大道至简——RISC-V架构之魂(中)
“大道至简——RISC-V架构之魂”——分成上中下三篇,本文是中篇。关注文末公众号后可查询上中下三篇的内容。
本文为《RISC-V CPU设计》专栏和《RISC-V嵌入式软件开发》专栏系列文章之一。
注:本文节选自“硅农亚历山大”所著国内第一本系统介绍CPU与RISC-V设计的中文书籍《手把手教你设计CPU:RISC-V处理器篇》(预计将于2018年3~4月上市)。
“大道至简——RISC-V架构之魂”——分成上中下三篇,本文是中篇。关注文末公众号后可查询上中下三篇的内容。
本文上接《大道至简——RISC-V架构之魂(上)》
2.3 规整的指令编码
在流水线中能够尽早尽快的读取通用寄存器组,往往是处理器流水线设计的期望之一,这样可以提高处理器性能和优化时序。这个看似简单的道理在很多现存的商用RISC架构中都难以实现,因为经过多年反复修改不断添加新指令后,其指令编码中的寄存器索引位置变得非常的凌乱,给译码器造成了负担。
得益于后发优势和总结了多年来处理器发展的教训,RISC-V的指令集编码非常的规整,指令所需的通用寄存器的索引(Index)都被放在固定的位置,如图2所示。因此指令译码器(Instruction Decoder)可以非常便捷的译码出寄存器索引然后读取通用寄存器组(Register File,Regfile)。
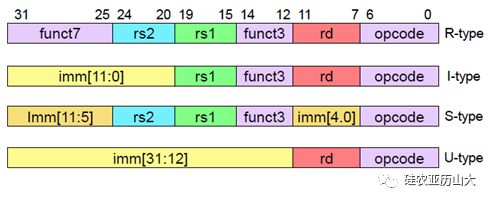
图2 RV32I规整的指令编码格式
2.4 简洁的存储器访问指令
与所有的RISC处理器架构一样,RISC-V架构使用专用的存储器读(Load)指令和存储器写(Store)指令访问存储器(Memory),其他的普通指令无法访问存储器,这种架构是RISC架构的常用的一个基本策略,这种策略使得处理器核的硬件设计变得简单。
存储器访问的基本单位是字节(Byte)。RISC-V的存储器读和存储器写指令支持一个字节(8位),半字(16位),单字(32位)为单位的存储器读写操作,如果是64位架构还可以支持一个双字(64位)为单位的存储器读写操作。
RISC-V架构的存储器访问指令还有如下显著特点:
为了提高存储器读写的性能,RISC-V架构推荐使用地址对齐的存储器读写操作,但是地址非对齐的存储器操作RISC-V架构也支持,处理器可以选择用硬件来支持,也可以选择用软件来支持。
由于现在的主流应用是小端格式(Little-Endian),RISC-V架构仅支持小端格式。有关小端格式和大端格式的定义和区别,本文在此不做过多介绍,若对此不甚了解的初学者可以自行查阅学习。
很多的RISC处理器都支持地址自增或者自减模式,这种自增或者自减的模式虽然能够提高处理器访问连续存储器地址区间的性能,但是也增加了设计处理器的难度。RISC-V架构的存储器读和存储器写指令不支持地址自增自减的模式。
RISC-V架构采用松散存储器模型(Relaxed Memory Model),松散存储器模型对于访问不同地址的存储器读写指令的执行顺序不作要求,除非使用明确的存储器屏障(Fence)指令加以屏蔽。
这些选择都清楚地反映了RISC-V架构力图简化基本指令集,从而简化硬件设计的哲学。RISC-V架构如此定义非常合理,能够达到能屈能伸的效果。譬如:对于低功耗的简单CPU,可以使用非常简单的硬件电路即可完成设计;而对于追求高性能的超标量处理器则可以通过复杂设计的动态硬件调度能力来提高性能。
2.5 高效的分支跳转指令
RISC-V架构有两条无条件跳转指令(Unconditional Jump),jal与jalr指令。跳转链接(Jump and Link)指令jal可用于进行子程序调用,同时将子程序返回地址存在链接寄存器(Link Register:由某一个通用整数寄存器担任)中。跳转链接寄存器(Jump and Link-Register)指令jalr指令能够用于子程序返回指令,通过将jal指令(跳转进入子程序)保存的链接寄存器用于jalr指令的基地址寄存器,则可以从子程序返回。
