“AI复兴”时代,致力于成为“AI引擎”的英伟达
“在加速计算领域深耕 25 年,英伟达致力于在 GPU 加速计算领域勇当先锋,解决普通计算机无法解决的问题。我们为当代的爱因斯坦、达芬奇和米开朗琪罗们打造计算机,为在座的各位打造计算机”NVIDIA GTC CHINA 2019 大会开始,英伟达创始人兼 CEO 黄仁勋为本次活动打下注脚


“在加速计算领域深耕 25 年,英伟达致力于在 GPU 加速计算领域勇当先锋,解决普通计算机无法解决的问题。我们为当代的爱因斯坦、达芬奇和米开朗琪罗们打造计算机,为在座的各位打造计算机”NVIDIA GTC CHINA 2019 大会开始,英伟达创始人兼 CEO 黄仁勋为本次活动打下注脚。
2019 年 12 月 18 日,NVIDIA GTC CHINA 2019 主题大会在苏州国际会议中心召开,本届 GTC CHINA 也以有超过 6100 人参会的规模创有史以来之最。

英伟达创始人兼 CEO 黄仁勋
当前时代,随着摩尔定律的终结,GPU 加速计算正在逐渐成为未来发展方向,英伟达在此深耕 25 年之久,通过软件堆栈优化,多 GPU 和多节点系统实现高效的计算加速。截止到现在,英伟达已经售出 15 亿块 GPU,均采用和兼容 CUDA 架构。
英伟达致力如此,旨在通过出色的芯片性能和全栈优化实现摩尔定律加速。
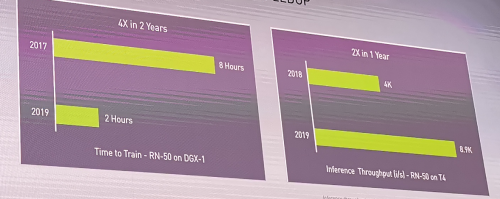
黄仁勋表示,仅在去年,我们就发布了 500 多个 SDK 和库,其中既有全新内容,也有更新版本。为了提高 GPU 性能,深度学习训练在 3 年内提高 4 倍,深度学习推理在 1 年内提高 2 倍。
在后面的演讲中,黄仁勋谈到了 AI 变革新动向,以及英伟达在自动驾驶、游戏和医疗以及建筑等新领域多个行业的新进展。英伟达将 GPU、深度专业知识、计算堆栈、算法和生态系统知识集于一身,立足 CUDA 架构,布局多样化市场。
自动驾驶领域:自主机器平台 DRIVE AGX Orin
现场,英伟达发布用于自动驾驶和机器人的高度先进的软件定义平台——DRIVE AGX Orin。

DRIVE AGX Orin
Orin 可处理在自动驾驶汽车和机器人中同时运行的大量应用和深度神经网络,能够支持从 L2 级到 L5 级完全自动驾驶汽车开发的兼容架构平台,助力 OEM 开发大型复杂的软件产品系列。由于 Orin 和 Xavier 均可通过开放的 CUDA、TensorRT API 及各类库进行编程,因此开发者能够在一次性投资后使用跨多代的产品。

(点击图片可看大图)
Orin 平台内置全新 Orin 系统级芯片,晶体管数量达到 170 亿个,集成 NVIDIA 新一代 GPU 架构和 Arm Hercules CPU 内核以及全新深度学习和计算机视觉加速器,每秒可运行 200 万亿次计算,几乎是 NVIDIA 上一代 Xavier 系统级芯片性能的 7 倍。此外,Orin 可处理在自动驾驶汽车和机器人中同时运行的大量应用和深度神经网络,并且达到了 ISO 26262 ASIL-D 等系统安全标准。NVIDIA DRIVE AGX Orin 计划于 2022 年开始投产。
在汽车领域,黄仁勋还宣布,英伟达将在 NVIDIA GPU Cloud (NGC) 容器注册上,向交通运输行业开源 NVIDIA DRIVE 自动驾驶汽车开发深度神经网络。如今,NVIDIA 向自动驾驶汽车开发者开源其预训练 AI 模型和训练代码。通过一套 NVIDIA AI 工具,NVIDIA 生态系统内的开发者们可以自由扩展和自定义模型,从而提高其自动驾驶系统的稳健性与能力。
现场,英伟达宣布和滴滴合作,滴滴将在数据中心使用 NVIDIA GPU 训练机器学习算法,并采用 NVIDIA DRIVE 为其 L4 级自动驾驶汽车提供推理能力。为了训练这些深度神经网络,滴滴将采用 NVIDIA GPU 数据中心服务器。在云计算方面,滴滴还将构建领先的 AI 基础架构,并推出计算型、渲染型和游戏型 vGPU 云服务器。(详情见下方链接:英伟达与滴滴合作详情)
计算图优化编译器:重磅发布 TensorRT 7
TensorRT 是一种计算图优化编译器,以深度学习为框架,以训练得到的模型为输入,寻找计算图中可以融合的节点和边,从而减少计算和内存访问。TensorRT 7 是继去年 GTC 大会发布 TensorRT 5 之后的升级版本,弥补了 TensorRT 5 仅支持 CNN 的不足。

