Scrapy爬虫项目运行和调试(上)
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了。在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫。
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了。在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫。
一、建立main.py文件,直接在Pycharm下进行调试
很多时候我们在使用Scrapy爬虫框架的时候,如果想运行Scrapy爬虫项目的话,一般都会想着去命令行中直接执行命令“scrapy crawl crawler_name”,其中crawler_name指的是爬虫的名字,在一开始创建Scrapy爬虫模板的时候就指定了的,而且在该爬虫项目中具有唯一性。但是每次跑到命令行下去执行,看交互的结果,有时候并不是很清晰,所以这里介绍一种方法,可以帮助大家提高开发效率,尤其是调试的时候更是显得方便。
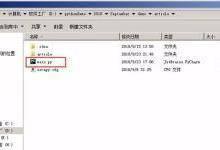
在与爬虫项目的scrapy.cfg文件同级目录下建立一个main.py文件,用于控制整个爬虫项目的执行。
在该文件夹中写入的代码见下图。其中execute函数是内嵌在scrapy中的,调用这个函数可以直接调用该Scrapy工程项目的爬虫脚本,这个函数的执行需要在爬虫项目的父目录下进行。而第7行代码的意思就是获取当前py文件的父目录,省去我们直接复制路径的精力和时间,同时也方便我们将该项目放到其他的平台上去运行,不会报路径的错误。execute函数里边的参数其实就是将Scrapy爬虫执行命令拆分,然后分别以一个字符的方式放到了一个数组中。
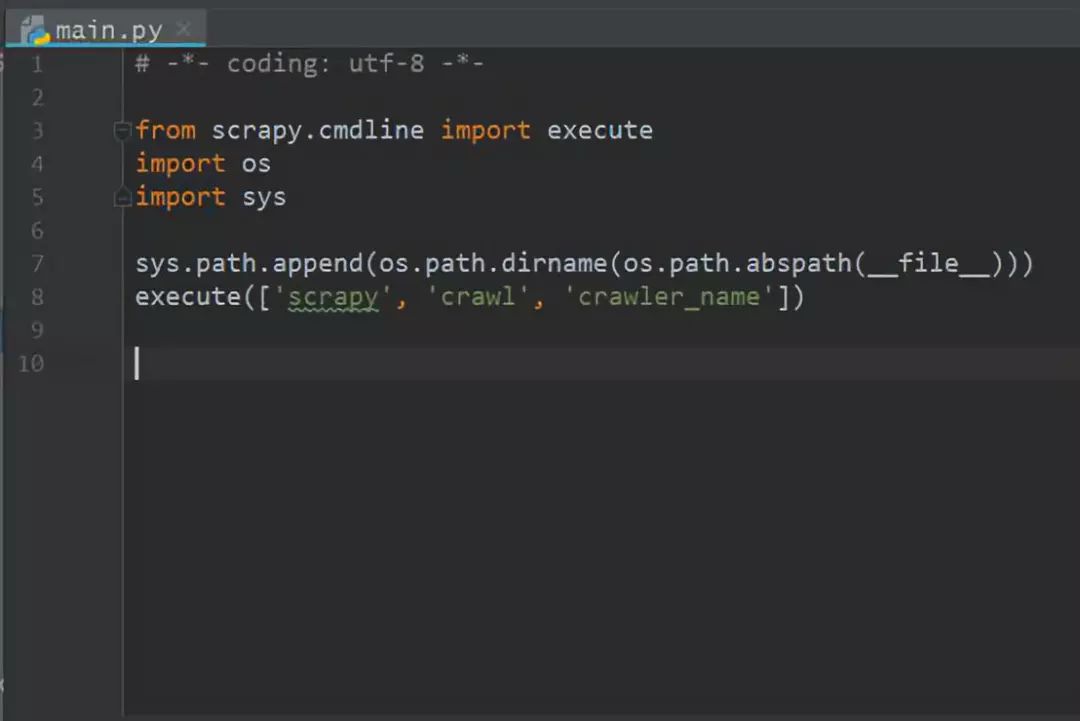
之后我们直接运行这个main.py文件便可以调用Scrapy爬虫程序了。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