RISC-V架构有6条带条件跳转指令(Conditional Branch),这种带条件的跳转指令跟普通的运算指令一样直接使用2个整数操作数,然后对其进行比较,如果比较的条件满足时,则进行跳转。因此,此类指令将比较与跳转两个操作放到了一条指令里完成。
作为比较,很多的其他RISC架构的处理器需要使用两条独立的指令。第一条指令先使用比较指令,比较的结果被保存到状态寄存器之中;第二条指令使用跳转指令,判断前一条指令保存在状态寄存器当中的比较结果为真时则进行跳转。相比而言RISC-V的这种带条件跳转指令不仅减少了指令的条数,同时硬件设计上更加简单。
对于没有配备硬件分支预测器的低端CPU,为了保证其性能,RISC-V的架构明确要求其采用默认的静态分支预测机制,即:如果是向后跳转的条件跳转指令,则预测为“跳”;如果是向前跳转的条件跳转指令,则预测为“不跳”,并且RISC-V架构要求编译器也按照这种默认的静态分支预测机制来编译生成汇编代码,从而让低端的CPU也能得到不错的性能。
为了使硬件设计尽量简单,RISC-V架构特地定义了所有的带条件跳转指令跳转目标的偏移量(相对于当前指令的地址)都是有符号数,并且其符号位被编码在固定的位置。因此,这种静态预测机制在硬件上非常容易实现,硬件译码器可以轻松的找到这个固定的位置,并判断其是0还是1来判断其是正数还是负数,如果是负数则表示跳转的目标地址为当前地址减去偏移量,也就是向后跳转,则预测为“跳”。当然对于配备有硬件分支预测器的高端CPU,则可以采用高级的动态分支预测机制来保证性能。
2.6 简洁的子程序调用
为了理解此节,需先对一般RISC架构中程序调用子函数的过程予以介绍,其过程如下:
进入子函数之后需要用存储器写(Store)指令来将当前的上下文(通用寄存器等的值)保存到系统存储器的堆栈区内,这个过程通常称为“保存现场”。
在退出子程序之时,需要用存储器读(Load)指令来将之前保存的上下文(通用寄存器等的值)从系统存储器的堆栈区读出来,这个过程通常称为“恢复现场”。
“保存现场”和“恢复现场”的过程通常由编译器编译生成的指令来完成,使用高层语言(譬如C或者C++)开发的开发者对此可以不用太关心。高层语言的程序中直接写上一个子函数调用即可,但是这个底层发生的“保存现场”和“恢复现场”的过程却是实实在在地发生着(可以从编译出的汇编语言里面看到那些“保存现场”和“恢复现场”的汇编指令),并且还需要消耗若干的CPU执行时间。
为了加速这个“保存现场”和“恢复现场”的过程,有的RISC架构发明了一次写多个寄存器到存储器中(Store Multiple),或者一次从存储器中读多个寄存器出来(Load Multiple)的指令,此类指令的好处是一条指令就可以完成很多事情,从而减少汇编指令的代码量,节省代码的空间大小。但是此种“Load Multiple”和“Store Multiple”的弊端是会让CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,笔者在曾经设计此类处理器时便深受其苦。
RISC-V架构则放弃使用这种“Load Multiple”和“Store Multiple”指令。并解释,如果有的场合比较介意这种“保存现场”和“恢复现场”的指令条数,那么可以使用公用的程序库(专门用于保存和恢复现场)来进行,这样就可以省掉在每个子函数调用的过程中都放置数目不等的“保存现场”和“恢复现场”的指令。
此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃“Load Multiple”和“Store Multiple”指令可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU可以选择非常简单的电路进行实现,而高性能超标量处理器由于硬件动态调度能力很强,可以有强大的分支预测电路保证CPU能够快速的跳转执行,从而可以选择使用公用的程序库(专门用于保存和恢复现场)的方式减少代码量,但是同时达到高性能。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

