全球自动驾驶汽车硬件和软件最新技术总结
进入到2020年,自动驾驶技术走到了需要规模商业化证明技术价值的时候。 不管是封闭或半封闭场景的矿区、港口和园区,还是公开道路的RoboTaxi、RoboTruck等,技术都是自动驾驶在不同场景商业化的基础

进入到2020年,自动驾驶技术走到了需要规模商业化证明技术价值的时候。
不管是封闭或半封闭场景的矿区、港口和园区,还是公开道路的RoboTaxi、RoboTruck等,技术都是自动驾驶在不同场景商业化的基础。
本报告覆盖了自动驾驶汽车所需要的感知、定图与定位、传感器融合、机器学习方法、数据收集与处理、路径规划、自动驾驶架构、乘客体验、自动驾驶车辆与外界交互、自动驾驶对汽车部件的挑战(如功耗、尺寸、重量等)、通讯与连接(车路协同、云端管理平台)等技术领域的讨论,并且提供相应的各自动驾驶公司的实施案例。 本报告是由美国、中国、以色列、加拿大、英国等全球不同国家和地区的自动驾驶专家,针对自动驾驶技术的硬件和软件技术,进行的全面阐述,方便各位读者能够从技术角度,了解最新的技术动态,从而全面了解自动驾驶汽车。 本报告的案例大多数来自汽车领域,这也是目前自动驾驶行业最火热的应用场景,但是,服务个人出行的汽车并不是自动驾驶技术影响深远的行业,其他的行业,如公共交通、货运、农业、矿业等领域,也同样是自动驾驶技术应用的广泛天地。 本报告为英文报告,由于时间关系,车智并未翻译为中文。借此机会,车智希望外文出色(主要是英文)的读者朋友,加入车智翻译组,希望将一些好的报告,翻译为中文,方便国内的从业者学习,促进国内自动驾驶的发展。

各类传感器
