基于word embedding对IMDB影评数据二分类
最近做了很多和文本相关的项目,但不管是要计算文本相似度,还是对文本进行分类或者聚类,都免不了要将文本转换成词向量(wordvec),然后再进行一系列的数学操作。所以这可以说是整个流程中最重要的一项,有点类似于数据分析中的特征工程

最近做了很多和文本相关的项目,但不管是要计算文本相似度,还是对文本进行分类或者聚类,都免不了要将文本转换成词向量(wordvec),然后再进行一系列的数学操作。所以这可以说是整个流程中最重要的一项,有点类似于数据分析中的特征工程。
/ 01 / 词向量
转换成词向量本人用的最多的是将文本切割为word,这一过程被称之为token,而将文本转化为token这一过程称之为tokenization。而token有两种常见的编码形式,一种是one-hot,另一种是词嵌入(word-embedding)。这两种方式都是将二维的文本转换成三维的向量集合。
/ 02 / one-hot编码
关于One-hot在这也提一嘴。比如这样两句话:The cat sat on the mat/The dog ate my homework。它将所有出现过的词语存入一个列表a(
['The', 'cat', 'sat', 'on', 'the', 'mat.', 'The', 'dog', 'ate', 'my', 'homework.']
),每一个单词对应一个索引,比如The对映1,cat对映2,依次类推,最后将每个单词替换为索引处为1,其余为0的一组长度为11(len(a)=11)的向量。
samples = ['The cat sat on the mat.', 'The dog ate my homework.']# 10# 定义一个集合,得到{'The': 1, 'cat': 2, 'sat': 3, 'on': 4, 'the': 5, 'mat.': 6, 'dog': 7, 'ate': 8, 'my': 9, 'homework.': 10},也就是筛选出这个句子中对应的了哪些词,然后并赋予索引值,其实就是个词库token_index = {}for sample in samples: for word in sample.split(): if word not in token_index: token_index[word] = len(token_index) + 1
# 限制了读取的句子的长度,一句话最长10个词max_length = 10results = np.zeros(shape=(len(samples), max_length, max(token_index.values()) + 1))
# print(results) 2, 10, 11for i, sample in enumerate(samples): for j, word in list(enumerate(sample.split()))[:max_length]: index = token_index.get(word) results[i, j, index] = 1.print(results)[[[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
[[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]]
但是这样编码方式得到的向量集是二进制,且非常稀疏且维度巨大的,同时也没有保留前后文的联系,脱离了整个语境。
/ 03 / word-embedding编码
第二种编码方式word-embedding完全解决了上述这些缺点,它会给每个单词分配一个固定长度的向量(有50维的,有100维的,也有300维的),并且根据两个向量的余弦相似度可以得到两个词的相关性。
有两种业界常用的WordEmbedding生成方式,Continuous Bag Of Words (CBOW)方法和n-gram方法,我们采用n-gram方法。它是将一个句子按照固定长度分割为许多batch,从前往后每次选长度为skip_window的窗口(可以设置为3,也可以设置为5)。对于窗口中的5个单词,以中间(也就是第三个单词)为中心,生成两队source-target单词对,source为中心单词,target为窗口中除中心词以外的其余单词。栗子如下。
The cat sat on the matskip_window=5source ---> target第一个窗口The cat sat on thesat ---> catsat ---> the第二个窗口cat sat on the maton ---> caton ---> mat
然后得到的这些source-target作为分别作为输入和输出,具体的训练方法可以参照这篇博客。但是不一般不建议大家自己训练嵌入层,因为计算量实在是太大,
下面用到的嵌入层是用已经训练好的GLoVE数据集。
/ 04 / 导入数据
先来看下要做分类的数据集。
两个文件夹neg和pos分别存放差评和好评。一个txt对应一条评论。分别读入dataset中,其中neg定为0,pos定为1,对应存入labels中。
def read_data(self): dataset = [] labels = [] def eachFile(filepath,lab): pathDir = os.listdir(filepath) for allDir in pathDir: with open(filepath + '/' + allDir) as f: try: dataset.append(f.read()) labels.append(lab) except UnicodeDecodeError: pass filepath = ['C:/Users/伊雅/PycharmProjects/untitled/venv/share/nlp/aclImdb/aclImdb/test/neg','C:/Users/伊雅/PycharmProjects/untitled/venv/share/nlp/aclImdb/aclImdb/test/pos'] eachFile(filepath[0],0) eachFile(filepath[1], 1) return dataset,labels
/ 05 / 数据预处理
第二步就是得到按照频率大小排序的词语编号,并将每一个句子中所有单词替换为对应的编号。举个栗子:
somestr = ['ha ha gua angry','howa ha gua excited']可以得到下面的字典,key为单词,value为单词的频数{'ha':3,"gua":2,"angry":1,"howa":1,"excited":1}根据每个单词的频数将单词从大到小排列得到一个list['ha','gua','angry','howa','excited']第一个单词ha赋予编号1,gua赋予编号2,angry赋予编号3,...依次类推,这样可以得到所有单词的编号,word_indexword_index={'ha':1,'gua':2,'angry':3,'howa':4,'excited':5}在现实计算中,由于出现的单词基数过大,所以会设定一个max_words=10000,表示取list的前10000个单词。最终可以将['ha ha gua angry','howa ha gua excited']转换为词向量['ha ha gua angry'] ---> [1,1,2,3]['howa ha gua excited'] ---> [4,1,2,5]
文本预处理的基本流程就如上所示。接下来就是使用keras的Tokenizer把导入的数据进行批量处理,转换为对应的词向量,并随机打乱顺序得到训练样本和测试样本。
