英特尔出手,RISC-V能否乘上AI大模型的快车?
RISC-V,能搭上AI大模型的快车吗? 去年3月份,英特尔在更换了新的CEO后,除了加大力度推进各个现有领域的研究计划外,还将投资的目光看向了固有市场之外的领域,比如正在悄然崛起的RISC-V。&


去年3月份,英特尔在更换了新的CEO后,除了加大力度推进各个现有领域的研究计划外,还将投资的目光看向了固有市场之外的领域,比如正在悄然崛起的RISC-V。
RISC-V对于多数人而言或许都是一个陌生的名词,但是在半导体领域,这个架构正在吸引越来越多的投资和关注,在国内,RISC-V被认为将会是我们弯道超车的机会,如阿里、华为等国内科技巨头都在押注该架构。
实际上,RISC-V已经成为继x86和ARM之后的第三大架构,在全球市场占有一定的份额,当然,如果计算具体的份额占比,那么RISC-V距离x86和ARM还有一段相当遥远的距离。RISC-V的前身RISC,是曾经一度与CISC(x86)并驾齐驱,甚至在服务器等领域的占比还超过了CISC。
图源:wiki
后来的故事大家都已经知道了,在与CISC的战争中,RISC最后成为落败的一方,市场被x86完全占领,随后整个RISC阵营近乎土崩瓦解,不少公司都开始转投其他市场和架构。但是,仍然有人没能忘记RISC,经过多年的整合与调整,被命名为RISC-V的第五代RISC架构正式发布,以此为基础,一个全新的RISC联盟成立,华为等企业目前都是该行业联盟的高级会员。
在RISC联盟的高级会员名单中,英特尔的名字显然是最显眼的,作为曾经以一己之力击败RISC阵营的公司,英特尔主动加入这个联盟总有一种“黄鼠狼给鸡拜年”的感觉。不过,现在看来英特尔并非来搅局的,他们对于RISC-V架构有着自己的独特认知,并且正在将这个架构应用到自己的新产品线中。
图源:RISC-V
“最了解你的,往往是你的敌人”,作为RISC架构曾经以及未来的最大对手,英特尔对RISC架构的研究其实一直没有暂停,所以也让他们有着更多的资本来融入这个新的联盟。在去年3月宣布投资10亿美元进行RISC-V架构的处理器研发后,经过一年半的时间,英特尔正式向外界公布了自己的成果——Piuma。
一核六十六线程
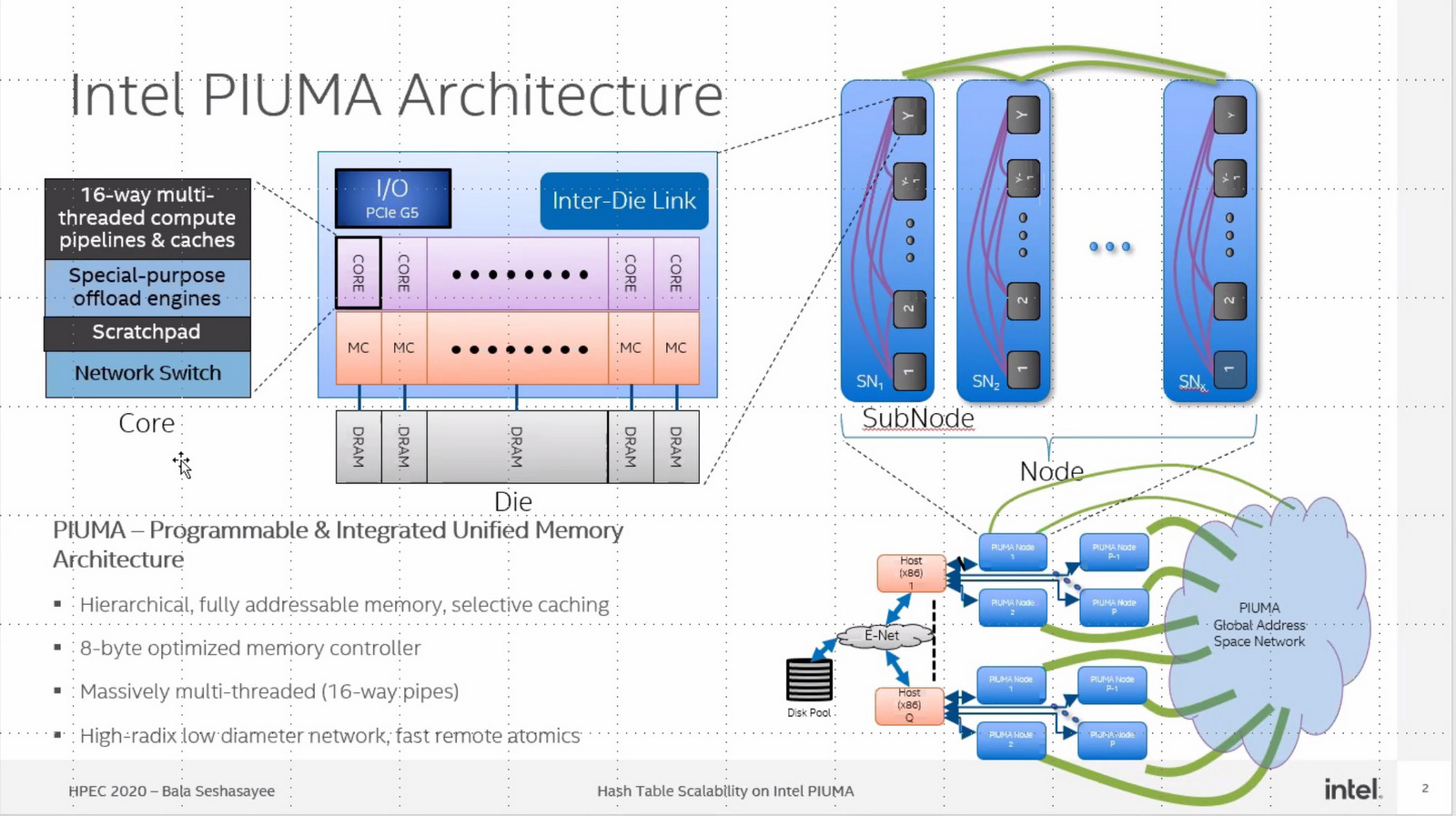
