文心一言,一言难尽
赶鸭子上架的“百度” ChatGPT以火箭般的速度爆红,沉静许久的中国科技圈和创投界的终于再次引发热潮。互联网大佬王慧文自掏腰包、带资建组,科技大厂摩拳擦掌、争先恐后,创业公司也不遑多让,甚至跟AI不搭边的个别企业也借势营销,并因此而收获一波股价的大涨

赶鸭子上架的“百度”
ChatGPT以火箭般的速度爆红,沉静许久的中国科技圈和创投界的终于再次引发热潮。互联网大佬王慧文自掏腰包、带资建组,科技大厂摩拳擦掌、争先恐后,创业公司也不遑多让,甚至跟AI不搭边的个别企业也借势营销,并因此而收获一波股价的大涨。
但真正下场目前要发布产品就只有百度了。以AI技术见长,号称过去10年在AI领域投入超过1100亿元研发费用的百度,自然成为被关注的对象。是骡子是马总要拉出来溜溜才行。
但巧合的是,OpenAI于3月15日发布GPT-4瞬间火爆全网,但已经定下3月16日发布的百度总不能推迟日子,说好的对标ChatGPT呢?
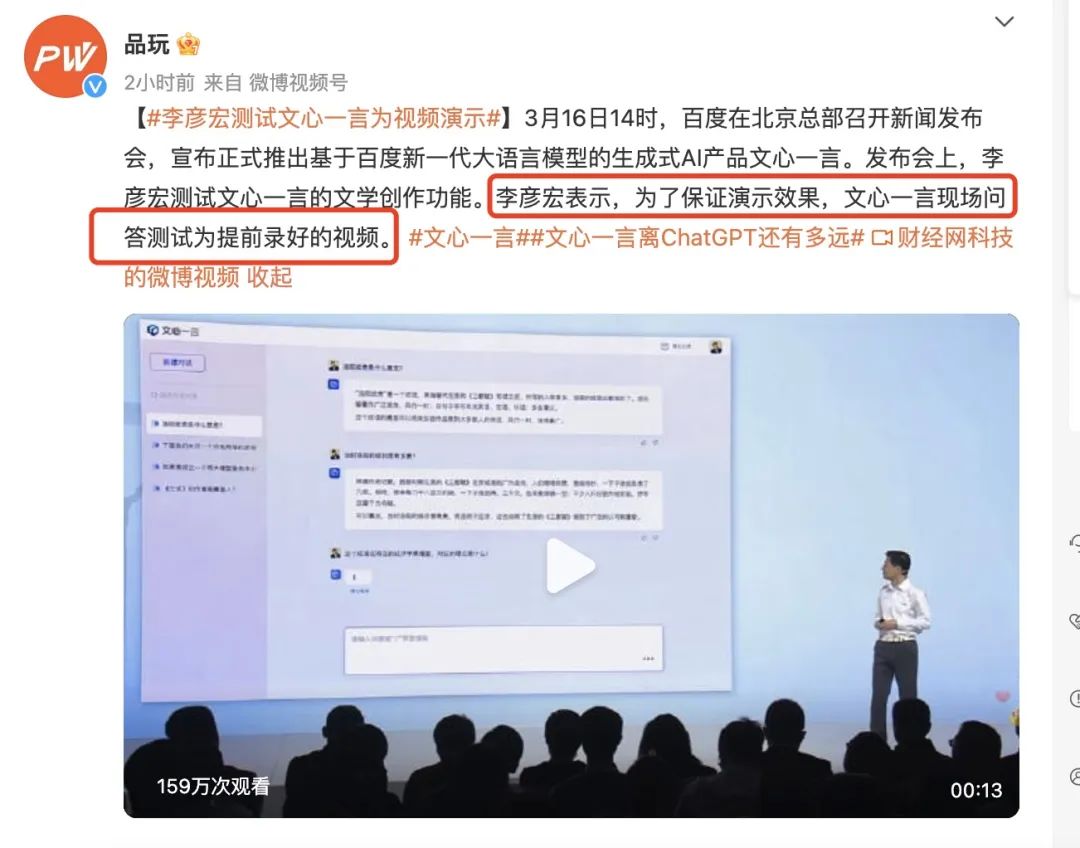
但想象中的百度版ChatGPT没来,“ChatPPT”倒是来了。发布会的演示最重点的就是实际使用的演示,从乔布斯的年代开始都是如此。老罗的李姐万岁言犹在耳。百度这次选择了全录制,很难不让人联想到是担心出现老罗一样的事故,也就代表着有很强烈的不自信;当然也可能是被 Google 演示的小错误事故吓怕了。
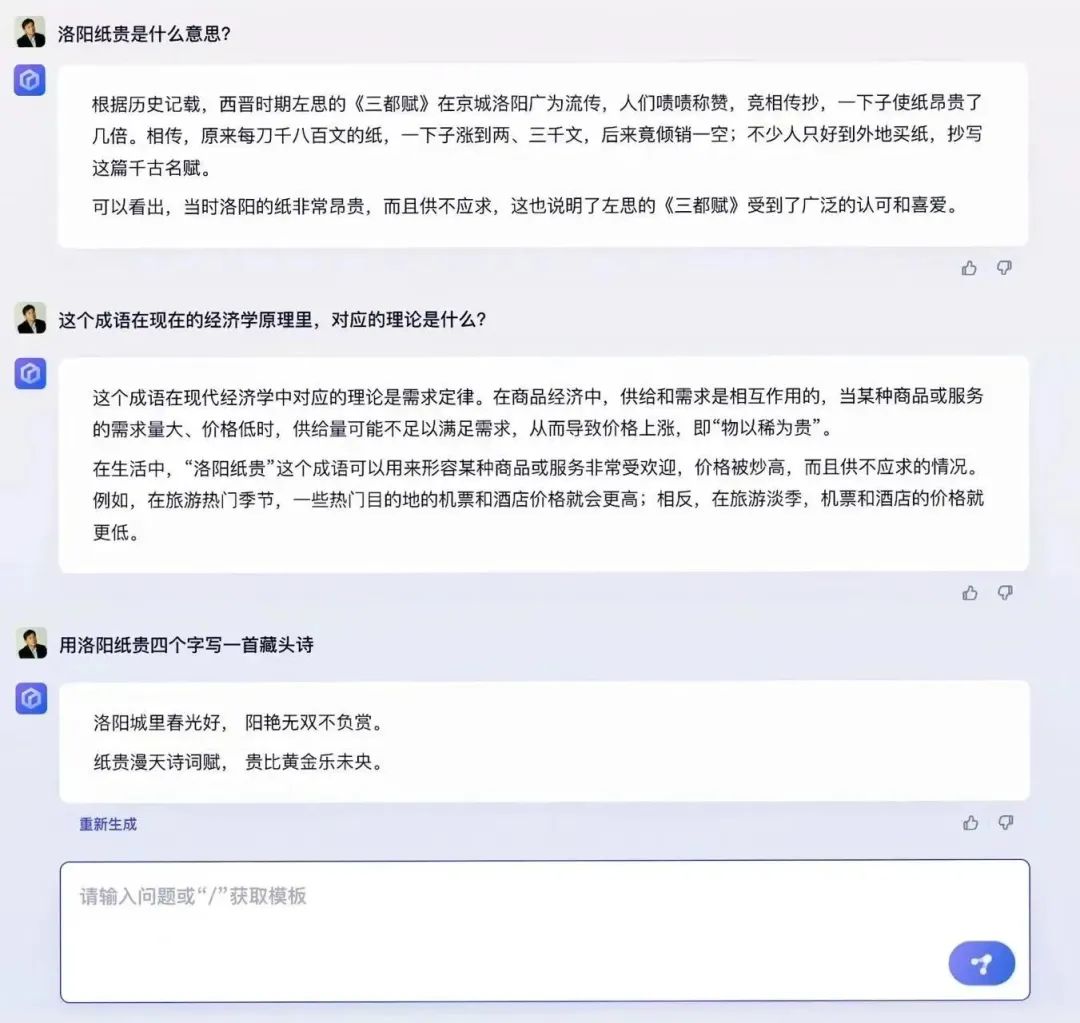
发布会现场,李彦宏用提前录制好的视频展示了文心一言的文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成等五方面功能。在录制好的视频里,文心一言帮刘慈欣续写了《三体》,介绍了洛阳纸贵背后的经济学原理,算了鸡兔同笼数学题,根据指令生成了海报和一段宣传视频。
但是明显进步的GPT-4在昨天已经拉高了群众期待,你百度遮遮掩掩拿一个半成品算怎么回事呢?资本市场可不管你什么网络原因,先跑为敬所以百度发布会当天一度跌停。
百度这次发布会,有着很明显是背着很重的销售 KPI 包袱的,在聊后面的部分,都是 toB 销售的话术,讲技术的抽象概念和商业合作的价值。这就跟OpenAI大篇幅讲产品形成了鲜明对比,观感不好还是其次,没讲好产品那就是加负分了。
录播的文心一言就一定不行吗