def tokennize_data(self): # 导入数据集 dataset,labels=self.read_data() # 构造一个分词器,num_words默认是None处理所有字词,但是如果设置成一个整数,那么最后返回的是最常见的、出现频率最高的num_words个字词。 tokenizer = Tokenizer(num_words=self.max_words) # 类方法之一,texts为将要训练的文本列表 tokenizer.fit_on_texts(texts=dataset) # 将texts所有句子所有单词变为word_index对应的数字 sequences = tokenizer.texts_to_sequences(texts=dataset) # 将所有的单词从大到小排列list,构建一个key为单词,value为单词对应在list的位置 word_index = tokenizer.word_index # print(word_index) print('Found %s unique tokens.' % len(word_index)) # 序列填充,如果向量长度超过maxlen则保留前maxlen,如果没有maxlen这么长,就用0填充 data = pad_sequences(sequences, maxlen=self.max_len) # asarray和array不同点是当labels发生变化时,asarray(labels)跟着发生变化,但array(labels)不变 labels = np.asarray(labels) print('Shape of data tensor:', data.shape) print('Shape of label tensor:', labels.shape) indices = np.arange(data.shape[0]) # 将indices的顺序打乱 np.random.shuffle(indices) data = data[indices] labels = labels[indices] # 生成训练样本和测试样本 # 训练样本数据集x_train,训练样本类标签y_train x_train = data[:self.training_samples] y_train = labels[:self.training_samples] x_val = data[self.training_samples: self.training_samples + self.validation_samples] y_val = labels[self.training_samples: self.training_samples + self.validation_samples] return x_train, y_train, x_val, y_val, word_index
/ 06 / 构造embedding矩阵
下一步就是把word_index的前10000个单词转化成对应的特征向量,构成embedding_matrix嵌入层矩阵。下图为glove数据集,第一个字符为单词,第二到五十一为这个单词对应的1*50维的向量。

因为glove数据集中的单词是成千上万的,我这里选的是50维的(一个单词对应一个1*50的向量),但出现在word_index前10000中的单词是有限的,因此要构造一个10000*50维的嵌入层矩阵。
def parse_word_embedding(self,word_index): glove_dir = 'C:/Users/伊雅/AppData/Local/Temp/baiduyunguanjia/onlinedit/cache/cddea73f1336cbed6744e3e9a91ad7f3/glove.6B.50d.txt' embeddings_index = {} # 将glove中的单词存为key,对应的向量存为value f = open(glove_dir, encoding='UTF-8') for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype='float32') embeddings_index[word] = coefs f.close() print('Found %s word vectors.' % len(embeddings_index)) # embedding_matrix为训练好的嵌入层矩阵 embedding_matrix = np.zeros((self.max_words, self.embedding_dim)) for word, i in word_index.items(): # 取前10000个 if i < self.max_words: embedding_vector = embeddings_index.get(word) # embedding_matrix[i]为对应word的向量 if embedding_vector is not None: embedding_matrix[i] = embedding_vector return embedding_matrix
/ 07 / 基于keras构建二分类模型
一切准备好以后就可以开始建模了。这里使用的是keras库。这里要说的是嵌入层,它的shape是(N,100,50)N是样本数,100是max_len,因为在进行向量计算时,纬度必须保持一致,因为每个句子都变为长度为100的向量。如果这个句子只有3个单词,则前面97个为0,98,99,100分别为三个单词对应的编号。在文本预处理部分已经将所有句子填充为长度100的向量。50是指每一个单词用1*50的向量替换,一个句子从1*100维变成了1*100*50的三维向量。
def model(self): # 创建模型,序贯模型 model = Sequential() model.add(Embedding(self.max_words, self.embedding_dim, input_length=self.max_len)) #output= shape=(?,100,50).input=shape=(?,100) print(model.layers[0].get_weights()) model.add(Flatten()) # input=shape=(?,100,50),output=(?,5000) # (32, 10, 64) #32句话,每句话10个单词,每个单词有64维的词向量 print(model.layers[0].get_weights()) # Dense表示连接层,32是units,是输出纬度,activation表示激活函数,relu表示平均函数,sigmoid是正交矩阵 model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.summary() # 将GLOVE加载到模型中 x_train, y_train, x_val, y_val, word_index = self.tokennize_data() # 嵌入层: # input_dim:字典长度,即输入数据最大下标+1 # output_dim:全连接嵌入的维度 # input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。 embedding_matrix = self.parse_word_embedding(word_index) print(embedding_matrix) model.layers[0].set_weights([embedding_matrix]) # 权重矩阵固定,不在需要自我训练 model.layers[0].trainable = False#模型的编译,优化器,可以是现成的优化器如rmsprop,binary_crossentropy是交叉熵损失函数,一般用于二分类,metrics=['acc']评估模型在训练和测试时的网络性能的指标, model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc']) # epochs表示循环次数,batch_size表示每一次循环使用多少数据量 history = model.fit(x_train, y_train,epochs=10,batch_size=512,validation_data=(x_val, y_val)) result=model.evaluate(x_val, y_val, verbose=1) print('test score is',result[0]) print('test accuracy is ', result[1]) history_dict = history.history return history_dict
