通过辅助推理任务实现高效的视觉语义导航
自监督学习——通过辅助推理任务实现高效的视觉语义导航。关于作者朱峰达本科毕业于北航软件工程系,是蒙纳士大学信息技术学院数据科学与人工智能系的博士生,师从蒙纳士大学的常晓军老师和中山大学的梁小丹老师。他的研究兴趣在于机器学习中的视觉语言导航和推理任务
自监督学习——通过辅助推理任务实现高效的视觉语义导航。关于作者朱峰达本科毕业于北航软件工程系,是蒙纳士大学信息技术学院数据科学与人工智能系的博士生,师从蒙纳士大学的常晓军老师和中山大学的梁小丹老师。他的研究兴趣在于机器学习中的视觉语言导航和推理任务。
写在前面:
视觉语言导航(Vision Language Navigation)是一个机器学习的新兴任务。它的目的是让一个智能体能够在真实的3D环境中根据自然语言指令导航至正确的地点。这个任务有很多难点:1. 提取并融合视觉和语言的特征 2. 学习导航轨迹和房间结构的语义信息 3. 如何在未知的房间中利用已学习的知识进行探索。
传统的方法主要着重于视觉和语义特征的提取和融合,并将融合过后的混合特征通过一个策略网络生成动作。用这种方式学到的模型只对特征之间的相似度敏感,而对训练环境中的隐含信息,比如轨迹的语义和房间的结构没有直观认识。 而在这篇文章中,我们用自监督的方法,从环境中挖掘了丰富的隐含信息(比如室内结构图或者子轨迹的部分语义信息)。它们为我们的模型提供了更丰富的训练信号。
我们提出了四种不同的辅助推理任务:1. 解释之前的动作 2. 估计导航的进度 3. 预测语言和轨迹的吻合程度 4. 预测下一步的方向。
我们的实验证明这四个辅助推理任务可以帮助我们模型导航得更精确、更有效率,并且它们可以使模型在没有标注的房间里进行自适应学习。同时,辅助推理任务可以让模型具有可解释性。在测试环境中,我们通过模型在辅助任务上的输出可以更加了解模型的“思考”方式。
一个简单的例子:
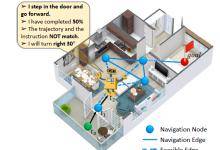
如图所示为一个用自监督辅助任务来训练导航模型的简单例子。模型从绿点开始,根据一个自然语言指令走到目标红点。蓝色的点表示模型下一步可以导航到的位置,也就是隐式的室内结构图。途中每一时刻它都会被要求预测四个辅助任务的结果。辅助任务带来的额外信息和语义约束可以帮助模型更好地学习这个任务。 方法细节描述
我们提出了一个基于强化学习、监督学习和自监督学习的混合学习框架 (AuxRN) 来完成室内导航任务。 从视觉语言输入到动作序列预测。
首先我们要分别编码历史视觉信息和全局语义信息。我们将当前点的全景图经过一个注意力模块 Attno 获得当前点的全景视觉编码,再经过一个LSTMv 模块获得一个历史轨迹的视觉编码。该特征编码了模型从开始到当前步的历史轨迹。我们再将自然语言指令经过一个双向 LSTM 获得一组语言的特征编码。为了将视觉特征和自然语言特征对齐,我们将视觉信息和语言信息通过另一个注意力模块 Attnw。这一步是为了根据最近几步看到的视觉信息找到对应的自然语言指令的位置,从而获得确切的子指令。最后我们从导航模拟器中获取下一步可导航位置,获取从当前点看向该位置方向的视觉特征,利用一个注意力模块 Attnc 输出分类结果作为下一步要采取的动作。 模型输出的动作序列使用监督学习和强化学习联合训练。监督学习的数据来源于从起点到终点的最短路,而强化学习的奖励函数来源于当前步比上一步距离目标点缩短的距离。
四种辅助推理任务:
在此基础上,我们提出了四种自监督辅助推理任务来挖掘环境中的隐含信息。
指令重述任务
首先我们希望我们的视觉编码模块能够获得和自然语言指令相同的语义特征。同时为了约束模型的训练过程,让模型能够在有限时间内收敛,我们简化了任务。我们保存每一步的历史视觉编码,获得视觉特征。我们将自然语言句子通过一个LSTM模块编码成一组特征向量,将语言和视觉特征通过一个注意力模块 Attns 融合,再从融合过后的编码中分离出目标词向量。
进度预测任务
模型可以通过学习导航的进度来加深导航任务的理解。它能帮助模型更好地对齐视觉和语言特征。我们改进了之前的工作,用噪音更小的步数代替距离作为导航进度的标签,用交叉熵 (Binary Cross Entropy) 损失函数代替均方差 (Mean Square Error) 损失函数。
多模态匹配任务
在多模态匹配任务中,我们将自然语言特征组经过一个均值池化层(在图中用P表示)获得一个自然语言特征向量。我们以0.5的概率用数据集中的另一条不相关的自然语言向量替换这个向量(在图中用S表示)。最后,我们将这个向量和语言特征向量连接(在图中用C表示)通过两层全连接层和一层Sigmoid 激活层获得它们匹配的概率
在实现的时候,考虑到训练的效率,替换这个操作局限于一个batch内,我们会把0.5概率选中的自然语言向量用同一batch的另一个自然语言向量代替。这个操作可以并行化。
角度预测任务
在一开始我们提到了我们的动作预测是通过一个注意力机制实现的。从导航模拟器中获取下一步可导航位置的一个候选集。将语言和视觉的融合特征与候选集的视觉特征逐一匹配,选择匹配度最大的那个作为下一步要走的方向。用这种方式学到的模型只对特征之间的相似度敏感,而对房间结构没有显式的感知。我们可以让模型预测下一步要走的方向来约束模型,使其能够学到有关房间结构的信息,而这些信息对导航是有帮助的。
最后,我们将这四个辅助任务的损失和主函数的损失加到一起进行训练
在这里我们没有做过多的调参工作,把各损失的权重都设置为1即可。 实验结果
我们的模型在标准视觉语言导航数据集(R2R)上取得了第一名的成绩。
我们的对比实验说明了各个辅助任务都会对模型的性能有较大提升。并且它们的联合训练会进一步提升模型的性能。
我们可视化了两个在测试集上的导航轨迹。在序列开始模型会收到自然语言指令的输入,指示每一步要走的方向和目标物体。每走一步模型都收到一张全景图作为视觉输入。红色箭头代表模型预测的下一步去往的方向。我们可以看到模型准确地到达了目标位置,并且模型能够准确预测导航的进度以及轨迹和语言指令的匹配程度。
这里我们做了一个 demo 分享了更多可视化结果,供大家直观地了解数据集分布和我们的模型所能达到的效果。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

