音乐+科技,在AI时代能擦出新的火花吗?
人工智能和音乐的融合,是AI技术在音乐创作领域的新突破,这不再是音乐专业人士的固有权力,让对音乐感兴趣的人也能通过音乐AI创作专属于自己的歌曲。音乐与人工智能技术的融合不仅对现有的音乐产业造成了一定影响,打破了作曲家进行音乐创作的固定模式,带动整个音乐产业的快速发展



人工智能和音乐的融合,是AI技术在音乐创作领域的新突破,这不再是音乐专业人士的固有权力,让对音乐感兴趣的人也能通过音乐AI创作专属于自己的歌曲。音乐与人工智能技术的融合不仅对现有的音乐产业造成了一定影响,打破了作曲家进行音乐创作的固定模式,带动整个音乐产业的快速发展。

打破传统的流动音乐
二十年前,我们听音乐是打开电视或收音机,聆听DJ们为我们播放的歌,或者购买磁带与CD自己播放,这样的方式却总让我们受到限制,无法随时随地尽情享受喜欢的音乐。 而如今,我们面对的是浩如烟海的网络云端音乐曲库,随时随地便可链接我们想听的歌。这便是科技发展给音乐体验带来的第一重改变:打破壁垒。
能够自由流动的音乐为我们创造了无限可能,方便快捷的私人歌单让我们每个人都成了DJ,甚至对不同歌曲的串联与编辑,成了我们书写故事的新方法。当音乐不再有限制,能够在时空之间自由流动,才给我们创造了足够充分的音乐享受。

AI改变创造音乐方式
AI音乐简单理解就是人工智能创作音乐。早在1951年,英国计算机科学家艾伦·图灵就曾使用机器录制计算机生成的音乐,当时的计算机几乎占满整个实验室。人工智能作曲的原理,是它先建立一个数据库,它有很多首歌然后他们开发出来一个程序,歌曲主要是由旋律和和声来构成的,而这个程序则可以在非常多的歌曲里面随意截取其中的某一段音频,它可以把这个旋律和和声结构出来。自那以来,由AI或使用AI创作的音乐延续到今天。
AI的模式是从分析不同乐曲创作时的数据开始,通过强化学习,相关算法可以学习哪些特征和模式能够创造出令人愉快的音乐,或者模仿某种类型的音乐,或者是通过以独特的方式组合元素来创作新的数字音乐。

算法作曲的商业应用
算法源自古代波斯人对阿拉伯数字游戏的称谓,意思是阿拉伯数字的运算法则。对音乐创作而言,广义的算法指音乐要素及组织逻辑、运算法则、结构模型或规则系统,以及将算法思维与作曲思维中最小的决策单位对应后所形成的作曲技法模型与系列,也就是音乐的数理逻辑。这种对应关系一言以蔽之:凡作曲即有算法。如旋律的动机展开、重复、模进、转调、逆行、倒影、随机、模糊、音程或节奏压扩,和声与对位中的音高纵横向排列组合、不谐和度、紧张度解决,配器中的音色组合,曲式中的并行、对置、对称、回旋、奏鸣等等原则都属于常规的作曲技法,都可以被描述为单一或组合的算法。
狭义上的算法作曲,可以简单地形容为计算机自动作曲系统,在人适当的介入下,计算机就能自动生成音乐。所谓适当指的是,与传统创作中作曲家对所创作的音乐作品中的变量拥有主导控制权不同,在自动作曲系统中,人只是规则设定者与反馈调试者。
很多科技公司正投资于AI创造或协助音乐人创作音乐的未来。例如:
①A.I. Duet - Google Magenta项目:Magenta项目同时也是谷歌大脑(Google Brain)的项目分支之一,Magenta 项目一直在探索机器学习在艺术创作中的作用,利用算法来生成歌曲、图像,让艺术家利用这些技术来启发自己的创作。
② DeepBach项目,音乐界的 AlphaGo:DeepBach项目是一个开源的AI作曲项目,开发人员用巴赫创作的352部作品目来训练DeepBach,在预定义音域内,将这些作品变调,创作出了2503首作品。其中,80%用来训练DeepBach,而剩余20%用来验证训练成果。
③蜜蜂云科技音乐AI智能硬件:蜜蜂云科技音乐AI智能硬件,一款针对全民用户的音乐智能创作硬件。用户只需对音乐AI智能硬件下达歌曲类型指令,即可快速生成各种不同风格的创作曲目;利用音乐分拣技术还能将不同音种分离出来,能将其用不同的乐器弹奏出来例如:钢琴弹奏转吉他弹奏,还能转化生成对应乐器的曲谱等。

