机器学习根本没有捷径
企业必须明白,好的数据科学在企业实践中需要花费时间,同时还要给相关人员学习和成长的空间,所以这里没有任何捷径可循。
O'Reilly最新的调查数据显示,大数据仍然只是1%,或者15%的企业游戏。大多数的企业(85%)依然没有破解AI和机器学习的密码。仅仅只有15%的“见多识广”的企业在生产过程中运行一些数据模型超过了5年。更重要的是,这些企业更倾向于在一些重要的领域花费时间和精力,比如模型偏差和数据隐私。相对而言,那些还属于初学者之列的企业仍然还在努力尝试着寻找启动按钮。
不幸的是,对于那些希望通过自动快捷方式比如Google的AutoML或者通过聘请咨询公司缩小数据科学差距的企业,我们给出的答案是:实现数据科学的确需要花费时间,而且没有捷径可循。
聪明的企业专注于深层次数据
首先,值得注意的是,O'Reilly的调查数据来自于其自选的一群人:那些曾经参加过O'Reilly活动的,或者参加过该公司在线研讨会或通过其他途径与之有接触的人。这些人群对于数据科学都有前瞻性的兴趣,即使(按照调查数据的显示)他们中的大部分人并没有从事太多的相关工作。对于那些沉浸在大数据体验中的人来说,最好的客户群体就是那些被称为“见多识广”的企业,它们在生产过程中使用的数据模型已经运行了5年以上。
从调查上可以发现一个有趣的现象,那就是这些企业是怎样称呼他们自己的数据专家的。具有丰富数据经验的企业称之为数据科学家。而那些思维尚停留在上世纪90年代“数据挖掘”模式的企业则更倾向于称其为“数据分析师”。如下图所示。
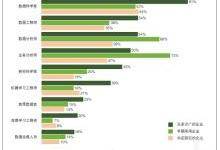
调查发现,无论企业选择如何称呼他们的数据专家,企业在AI和机器学习方面的经验越丰富,他们就越有可能依靠内部数据科学团队建立模型,如下图所示。
几乎没人关注云机器学习服务(至少现在还没有)。那些只有2年以下生产经验的企业倾向于依赖外部的顾问来搭建机器学习模型。对于这样的企业而言,这种感觉就像一种不用投入人力而享受数据科学收益的机会,但这是一个非常愚蠢的方法。
企业的数据越复杂,其数据科学团队就越能建立模型,并评估项目成功的关键指标。纵观所有的企业,产品经理对于项目成功的作用是36%,管理团队的数据是29%,数据科学团队的贡献是21%。
对于那些经验丰富的企业来说,产品经理的作用依然占到34%,数据科学团队27%,几乎与管理团队(28%)相同。
对那些缺乏经验的企业而言,管理团队占到31%,数据科学团队占比较少(16%)。这不是个问题,事实是这些数据科学团队最适合计算出如何使用数据并衡量其成功。
太多时候,是外行指导外行
这种依赖管理层来推动数据科学的想法引起了人们的注意。调查显示,不少高管自称是数据驱动的,但却无视了数据其实并不支持那些靠直觉驱使的决策(62%的人承认这么做)。
那些缺乏大数据悟性的企业似乎愿意口头提供数据,但他们根本不明白有效数据科学的细微差别。他们缺乏必备的经验来确保可以获得有意义的、无偏见的数据洞察力。
关于如何理解机器学习模型,以及如何相信该模型所导致的结果,更多有成熟经验的企业显然掌握了Gartner博客网络中的一位博主Andrew White的评估方法:
AI的创新之处就在于AI可以重新定义新的基线,换句话说就是那些我们认为太过复杂的东西和非常规的东西,目前都可以利用AI来实现。和之前的技术相比,AI应该可以处理更加复杂而且具有认知能力的工作。
这个新的现实只有在AI自动处理的结果是合理的时候才有意义。如果这个新奇的工具所得出的决策和结果让人类无法理解,那人们就会放弃这个工具。因此在某种程度上,能否理解AI所做出的决策也非常重要。
然而,理解决策和理解算法如何工作是两回事。人是可以掌握输入、选择、权重以及结果的原理的,而即便算法能够在一定程度上将所有这些结合到一起,但我们依然无法证明这一进程。如果结果和输入之间的差距太大,那么人对算法的信任就很有可能会丧失——这是人的天性。
想要达到这种理解水平是无法通过花钱雇佣咨询顾问能实现的。云端也不是现成的。运用工具比如Google的AutoML可以“使得那些具有有限机器学习专长经验的开发者能训练针对其业务需求的高质量模型。”这听起来非常好,但是想要从数据科学中受益需要有数据科学的经验。这不仅仅是调整模型的问题,更需要知道如何实现,这需要大量的试错经验。
另外,从事数据科学需要有人文的心态,再次强调,需要经验。没有捷径可循。实际上,这意味着那些早期投资于数据科学的企业应该发现自己领先于那些没有竞争优势的同行——这种差异很可能会持续下去。
对于那些希望迎头赶上的企业,Gartner分析师Svetlana Sicular最为经典的忠告仍然在耳边回响:“企业应该在内部多看看。其实内部已经有人比那些神秘的数据科学家更了解自己的数据。”只要企业明白要在企业完成好的数据科学需要花费时间,并且给予其人员学习和成长的空间,他们就不再需要寻找捷径。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

