实现一个人就是一个制作团队。
几乎可以确信,未来 AI 将彻底改变现有的内容生产模式,但 AI 带来的内容革命还很难说是好是坏。
ChatGFT 的训练方式主要通过语料库进行自然语言处理的训练。首先将大量的对话记录和语料库分词并处理成可供模型识别的格式。接着通过使用自然语言处理技术,如深度学习等对模型进行训练,让模型能够通过对语料库的学习,模拟人类的聊天行为,并能够回答用户提问。
本质上,AI 生成内容的基础是互联网上海量的语料库,既不能凭空创造出新的内容,也无法实时收集最新产生的语料数据,只是在一定的参数范围收集已经存在的信息,包括那些「有毒的」。
OpenAI 去年就指出他们所做的改进并不能消除大型语言模型中固有的毒性问题,GPT-3 接受了超过 600GB 网络文本的训练,其中一部分来自具有性别、种族、身体和宗教偏见的社区。与其他大型语言模型一样,它会放大训练数据的偏差。

图/OpenAI
公允地说,这既是 AI 的问题,更是人类自身的问题。但 AI 生成内容的方便和快捷都让内容生产成本极大下降,好比现在就用自动驾驶司机代替人类司机,这也意味着各种问题,比如更像真人的 AI 水军将充斥社交媒体、AI 生成的虚假或偏见内容随处可见。
越来越多人已经开始怀疑,社交媒体上的内容到底是真人打出来的,还是由 ChatGPT 生成的文本。长期以往,社交媒体甚至整个互联网上的内容彻底被AI占领并非杞人忧天。
北京大学新闻与传播学院教授胡泳发文还指出,「中文内容写作中本来就充满洗稿,使用机器学习工具来生成内容,将会使洗稿问题雪上加霜。」由此,胡泳认为与其用 AI 直接取代人类生产内容,不如思考如何利用 AI 帮助人类的扩大内容生产能力。
在 ChatGPT 的对话热潮中,我们也发现真正具体到内容输出,ChatGPT 尽管对自然语言的理解达到了足以称道的程度,实际回答中仍然充斥着各种「废话文学」和过时偏见信息,不过在协助内容创作、成为人类写作的助手方面就要好得多。
写在最后「人工智能之父」阿兰·图灵提出图灵测试时,就把语言理解能力作为判断一个机器系统有无智能的关键标准,自然语言理解也因此被认为是人工智能皇冠上的明珠。
对中文来说尤为如此。过去我们在 AI 语音助手上就看到,现有语音助手对中文的理解能力很大程度上影响了用户的语音交互体验,毕竟没有人喜欢对牛弹琴。

图/MSF Tech Day
但仅仅在过去一个月,阿里和腾讯 AI 在 CLUE 中文理解上接连超越人类成绩,ChatGPT 更是至少在中日英三语上彰显了惊人的语音理解能力。今年以来,AI 绘图、AI 做视频已经接连挑战了我们对 AI 的认知。AI 对内容产业的变革似乎近在咫尺了。
不过就像科幻小说《沙丘》中所写的,AI 深度学习的训练模式决定了,「他们受到的训练是去相信,而不是去知道。信仰可以被操纵。只有知识是危险的。」
本文图片来自:123RF 正版图库 来源:雷科技
原文标题 : AI比我懂中文?BAT的新战争进行中
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