TensorRT 7 支持各种类型的 RNN,Transformer 和 CNN。相比 TRT5 只支持 30 种模型,TRT 7 能够支持多达 1000 种不同的计算变换和优化。TRT 7 能够融合水平和垂直方向的运算,可以为开发者设计的大量 RNN 配置自动生成代码,逐点融合 LSTM 单元,甚至可跨多个时间步长进行融合,并尽可能做自动低精度推理。此外,英伟达在 TensorRT 7 中引入一个内核生成功能,用任何 RNN 可生成一个优化的内核。
同时,会话式 AI 是 TensorRT 7 强大功能的典型代表,一套端到端会话式 AI 的流程可能由二三十种模型组成,用到 CNN、RNN、Transformer、自编码器、NLP 等多种模型结构。推理会话式 AI,CPU 的推理延迟是 3 秒,现在使用 TensorRT 7 在 T4 GPU 上推理仅 0.3s 就完成,比 CPU 快 10 倍。
游戏领域新进展
游戏业务撑起英伟达的半壁江山。这句话在英伟达 2020 财年 Q3 财报可以印证,英伟达第三季度收入达 30.1 亿美元,其中游戏业务为 16.6 亿美元。
现场,黄仁勋宣布了 6 款支持 RTX 的游戏,为《暗影火炬》《project X》《无限法则》《轩辕剑柒》《铃兰计划》《边境》,表明 RTX 技术的开发者数量飙升。