各类传感器,用于自动驾驶汽车感知环境,如同人类的眼睛,自动驾驶汽车的基础部件; 自动驾驶汽车的传感器主要有五种,包括了:1、Long range RADAR;2、Camera;3、LIDAR;4、Short/Medium range RADAR;5、Ultrasound; 这些不同的传感器,主要用于不同距离、不同类型的物体感知,为自动驾驶汽车判断周边环境,提供最重要的信息来源,另外,还有一个环境感知的信息来源是车路协同的来源,这点报告中也有参数。
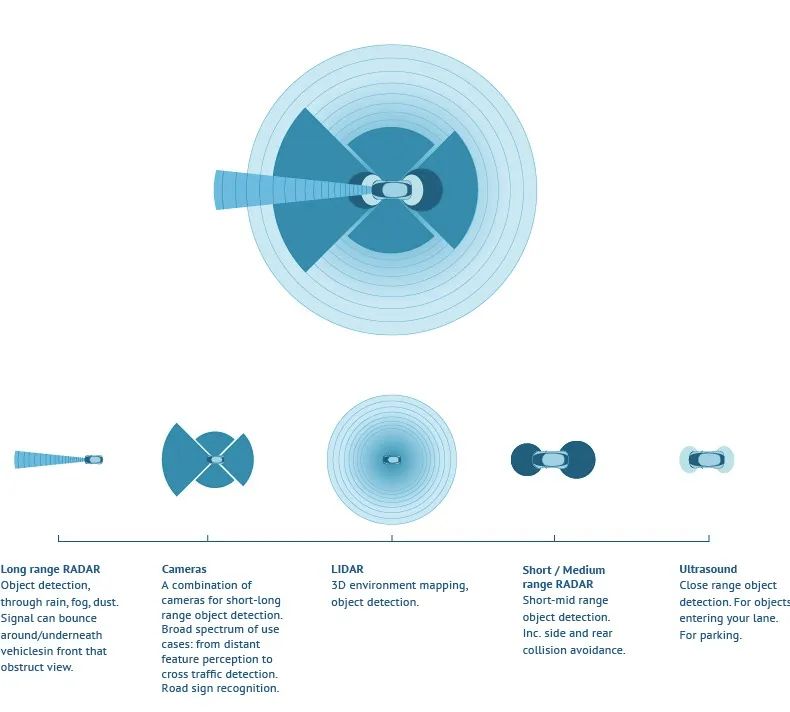
关于传感器的选择,主要是根据下面的技术因素进行判断:
1、扫描范围,确定必须对被感测的对象做出反应的时间;2、分辨率,确定传感器可以为自动驾驶车辆提供的环境细节;3、视场或角度分辨率,确定要覆盖、要感知的区域需要传感器的数量;4、刷新率,确定来自传感器的信息更新的频率;5、感知对象数量,能够区分3D中的静态对象数量和动态对象数量,并且确定需要跟踪的对象数量;6、可靠性和准确性,传感器在不同环境下的总体可靠性和准确性;7、成本、大小和软件兼容性,这是量产的技术条件之一;8、生成的数据量,这决定了车载计算单元的计算量,现在传感器偏向智能传感器,也就是,不仅仅是感知,还会分辨信息,把对车辆行驶影响最重要的数据传输给车载计算单元,从而减少其计算负荷;
下面是Waymo、Volvo-Uber、Tesla的传感器方案示意图:
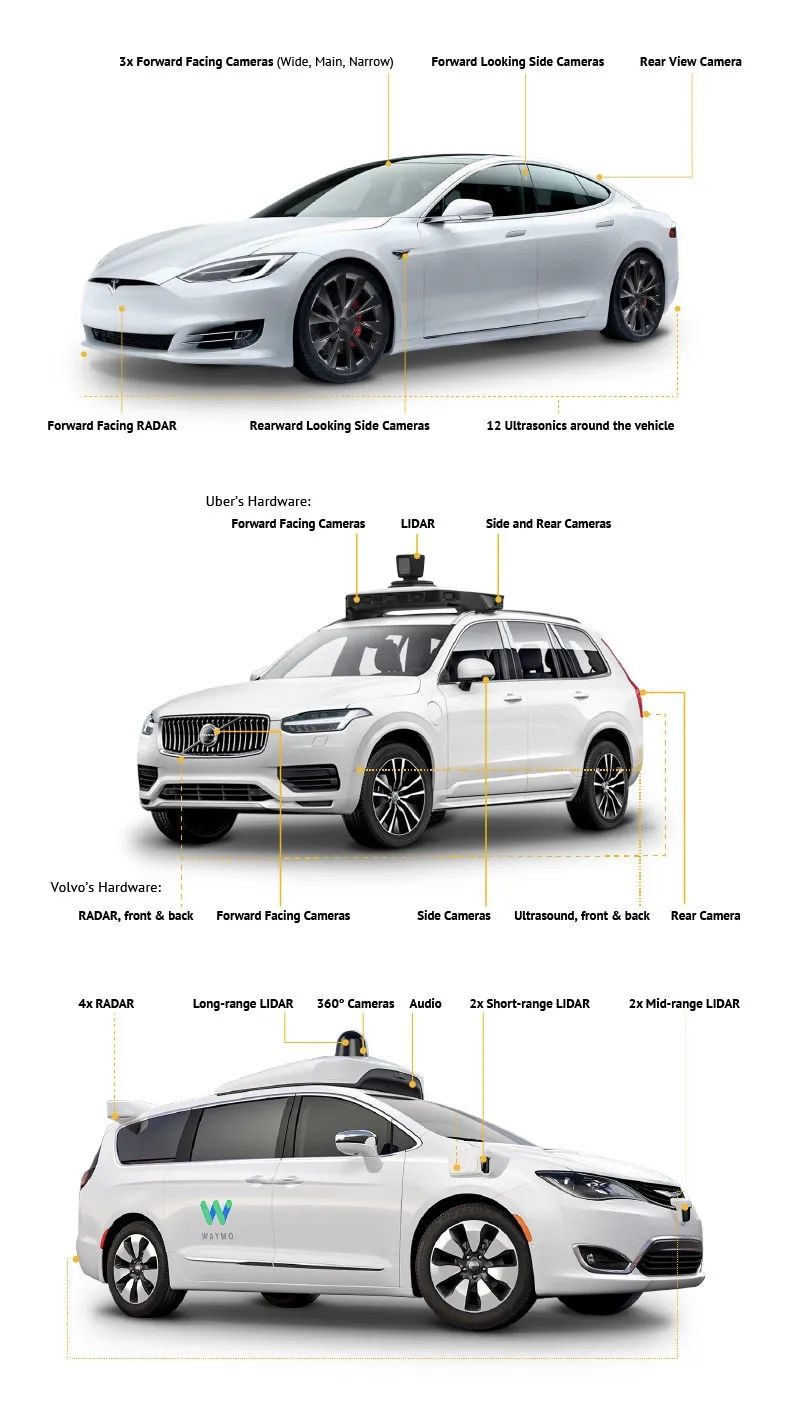
传感器因为一直暴露在环境中,容易受到环境的污染,从而影响传感器的工作效率,所以,都需要对传感器进行清洁。1、Tesla的传感器,具有加热功能,可抵御霜冻和雾气;2、Volvo的传感器配备有喷水清洁系统,用于清洁粉尘;3、Waymo使用的Chrysler Pacifica的传感器有喷水系统和刮水器。
SLAM和传感器融合
