码隆科技提出跨越时空的样本配对
《Cross-Batch Memory for Embedding Learning》提出了 XBM 方法,能够用极小的代价,提供巨量的样本对,为 pair-based 的深度度量学习方法取得巨大的效果提升。

作者: 将门投资企业 码隆科技研究团队将门好声音第·54·期CVPR 2020系列分享第·13·期将门投资企业——码隆科技今年在 CVPR 多有斩获。在大会论文接受率仅有 22%、被称为“十年来最难的一届”的情况下,有两篇论文入选 CVPR 2020,本文将为大家解读其中一篇Oral:《Cross-Batch Memory for Embedding Learning》 。
导读:
该论文提出了 XBM 方法,能够用极小的代价,提供巨量的样本对,为 pair-based 的深度度量学习方法取得巨大的效果提升。
这种提升难例挖掘效果的方式突破了过去两个传统思路:加权和聚类,并且效果也更加简单、直接,很好地解决了深度度量学习的痛点。XBM 在多个国际通用的图像搜索标准数据库上(比如 SOP、In-Shop 和 VehicleID 等),取得了目前最好的结果。

一、背景和动机
难例挖掘是深度度量学习领域中的核心问题,最近有颇多研究都通过改进采样或者加权方案来解决这一难题,目前主要两种思路: 第一种思路是在 mini-batch 内下功夫,对于 mini-batch 内的样本对,从各种角度去衡量其难度,然后给予难样本对更高权重,比如 N-pairs、Lifted Struture Loss、MS Loss 使用的就是此种方案。 第二种思路是在 mini-batch 的生成做文章,比如 HTL、Divide and Conquer,他们的做法虽然看上去各有不同,但是整体思路有异曲同工之处。大致思路都是对整个数据集进行聚类,每次生成 mini-batch 不是从整个数据集去采样,而是从一个子集,或者说一个聚类小簇中去采样。这样一来,由于采样范围本身更加集中,生成的 mini-batch 中难例的比例自然也会更大,某种程度上也能解决问题。 然而,无论是第一种方法的额外注重难样本,还是第二种方法的小范围采样,他们的难例的挖掘能力其实依然有一个天花板——那就是 mini-batch 的大小。这个 mini-batch 的大小决定了在模型中单次迭代更新中,可以利用的样本对的总量。因此,即使是很精细的采样加权方法,在 mini-batch 大小有限的情况下,也很难有顶级的表现。我们在三个标准图像检索数据库上进行了实验,基于三种标准的 pair-based 方法,我们发现随着 mini-batch 变大,效果(Recall@1)大幅提升。实验结果如下图:
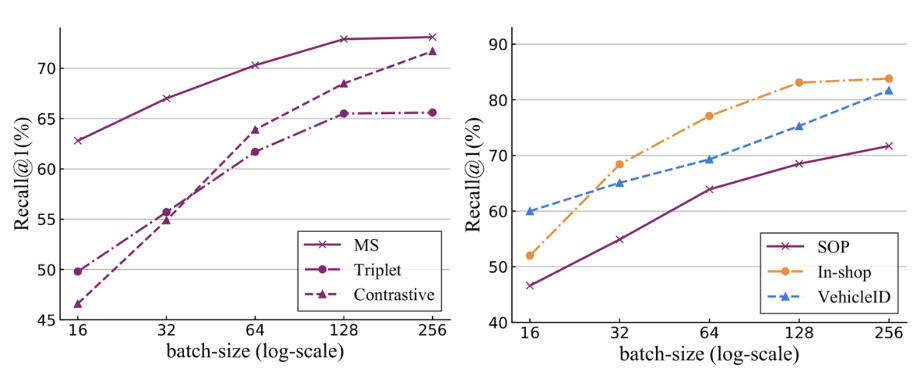
可以看出,随着 mini-batch 的增大,效果有显著提升。但是,在实际工业应用中 mini-batch 越大,训练所需要的 GPU 或 TPU 就越多,即使计算资源有充分保证,在多机多卡的训练过程中,如何在工程上保证通信的效率也是一个有挑战的问题。
二、特征偏移
由此,我们希望另辟蹊径,得以在 mini-batch 有限的情况下,也能获得充足的难例样本对。首先,必须突破深度度量学习一直以来的一个思维局限——仅在对当前 mini-batch里的样本对两两比较,形成样本对。以此我们引入了 XBM(Cross-batch Memory)这一方法来突破局限,跨越时空进行难例挖掘,把过去的 mini-batch 的样本提取的特征也拿过来与当前 mini-batch 作比较,构建样本对。

我们将样本特征随着模型训练的偏移量,称之为特征偏移(Feature Drift)。从上图我们发现,在训练的一开始,模型还没有稳定,特征剧烈变化,每过 100 次迭代,特征偏移大约 0.7 以上。但是,随着训练的进行,模型逐步稳定,特征的偏移也变小。我们称这个现象为慢偏移(Slow Drift),这是我们可以利用的一点。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

