多传感器数据融合的自动驾驶汽车
本文整理了多传感器数据融合(Multi-Sensor Data Fusion,MSDF)的要点和基本方法。
本文整理了多传感器数据融合(Multi-Sensor Data Fusion,MSDF)的要点和基本方法。介绍了Harmonize、Reconcile、Integrate、Synthesize之间的区别和对应的解决方案。文章主要围绕什么是MSDF;为什么要MSDF和如何进行MSDF展开,希望给对自动驾驶感兴趣的小伙伴,提供一些参考。
许多人工智能系统的一个关键要素是具有多传感器数据融合(Multi-Sensor Data Fusion,MSDF)的能力。在人工智能系统处于一个特定的环境时,MSDF需要对周围环境数据进行Harmonize;Reconcile;Integrate;Synthesize。简单来说,传感器相当于眼睛耳朵等输入感官,而人工智能系统需要以某种方式解释这些输入感官收集回来的信息,使其成为在现实世界可以被解释且有价值的信息。在驾驶汽车时,多目标跟踪(Multi-Target Tracking,MTT)也是非常重要的课题——设想在市中心开车,周围都是行人和车辆,人类驾驶员要准确的识别并躲避他们,自动驾驶汽车也是。所以,这要求传感器融合具备一个必须的性质——实时性,就像人类每时每刻都在大脑中进行传感器融合一样。尽管人类不会公开地明确地将想法付诸于行动,但是这些“传感器融合”过程都是自然发生的。
自动驾驶的MSDF
首先,需要明确一个老生常谈的概念——SAE对于自动驾驶等级的划分。SAE给自动驾驶汽车划分为5个等级,对于L5以下的自动驾驶汽车,要求必须有一个人类驾驶员(安全员)在场。目前,人工智能和人类驾驶员共同承担驾驶任务,而人类驾驶员被认定为汽车行为的责任人。
回到MSDF的话题,下图展示了人工智能自动驾驶汽车如何进行MSDF的一些关键要素。
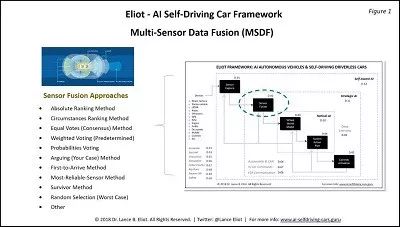
上图指出了MSDF面临的主要挑战是如何将收集来的大量数据集中在一起,并做出正确决策。因为如果MSDF出错,意味着下游阶段要么没有必要的信息,要是使用了错误的信息做出了错误的决策。可以看到,一般来说,自动驾驶汽车会通过安装在车身周围的摄像头收集视觉数据,也会通过雷达(激光雷达、毫米波雷达等)来收集诸如周围物体运动速度的数据,但是这些数据是从不同角度来描述现实世界的同一样或不同样的物体。所以,使用什么类型的传感器,怎么融合传感器收集回来的数据,使用多少传感器才能实现基于数据的对客观世界的描述呢?通常来说,使用越多的传感器,对计算能力的要求就越高,这意味着自动驾驶汽车必须搭载更多的计算机处理器和内存,这也会增加汽车的重量,需要更多的功率,还会产生更多的热量。诸如此类的缺点还有很多。
多传感器融合(MSDF)的四个关键方法
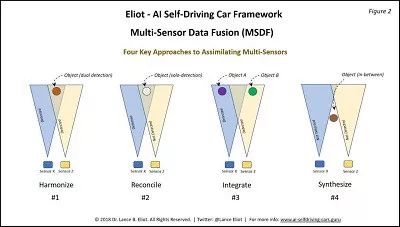
图 Harmonize;Reconcile;Integrate;Synthesize的区别
Harmonize:
假设有两种不同的传感器,称它们为传感器X和传感器Z。它们都能够感知自动驾驶汽车的外部世界。在现实世界中存在一个物体,这个物体可能是人,也可能是车,甚至是一条狗,传感器X和传感器Z都能够检测到这个物体。这就意味着传感器对这个物体进行了双重检测,这种双重检测意味着两种不同类型的传感器都有关于该物体的数据报告,对于该物体有两个维度不同地认知。假设,传感器X表示该物体高6英尺,宽2英尺;传感器Z表示该物体以每秒3英尺的速度正朝着自动驾驶车辆方向移动。结合两个传感器采集到的数据,就可以得出一条相对准确的信息:有一个高约6英尺,宽2英尺的物体正在以每秒钟3英尺的速度移动。假设这两自动驾驶汽车上只安装了X传感器,那么就无法得知该物体的大小;若Z传感器坏了,那么就只有物体的大小信息,无法检测该物体的运动状态。这也就是最近业内广泛讨论的“在自动驾驶汽车上应该安装哪些传感器”的问题。
此前,特斯拉埃隆·马斯克(Elon Musk)旗帜鲜明地声称,特斯拉不会安装激光雷达。尽管马斯克自己也认为,L5自动驾驶不会通过激光雷达来实现这个想法最终可能被验证为错误的,这依旧没有改变马斯克的决定。一些反对的声音称,不配备激光雷达的特斯拉,无法通过其他的传感器获取如同激光雷达效果相同的感官输入,也无法提供补偿和三角测量。但是另一些支持者认为,激光雷达不值得话费如此高昂的费用成本,不值得为其增大计算能力,也不值得为其增加认知时间。
Reconcile:
在同一个视场(Field of View,FOV)内,假设传感器X探测到一个物体,而传感器Z没有探测到。注意,这与物体完全在传感器Z的FOV之外的情况有很大的不。一方面,系统会认为传感器X是正确的,Z是错误的,可能是因为Z有故障,或者有模糊探测,或者是其他的一些什么原因。另一个方面,也许传感器X是错误的,X可能是报告了一个“幽灵”(实际上并不存在的东西),而传感器Z报告那里没有东西是正确的。
Integrate:
假设我们有两个物体a和b,分别在传感器X和传感器Z的视场FOV内(a在X视场内,b在Z视场内)。也就是说,Z无法直接检测到a,X也无法直接检测到b。目前,想要实现的效果是,能否将X和Z的报告整合在一起,让它们在各自的视场内探测物体同时,判断是否为X视场中的物体正在向Z视场移动,预先提醒Z将有物体进入探测区域。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