SLAM是一个复杂的过程,因为本地化需要地图,并且映射需要良好的位置估计。尽管长期以来人们一直认为机器人要成为自主的基本“鸡或蛋”问题,但在1980年代和90年代中期的突破性研究从概念和理论上解决了SLAM。从那时起,已经开发了多种SLAM方法,其中大多数使用概率概念。 为了更准确地执行SLAM,传感器融合开始发挥作用。传感器融合是组合来自多个传感器和数据库的数据以获得改进信息的过程。它是一个多级过程,处理数据的关联,相关性和组合,与仅使用单个数据源相比,可以实现更便宜,更高质量或更多相关信息。
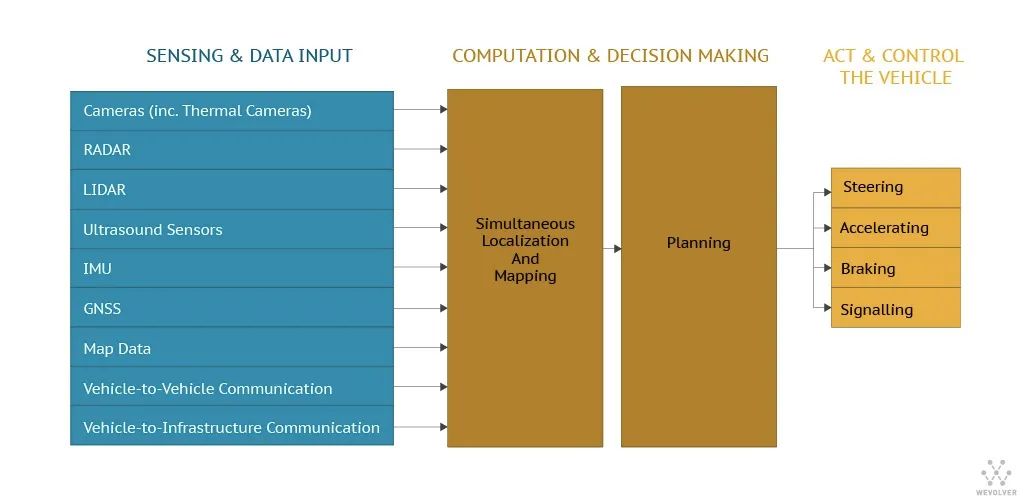
对于从传感器数据到运动所需的所有处理和决策,通常使用两种不同的AI方法: 1、顺序地,将驱动过程分解为分层管道的组件,每个步骤(传感,定位,路径规划,运动控制)都由特定的软件元素处理,管道的每个组件都将数据馈送到下一个;2、基于深度学习的端到端解决方案,负责所有这些功能。
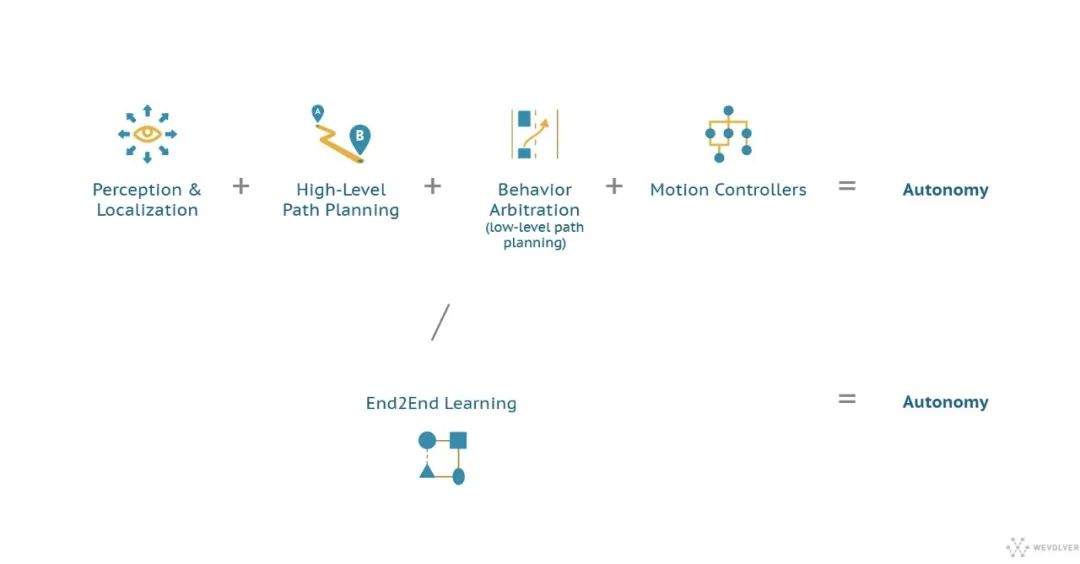
哪种方法最适合AV的问题是不断争论的领域。传统且最常见的方法包括将自动驾驶问题分解为多个子问题,并使用专用的机器学习算法技术依次解决每个子问题,这些算法包括计算机视觉,传感器融合,定位,控制理论和路径规划 端到端(e2e)学习作为一种解决方案,可以解决自动驾驶汽车复杂AI系统所面临的挑战,因此越来越受到人们的关注。端到端(e2e)学习将迭代学习应用于整个复杂系统,并已在深度学习的背景下得到普及。
三种机器深度学习方法
当前,不同类型的机器学习算法被用于自动驾驶汽车中的不同应用。本质上,机器学习根据提供的一组训练数据将一组输入映射到一组输出。1、卷积神经网络(CNN);2、递归神经网络(RNN);3、深度强化学习(DRL);是应用于自动驾驶的最常见的深度学习方法。