除此之外,英伟达还创造出了 Max-Q 设计,将超高的 GPU 能效和总体系统优化集于一身,可以用于轻薄的高性能笔记本电脑。
同时,随着云计算的普及,云游戏也将越来越普及。黄仁勋在 GTC China 2019 上也宣布,英伟达与腾讯游戏合作推出 START 云游戏服务,该服务已从今年初开始进入测试阶段。RTX GPU 是英伟达去年最重磅的发布,可以看到其在持续推动这项技术更多的应用。(相关详情请点击链接查看:英伟达与腾讯合作详情)
机器人领域:NVIDIA ISAAC 机器人 SDK
面向机器人领域,黄仁勋宣布推出全新 NVIDIA Isaac 机器人 SDK,大大加快开发和测试机器人的速度,使机器人能通过仿真获得由 AI 驱动的感知和训练功能,从而可以在各种环境和情况下对机器人进行测试和验证,并节省成本。
Isaac SDK 包括 Isaac Robotics Engine(提供应用程序框架),Isaac GEM(预先构建的深度神经网络模型、算法、库、驱动程序和 API),用于室内物流的参考应用程序,并引入 Isaac Sim 训练机器人,可将所生成的软件部署到在现实世界中运行的真实机器人中。其中,基于摄像头的感知深度神经网络有对象检测、自由空间分割、3D 姿态估计、2D 人体姿态估计等模型。(详细内容请点击链接:ISAAC 机器人 SDK 详情)
其他领域进展
云渲染平台:现场,黄仁勋宣布瑞云云渲染平台将配备 NVIDIA RTX GPU,首批 5000 片 RTX GPU 将在 2020 年上线。其中超过 85%的中国电影工作室都是瑞云的客户,《战狼 2》、《哪吒》和《流浪地球》就是出自其手,堪称全亚洲最大的云渲染平台。
建筑行业(AEC):黄仁勋还发布了面向 AEC 的 Omniverse 开放式 3D 设计协作平台,本地和云端均支持在 AEC 工作流中增加实时协作功能,将支持 Autodest REVIT、Trimble SketchUP 和 McNeel Rhino 等主流 AEC 应用。NVIDIA Omniverse 是一个面向 3D 制作流程的协作平台,基于 Pixar 公司的 Universal Scene Description 技术,并由 NVIDIA RTX 提供支持。
推荐系统 AI:AI 技术如今在数据分析和挖掘、高性能计算中发挥着更加重要的作用,英伟达已经推出了面向训练、云端、终端、自动驾驶的 AI 平台。AI 对于拥有大量数据的科技公司尤为重要,比如推荐系统,如果没有推荐系统,人们无法从上万亿次网页检索、几十亿淘宝商品、几十亿抖音视频、各种新闻中找到自己需要的内容。因此,一个能够深度理解每一个用户,在正确时间给出正确的推荐的推荐系统极为关键。
百度和阿里巴巴的推荐系统都在使用英伟达 AI 技术。
百度 AIBox 推荐系统采用英伟达 AI,100 多个推荐模型被使用在百度的众多应用中。这个系统基于英伟达 Telsa v100 GPU,利用这些 TB 级的数据集去创建一个模型、在 GPU 上训练这些数据,然后把它放到 GPU 的内存当中去训练这种 TB 级别的数据,GPU 训练成本只有 CPU 的十分之一,并且支持更大规模的模型训练。
阿里巴巴搭建的推荐系统采用了英伟达的 T4 GPU,推荐系统的吞吐量得到了大幅提升。面对每秒几十亿次的推荐请求,CPU 速度只有 3 QPS,英伟达 GPU 则提升到了 780 QPS,提升百倍。(详情请点击下方链接:英伟达与阿里巴巴合作详情)
NVIDIA Parabricks 基因组分析工具包:此外,英伟达还发布了基于 CUDA 加速的 NVIDIA Parabricks 基因组分析工具包,可与用于发现变异并能产生与行业标准 GATK 最佳实践流程一致的结果,实现 30-50 倍的加速。英伟达正在与华大基因合作,使用 CUDA 的生命科学超级计算机,以每天 60 个基因组的超大吞吐量改变着全基因组测序,同时还降低了成本。
会后媒体采访环节,英伟达自主机器产品管理部门主管 Murali Gopalakrishna 及英伟达企业市场兼开发者计划全球副总裁 Greg Estes 介绍了英伟达在自主机器和深度学习学院(DLI)方面的进展。

英伟达自主机器产品管理部门主管 Murali Gopalakrishna
针对英伟达自主机器平台,Murali Gopalakrishna 介绍道:“英伟达自主机器平台——NVIDIA Jetson 模块可提供不同性能和价格水平的加速计算功能,以满足多种自主应用程序的需求。Jetson 系列包含 Jetson Nano 模块、Jetson TX2 模块、Jetson Xavier NX 模块以及 Jetson AGX Xavier 模块等产品。

(点击可看大图)
从制造到建筑,从医疗到配送,NVIDIA Jetson 平台均能提供无与伦比的性能、能效和易开发性。每个系统都是一个完备的模块化系统 (SOM),具备 CPU、GPU、PMIC、DRAM 和闪存,可节省开发时间和资金。Jetson 还具备可扩展性。只需选择适合应用场合的 SOM,即能够以此为基础构建自定义系统,满足特定的应用需求。”
DLI 部分,Greg Estes 表示,DLI 提供 AI、加速计算和加速数据科学方面的应用开发实践培训,以期解决实际应用方面的问题。基于云端 GPU 平台,开发者、数据科学家、研究人员和院校师生可以获取和丰富相关的实践经验,并获得全球开发者培训证书,为职业发展提供有力证明。所有课程可以长期、多次、反复学习和实验。

英伟达企业市场兼开发者计划全球副总裁 Greg Estes
个人学习可以从“在线自主培训”开始。团体或企业培训可以从“讲师指导的培训班”开始学习。DLI 同时为大学师生提供更多的培训资源和支持。
上述详细内容可以在英伟达官网查看。
写在最后
可以看到,英伟达在本届活动上大秀 AI、汽车、游戏、HPC 能力,同时宣布多个领域的朋友圈等生态进展。
作为迄今 AI 深度学习红利的最大受益者,英伟达以高性能的软硬件和系统为基础,持续丰富其 AI 和自动驾驶生态,不断寻找核心场景加速落地。
在“AI 复兴”时代,英伟达在致力于成为“AI 引擎”的道路上驰骋着。
作者:李晨光
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