AI智能歌唱模式演进
唱歌的三大要素是发音、节拍和音调,AI学会一首歌有两种方法一是学习人唱的歌,听人类歌手的原唱,这也是人类更喜欢的学唱歌方式,但机器通过这种方式来学唱歌需要需要判断曲调,更容易有误差。
二是看着曲谱学这首歌,直接从曲谱生成唱出来的音频文件,这对人类来说比较复杂,但对机器来说更容易。之后,合成一段歌声也有两种方法。一种是单元拼接法,把单个的声音找出来拼在一起。
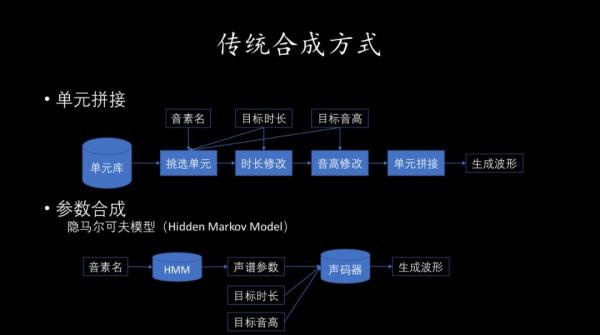
如果不考虑音调,声母和韵母凑成的单音节有400个左右,提前录制好这400个音节的不同版本,长的短的、高音低音,凑成单元库,再根据具体歌曲中的发音需求从单元库中选取单元拼接起来。不过,这种方法可能不太流畅,会有一个字一个字蹦的感觉,出来的曲调过渡上会让人感觉生硬。
另一种是参数合成法,用隐马尔科夫模型来做。这种方法是从大量录音数据中提取包括能量谱、时长、音高在内的声学参数,通过声学参数、声码器把音频的波形重构出来。这种方法得出的结果有丰富的变化,可以创造出从来不存在的声音,但是在声码器重构的过程中可能会引起音质损失。
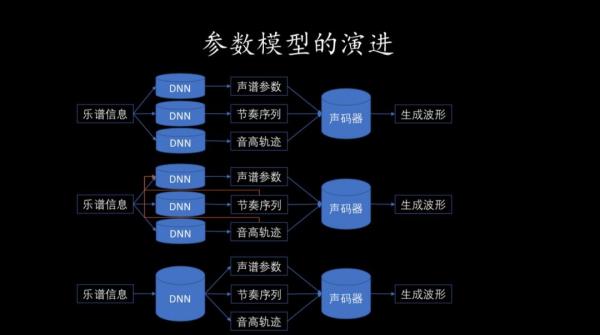
而微软小冰的唱歌技能就是基于参数合成法,从乐谱中采集发音、节拍、音调三大要素,分别对声谱参数、节奏序列、音高轨迹用三个模型分别建模,用神经网络预测参数,之后把这些参数通过声码器生成波形。之后的迭代中,也借助了模块化的方式,并将三个模型合为一个,这样合成歌声的自然度和流畅度就得以提升了。
就像其他科学技术一样,AI作曲的发展带来的直观益处之一就是作曲门槛的降低和作曲的大众化。当普通个人用户能够借助一款音乐软件创作歌曲时,我们能够想象到那是一个与现在十分不同的时代。专业化作曲方面,AI也很可能能够过滤掉许多技术二三流的作曲人,从而满足日益增长的音乐市场需求。

结尾:
AI可以通过一个理论上无限大的数据库和高速学习能力,制造出更加“完美”的艺术作品,但AI所有的“艺术创作”,本质上都是基于人类艺术家们的成果。所以,说到作曲,乃至拓展到艺术的各个领域,AI作为一种科技,其本质还是让人类的生活变得更便捷,功能是服务性的。如果我们能够在音乐领域恰当运用AI,正如在其他领域运用科技一样,能够大大提高生产效率,并协助人类进行创作上的突破。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