根据多家媒体对文心一言的试用综合来看,与预期相比,百度文心一言还是能够及格的。虽然与搭载 Chat GPT 的 Bing 稍微有一些差距,但差距不是特别大,在中文常识上,文心一言是强于 Bing 的,但在英文内容和逻辑推理上是弱于Bing。
对于“文心一言”的产品表现,百度创始人李彦宏略显底气不足,在发布会刚出场不久,就开始主动降低用户预期。他说道,“要对标 ChatGPT、甚至 GPT-4,门槛还是很高的”、“自己测试还是感觉有很多不完美的地方”。
文心一言确实还不如ChatGPT,但总要客观认识到我们今天所说的 ChatGPT,或者其背后的 GPT-4 语言模型,是一个花了 5 年时间、经历了 4 次迭代,完成了从量变到质变过程。想让文心一言在几个月这么短的时间内实现赶超,几乎是不可能的事情。

不过就目前而言有大语言模型可用比好不好用更重要,只要基本框架打好后面就只需要堆叠丰富的语料和模型校正,好用起来那只是时间问题。在笔者看来虽然目前已经声称要做中国版Chat GPT的很多,比如腾讯的混元AI大模型、京东的Chat JD等等,但真正在AI在内容上有长期大投入还是百度,如果百度都做不出来其他家希望就不大了。
目前来看文心一言不至于让用户很失望,更何况谷歌声势浩大的Bard不一样不尽人意。拿这点批评中美科技差距过大是有点过了。
做大模型,前提是有资金的投入。OpenAI 在 2019 年获得微软 10 亿美金的投入后,又于今年获得了微软 100 亿美金的投资,这让其有了烧钱的资本。业界测算, GPT-3 涉及 1750 亿参数,训练费用约花费 1200 万美元。据国盛证券报告估算, GPT-3 训练一次成本约为 140 万美元,每一次训练任务都耗资巨大。

此外,大模型训练的三要素包括大算力、大数据和大模型。有从业者指出,影响最后训练结果的因素有很多,包括清洗、标注、模型结构设计、训练推理的技术积累等。每一个因素的变化都影响着最后的结果。
过去十几年里百度一直在 AI 方面投入,包括 2019 年推出文心大语言模型。2022 年百度核心研发费用达到 214.16 亿元,占百度核心收入比例达 22.4%。但是,百度和 OpenAI 还有不小差距。李彦宏也直言,无论是哪家公司,都不可能靠突击几个月就能做出这样的大语言模型。因为深度学习、自然语言处理,需要多年的坚持和积累,没法速成。
百度想要做什么