CNN——主要用于处理图像和空间信息,以提取感兴趣的特征并识别环境中的对象。这些神经网络由卷积层组成:卷积过滤器的集合,它们试图区分图像元素或输入数据以对其进行标记。该卷积层的输出被馈送到一种算法中,该算法将它们组合起来以预测图像的最佳描述。最终的软件组件通常称为对象分类器,因为它可以对图像中的对象进行分类,例如路牌或其他汽车。 RNN——当处理诸如视频之类的时间信息时,RNN是强大的工具。在这些网络中,先前步骤的输出作为输入被馈送到网络中,从而使信息和知识能够持久存在于网络中并被上下文化。 DRL——将深度学习(DL)和强化学习相结合。DRL方法使软件定义的“代理”可以使用奖励功能,在虚拟环境中学习最佳行动,以实现其目标。这些面向目标的算法学习如何实现目标,或如何在多个步骤中沿特定维度最大化。尽管前景广阔,但DRL面临的挑战是设计用于驾驶车辆的正确奖励功能。在自动驾驶汽车中,深度强化学习被认为仍处于早期阶段。 这些方法不一定孤立地存在。例如,特斯拉(Tesla)等公司依靠混合形式,它们试图一起使用多种方法来提高准确性并减少计算需求。 一次在多个任务上训练网络是深度学习中的常见做法,通常称为多任务训练 或辅助任务训练。这是为了避免过度拟合,这是神经网络的常见问题。当机器学习算法针对特定任务进行训练时,它会变得非常专注于模仿它所训练的数据,从而在尝试进行内插或外推时其输出变得不切实际。通过在多个任务上训练机器学习算法,网络的核心将专注于发现对所有目的都有用的常规功能,而不是仅仅专注于一项任务。这可以使输出对应用程序更加现实和有用。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