/ 08 / 模型精度评价
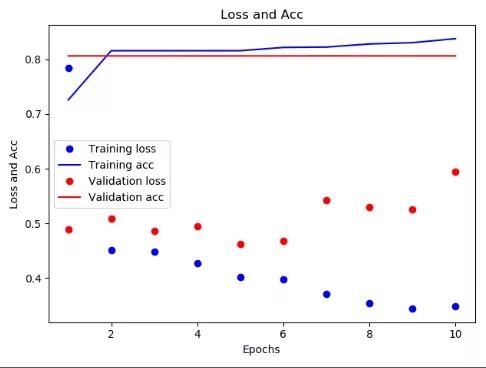
得到的结果如下。Loss为损失,acc为准确率,val_loss是验证集损失,val_acc为验证集准确率。一共进行了10轮,由于数据量过大,为了提高效率,每一次只使用512个样本量进行计算。
Train on 3000 samples, validate on 12000 samplesEpoch 1/10
512/3000 [====>.........................] - ETA: 8s - loss: 0.5417 - acc: 0.76562048/3000 [===================>..........] - ETA: 0s - loss: 1.1453 - acc: 0.71243000/3000 [==============================] - 2s 692us/step - loss: 0.9635 - acc: 0.7367 - val_loss: 0.4777 - val_acc: 0.8094Epoch 2/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.4469 - acc: 0.81252560/3000 [========================>.....] - ETA: 0s - loss: 0.4571 - acc: 0.80593000/3000 [==============================] - 0s 111us/step - loss: 0.4675 - acc: 0.8043 - val_loss: 0.5002 - val_acc: 0.8094Epoch 3/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.5139 - acc: 0.77342048/3000 [===================>..........] - ETA: 0s - loss: 0.4773 - acc: 0.80473000/3000 [==============================] - 0s 121us/step - loss: 0.4619 - acc: 0.8060 - val_loss: 0.6160 - val_acc: 0.8094Epoch 4/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.4900 - acc: 0.82622560/3000 [========================>.....] - ETA: 0s - loss: 0.4332 - acc: 0.80863000/3000 [==============================] - 0s 115us/step - loss: 0.4307 - acc: 0.8070 - val_loss: 0.4597 - val_acc: 0.8107Epoch 5/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.3809 - acc: 0.83402048/3000 [===================>..........] - ETA: 0s - loss: 0.4643 - acc: 0.79053000/3000 [==============================] - 0s 121us/step - loss: 0.4444 - acc: 0.7943 - val_loss: 0.4704 - val_acc: 0.8094Epoch 6/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.4009 - acc: 0.79882048/3000 [===================>..........] - ETA: 0s - loss: 0.3815 - acc: 0.80133000/3000 [==============================] - 0s 123us/step - loss: 0.3935 - acc: 0.8063 - val_loss: 0.4878 - val_acc: 0.8112Epoch 7/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.4118 - acc: 0.80272560/3000 [========================>.....] - ETA: 0s - loss: 0.3754 - acc: 0.82663000/3000 [==============================] - 0s 124us/step - loss: 0.3882 - acc: 0.8247 - val_loss: 0.4903 - val_acc: 0.8099Epoch 8/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.4186 - acc: 0.82622048/3000 [===================>..........] - ETA: 0s - loss: 0.3527 - acc: 0.84083000/3000 [==============================] - 0s 120us/step - loss: 0.3526 - acc: 0.8393 - val_loss: 0.4804 - val_acc: 0.7933Epoch 9/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.3581 - acc: 0.90232048/3000 [===================>..........] - ETA: 0s - loss: 0.3764 - acc: 0.85603000/3000 [==============================] - 0s 115us/step - loss: 0.3583 - acc: 0.8573 - val_loss: 0.4496 - val_acc: 0.8108Epoch 10/10
512/3000 [====>.........................] - ETA: 0s - loss: 0.3099 - acc: 0.85352560/3000 [========================>.....] - ETA: 0s - loss: 0.3728 - acc: 0.85823000/3000 [==============================] - 0s 114us/step - loss: 0.3630 - acc: 0.8563 - val_loss: 0.4508 - val_acc: 0.8093
test score is 0.45084257221221924test accuracy is 0.8093333333333333
得到的损失-准确曲线如下图所示。
/ 09 / 终章
本文所有代码已全部上次GitHub,感兴趣的朋友可以给个小星星?fork噢。
数据集自行从百度云下载。
------------------- End -------------------
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