在国内一级市场上,投资机构为了投大模型公司,焦虑难安,行业几乎每天都会有大量认知的迭代。与之相应的是创业热潮,前美团联合创始人王慧文、出门问问 CEO 李志飞、前搜狗 CEO 王小川、前京东高级副总裁周伯文等一批大佬,都在杀向大模型赛道。国内大厂们更是如此。除了百度之外,阿里、腾讯、华为、字节、科大讯飞、商汤都没有放弃大模型之战。大模型耗资巨大不是模型问题,“这是我的问题”,一些从业者这样回答,也彰显了他们急切想要在大模型领域做出一番成绩。
对于百度来说这更是生死之战,百度的营收结构中广告是大头,而广告又是极其依赖搜索的,如果搜索未来被GPT颠覆,那么百度就死无葬身之地了。
2022年全年,百度的营收和净利润均下滑。2022年,百度实现营收1236.75亿元,同比下滑0.66%;归母净利润75.59亿元,同比下滑23.46%。
百度搜索引擎的市场份额已经在加速下滑。市场调研机构StatCounter数据显示,从2022年1月至2023年1月,百度搜索引擎市场份额已经从84.36%下降至65.21%。2022年全年,百度的广告收入在每一个季度均出现同比下滑。数据显示,百度2022年第一季度广告收入同比下滑3.6%、第二季度为10%、第三季度为4%、第四季度为5.2%。如果All in AI不能成为新的增长曲线,百度恐怕连二线大厂的地位都难以守住。

目前来看,百度做大模型并不是毫无优势,技术面上,百度在中文NLP领域,无疑拥有先天优势。首先是对国内技术政策的熟悉,令它比ChatGPT 更能满足国内市场需求。其次,作为最大的中文搜索引擎,百度拥有的高质量数据集及中文数据收集能力,其他家难以比拟。
如果文心一言能够成功,国内流量是可以重新洗牌的。在国内,百度搜索入口的流量长时间被移动互联网其他流量怪兽一点点分流,而如今除了百度的移动生态,大的流量入口基本都掐在腾讯系(微信、QQ)、阿里系(支付宝、淘系)、字节系(抖音)手上;文心一言给了百度一个机会,但凡能有ChatGPT级别的表演,就有可能重新夺回流量。而生成式内容也会丰富内容生态与供给,让百度的搜索业务,重新有其他可能性。
文心一言是百度搜索引擎实现“模糊搜索”到“精准推送”跨越的关键。生成式AI问世之前,搜索引擎以“模糊搜索”为主,用户需要根据在搜索引擎中打入关键字找到需要的内容或链接,而通过文心一言,用户可以通过自然语言交互的方式轻松获得需要的内容或链接,且内容较为精准,即“精准推送”。与此同时,生成式内容也会极大丰富内容生态和内容供给,让成熟的搜索业务和搜索体验焕发生机。相比抖音短视频长时间大量试错来做精准营销,Chat GPT类的精准搜索无疑将会降低大量成本,这对广告商来说非常具有吸引力。当然,百度还要想清楚如何让用户接收到真正有价值的信息,而不仅仅是广告信息,避免再次出现目前搜索引擎广告业务的尴尬。