Piuma是一颗特殊的芯片,特殊在于它虽然只有8个核心,但是却有528个线程,单核拥有66个线程,可以说在Piuma面前,单论多线程性能所有的x86芯片都要自愧不如。令人惊讶的线程数背后,还有更恐怖的互联性能,基于特殊设计打造的光学互联芯片,可以让最多131072个Piuma芯片互连,组成一个拥有1680万个核心,1.384亿个线程和512PB共享内存的庞然大物。

图源:intel
在这个规模的处理器阵列面前,传统的x86架构服务器多少有点不够看,在英特尔设计人员的计划里,Piuma能够以传统处理器百倍的速度处理图形分析工作。
不过,Piuma并非一个很新颖的概念,类似的产品此前也诞生过,那么Piuma的特殊之处在哪里呢?特殊在英特尔联合另一家公司,为其打造了一个特殊的光纤互联系统。

图源:intel
在光纤的帮助下,Piuma的互联带宽高达1TB/s,使其能够快速传输数据,而且相较于传统的铜线连接,光纤的延迟要低很多,使得大规模处理器阵列的搭建变得更加轻松。
或许大家都会好奇,传统的x86处理器往往只能做到单核双线程,Piuma是如何做到一核六十六线程的?又是如何在获得充足的多线程性能同时保持一定单线程处理能力的?
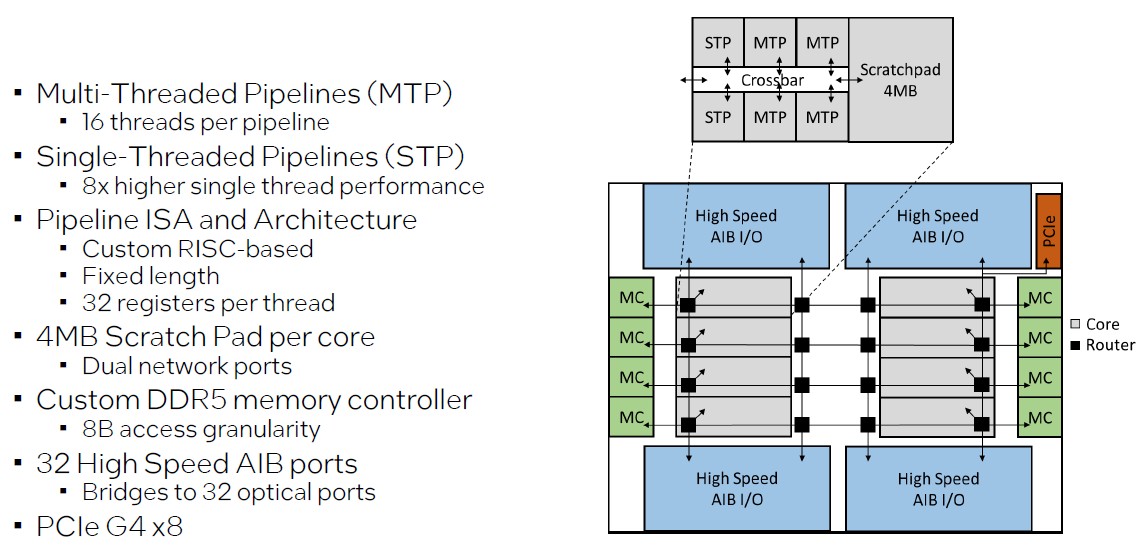
据英特尔介绍,Piuma芯片内设计有六个数据管道,其中四个中内置了16个线程,用于处理零散且多的数据,此外还有两条管道则是单线程设计,线程性能是多线程管道中单条线程的八倍。
图源:intel
有点类似于如今主流x86处理器所采用的大小核设计,只不过两者的顺序有所调换,多线程管道低主频但是多并发,主要负责处理零散任务,当遇到需要更多性能去处理,或是任务集群执行到最后一个任务线程时,处理器会将任务转交给单线程管道,腾出多线程管道空间运行下一个任务。
如此一来就能最大限度地利用各个线程,同时处理大量的零散数据,在遇到偶然的大体量任务时,则可以由高性能的单线程管道进行处理,避免其长时间占用多线程管道。
同时,Piuma的八个内核都有独立的定制DDR5内存控制器,加上精简指令集的帮助,可以让单个最低访问粒度为8字节,远小于普通x86处理器的72字节,意味着Piuma可以更精准的调整内存占用,使得单核超线程的性能不会受制于内存调用。
超大AI集群来了?
传统的x86架构处理器面对这些低负荷却繁多的任务需求,往往难以发挥出单个线程全部的性能,100%的性能却只发挥出10%甚至更少,而且还无法同时对多个任务进行处理,导致性能大幅度空置。
