自动机器学习简述
对于机器学习的新用户而言,使用机器学习算法的一个主要的障碍就是算法的性能受许多的设计决策影响。随着深度学习的流行,工程师需要选择相应的神经网络架构,训练过程,正则化方法,超参数等等,所有的这些都对算法的性能有很大的影响。于是深度学习工程师也被戏称为调参工程师。


目录:
一、为什么需要自动机器学习
二、超参数优化 Hyper-parameter Optimization
三、元学习 Meta Learning
四、神经网络架构搜索 Neural Architecture Search
五、自动化特征工程
六、其它自动机器学习工具集
一、为什么需要自动机器学习
对于机器学习的新用户而言,使用机器学习算法的一个主要的障碍就是算法的性能受许多的设计决策影响。随着深度学习的流行,工程师需要选择相应的神经网络架构,训练过程,正则化方法,超参数等等,所有的这些都对算法的性能有很大的影响。于是深度学习工程师也被戏称为调参工程师。
自动机器学习(AutoML)的目标就是使用自动化的数据驱动方式来做出上述的决策。用户只要提供数据,自动机器学习系统自动的决定最佳的方案。领域专家不再需要苦恼于学习各种机器学习的算法。
自动机器学习不光包括大家熟知的算法选择,超参数优化,和神经网络架构搜索,还覆盖机器学习工作流的每一步:
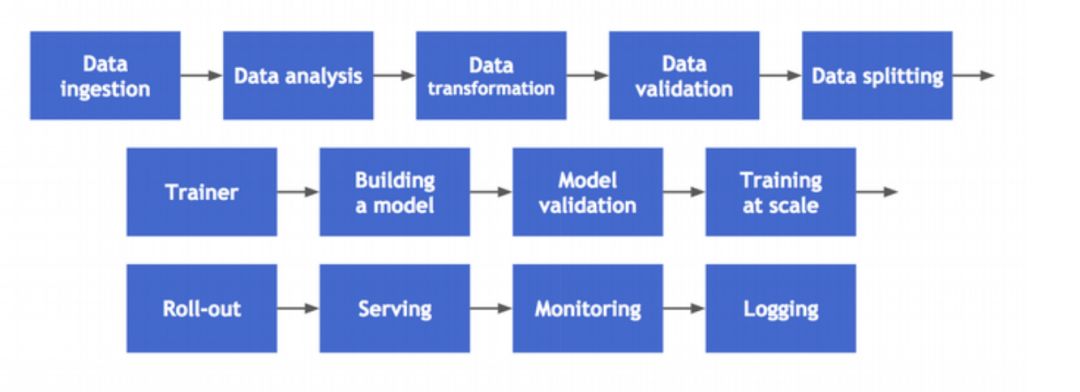
自动准备数据
自动特征选择
自动选择算法
超参数优化
自动流水线/工作流构建
神经网络架构搜索
自动模型选择和集成学习
二、超参数优化
Hyper-parameter Optimization
学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,后者成为超参数。比如,支持向量机里面的C Kernal Gamma;朴素贝叶斯里面的alpha等。
超参数优化有很多方法:
最常见的类型是黑盒优化 (black-box function optimization)。所谓黑盒优化,就是将决策网络当作是一个黑盒来进行优化,仅关心输入和输出,而忽略其内部机制。决策网络通常是可以参数化的,这时候我们进行优化首先要考虑的是收敛性。
以下的几类方法都是属于黑盒优化:
网格搜索 (grid search)
Grid search大家都应该比较熟悉,是一种通过遍历给定的参数组合来优化模型表现的方法。网格搜索的问题是很容易发生维度灾难,优点是很容易并行。
随机搜索 (random search)
随机搜索是利用随机数求极小点而求得函数近似的最优解的方法。
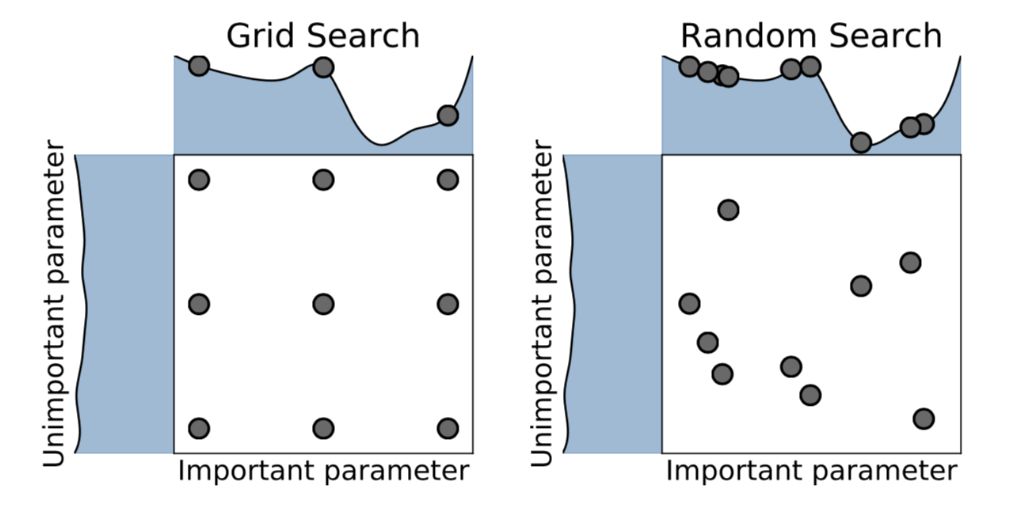
很多时候,随机搜索比网格搜索效果要更好,但是我们可以从上图看出,它们都不能保证找到最优解。
贝叶斯优化
贝叶斯优化是一种迭代的优化算法,包含两个主要的元素,输入数据假设的模型和一个采集函数用来来决定下一步要评估哪一个点。每一步迭代,都使用所有的观测数据fit模型,然后利用激活函数预测模型的概率分布,决定如何利用参数点,权衡是Explaoration还是Exploitation。相对于其它的黑盒优化算法,激活函数的计算量要少很多,这也是为什么贝叶斯优化被认为是更好的超参数调优的算法。
黑盒优化的一些工具:
hyperopt
hyperopt 是一个Python库,可以用来寻找实数,离散值,条件维度等搜索空间的最佳值
Google Vizier
Google的内部的机器学习系统 Google Vizier能够利用迁移学习等技术自动优化其他机器学习系统的超参数
advisor
Google Vizier的开源实现
katib
基于Kubernetes的超参数优化工具
由于优化目标具有不连续、不可导等数学性质,所以一些搜索和非梯度优化算法被用来求解该问题,包括我们上面提到的这些黑盒算法。此类算法通过采样和对采样的评价进行搜索,往往需要大量对采样的评价才能获得比较好的结果。然而,在自动机器学习任务中评价往往通过 k 折交叉验证获得,在大数据集的机器学习任务上,获得一个评价的时间代价巨大。这也影响了优化算法在自动机器学习问题上的效果。所以一些减少评价代价的方法被提出来,其中多保真度优化(multi-fidelity methods)就是其中的一种。这里的技术包括:基于学习曲线来决定是否要提前终止训练,探索-利用困境(exploration exploitation)的多臂老虎机算法 (Multi-armed bandit)等等。
另外还有一些研究是基于梯度下降的优化。
超参数优化面临许多挑战:
对于大规模的模型或者复杂的机器学习流水线而言,需要评估的空间规模非常大
配置空间很复杂
无法或者很难利用损失函数的梯度变化
训练集合的规模太小
很容易过拟合
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