还有更重要的一点,文心一言的出现会加速百度通过人工智能技术赋能其他产业,从技术本身,基于百度文心大模型已经产生了多款面向 C 端的单点产品,例如产业级搜索系统“文心百中”。
写在最后
有投资人讲中国要做Chat GPT要迈过三座大山,第一是资金山,微软近些年共投入100亿美元,国内要做至少也要10亿美元起步,这点对国内大厂并不是特别困难。第二是工具限制芯片禁售难题,运行AI大模型需要大量GPU芯片——芯片上受的钳制,又影响了做AI大模型。要想跑通一次100亿以上参数量的模型,至少要做到“千卡/月”这个级别,即:用1000张GPU卡,然后训练一个月。
即使不用最先进的英伟达A100,按照一张GPU五万元的均价计算,1000张GPU意味着单月5000万的算力成本,这还没算上算法工程师的工资。百度目前来看并没有受到这个问题困扰,不知道是通过什么替代方案解决的。
第三是AI人才尤其是NLP领域的人才,国内目前还是非常匮乏的,如今世界局势、国内财务自由前景都截然不同,如何让人才“系统性回国”成为非常大的挑战。这点国内大厂要多动点脑筋不要遇事不决一直加薪。
所以想要做大模型做Chat GPT一定要想清楚,不要像元宇宙一样风口过后一地炮灰。
相比大多数企业都在关注GPT在语言上应用,任正非则更关注对工业社会和农业社会的促进,认为未来98%的机会在这两方面。ChatGPT对我们的机会是什么?它会把计算撑大,把管道流量撑大,这样我们的产品就有市场需求。
任正非的话还是有一定道理的,工业对于AI的需求还是容易实现的强需求,对于眼下提升效率是实实在在可见的。变革的时代已经来临,创新已经不是可选项而是必选项。
参考资料:
究竟是ChatGPT还是ChatPPT? 来源:全天候科技
百度“文心一言”就这?来源:深燃
李彦宏,有一点急 来源:商业人物
百度赶鸭子上架 来源:盐财经
百度步谷歌后尘 来源:甲子光年
文心一言发布我们拿到内测账号试了试 来源:知危
为什么会对文心一言发布会失望 来源:刘言飞语
ChatGPT真的是全村人的希望吗 来源:美股研究社
原文标题 : 文心一言,一言难尽
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