x86架构的优劣势就是如此,虽然该架构可以打造出目前半导体市场中单线程性能最强的处理器,但是面对多而小的任务时,疲弱的多线程设计往往让x86架构处理器无所适从。在这个方面,ARM的表现都远优于x86,随着图形分析等小体量却多次数的任务需求增加,x86架构已经难以应对这些繁复的工作。
但是,x86所不擅长的工作,却恰好是RISC-V的强项,作为一个更精简、高效且开放的架构,RISC-V的设计师可以轻松进行针对性修改,只需要遵循基础的指令集,就可以在此基础上打造出专属的处理器。
简单打个比喻,如果你想打造一辆车,要求是在直线跑道里跑得足够快,x86却依然要求你留下诸如刹车、方向盘、转向装置等各种普通汽车该有的结构。而在RISC-V里,你可以将两个轮子装在一个火箭发动机上,然后宣布这就是你的新车,它或许无法处理多样化的任务,但是却能够跑出最高的直线速度。
RISC-V的优势在于其不同于x86的指令集逻辑,RISC-V可以更高效地处理小体量但多次数的重复任务,通过更精确的任务分配,让每个线程都发挥出最大的性能,同时利用指令集特性快速分配任务线程,提高整个系统的运行效率。
图源:intel
正是基于这个特性,Piuma才能够做到八核五百二十八线程的超级多线程设计,虽然单线程的处理性能远低于x86架构处理器,但是却可以满足多并发的任务需求。随着人工智能等市场需求的增长,阿里的平头哥等企业都在基于RISC-V架构打造对应的多并发处理器,如今已经活跃于各个领域。
随着ChatGPT等AI大模型成为主流趋势,以RISC-V架构打造的处理器更符合AI大模型的实际运行场景,大量的短字节文字信息在常规的数据中心里处理会浪费大量的算力,而在以RISC-V处理器为核心搭建的数据中心里,短字节数据可以被精准分配到各个线程中处理,显著提升处理效率。
不过,想要打造出英特尔计划中的超大处理器集群,还有许多问题需要解决,目前英特尔的Piuma芯片在实际使用时,光纤的带宽只有理论带宽的一半,而且因为光纤发热问题,导致在实际使用中故障频发,需要经常检查和更换光纤连接线,以至于英特尔目前最多也只是将两颗Piuma芯片进行连接而已。

图源:intel
可以说,在光纤材料的难题解决之前,英特尔设想的超大处理器集群都还只停留在PPT上,但是,如果可以解决材料问题,我们将可以创造出更契合AI大模型的服务器集群。
来源:雷科技
原文标题 : 英特尔出手,RISC-V能否乘上AI大模型的快车?
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

