百度AI开源:引领AI生态走向繁荣
2020年3月,注定是中国AI开发者不会遗忘的一个月。3月20日,清华大学计算机系图形实验室开源AI框架计图(Jittor),这是首个由中国学界开源的AI框架,直接对标PyTorch;3月24日,AI



2020年3月,注定是中国AI开发者不会遗忘的一个月。
3月20日,清华大学计算机系图形实验室开源AI框架计图(Jittor),这是首个由中国学界开源的AI框架,直接对标PyTorch;
3月24日,AI独角兽旷视科技宣布开源天元(MegEngine)——训练推理一体化、动静态合一的工业级深度学习框架;
3月28日,华为在开发者大会2020上宣布正式开源MindSpore,这是一款支持端边云全场景的深度学习训练推理框架。
短短8天,中国AI领域刮起一股开源风潮,而目标正是AI开源框架领域的霸主TensorFlow和PyTorch,这也许会成为国产深度学习框架开源历史上重要的高光时刻。
而这股风潮的领头人,是4年前打响国产AI框架开源第一枪的百度飞桨。
2016年百度飞桨开源之后,就已带动了一波风潮,腾讯机器学习平台Angel、阿里深度学习框架X-DeepLearning相继开源,也有OneFlow这样的初创公司加入,一个欣欣向荣的AI生态正在走近。
而百度,也在持续引领AI生态走向繁荣。
根据最新GitHub开源项目数据集GitHubArchive之中关于pull request的发起和合入数据,百度飞桨的open数据由去年的2759次跃升到今年同期的3391次,飞桨的 merged数据由1924次跃升为2428次,由此,百度飞桨在pull request的数据上已经成为国内第一、全球第二的领军存在。
这也意味着“动静统一、软硬融合”的飞桨一直在致力于让深度学习技术的创新与应用更简单,其提供的AI底层技术也深受开发者欢迎。
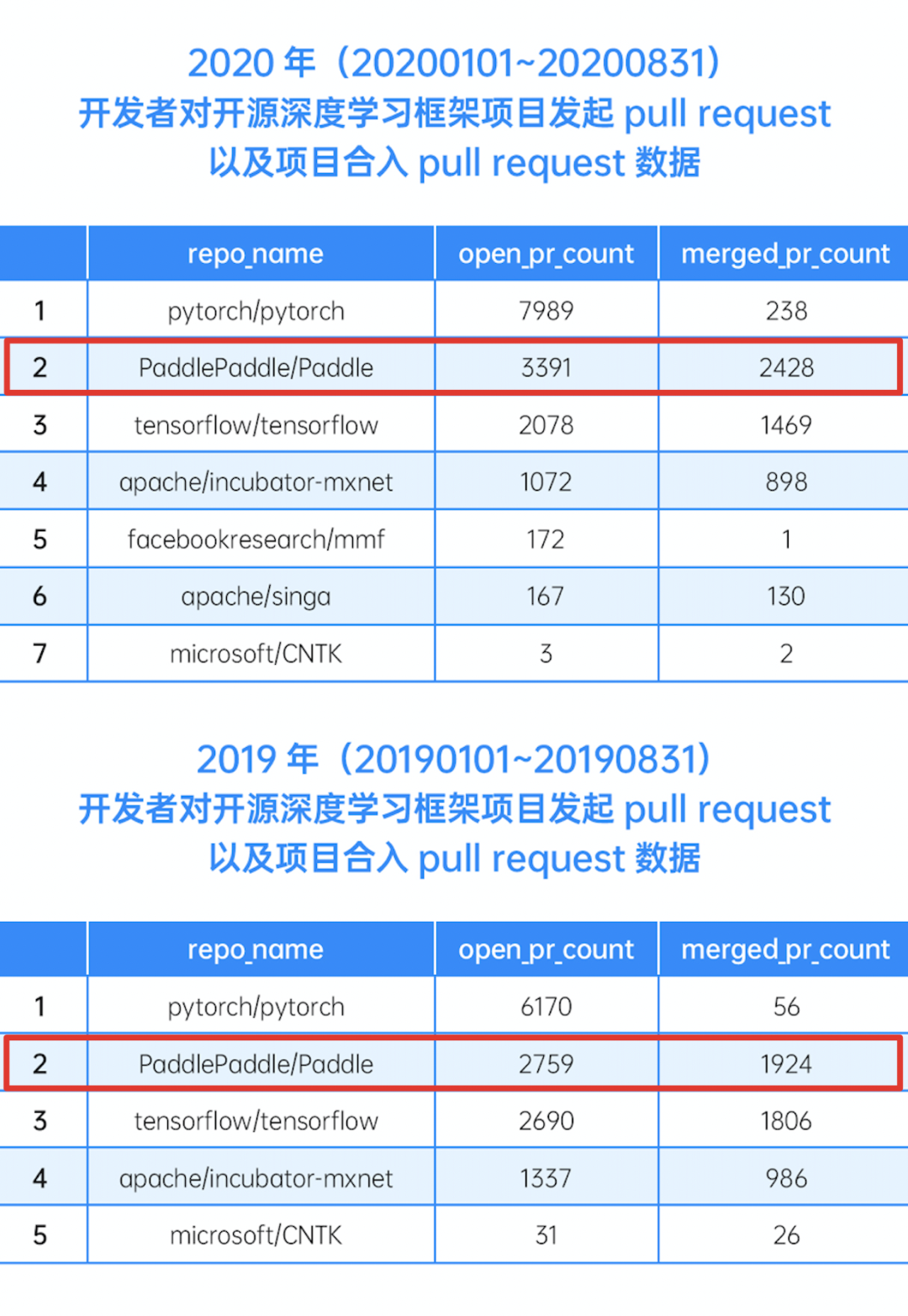
2020/2019年度全球开源深度学习框架活跃度排名榜单
AI开源框架的搭建是一项费时费力的大工程,如果没有超越现有主流框架的想法,去重复造一套没有技术创新的轮子,不仅性价比不高,而且对开发者的吸引力也不够大。
这就引申出一个问题,在TensorFlow和PyTorch已有完整框架生态的情况下,为何百度以及一众的后来者还要执着于国产AI框架的开源?另造一套技术轮子,他们自研AI开源框架的价值和意义是什么?
止近渴:技术创新、业务需要
TensorFlow、PyTorch的强大毋庸置疑,例如TensorFlow在中国的用户就不乏网易、京东、360、联想、美团等科技企业。
但从战略和战术上,TensorFlow、PyTorch的缺点和劣势也显而易见。
战略上,虽然TensorFlow是开源的,但其与谷歌的深度绑定,不排除会出现类似Android的局面。所以,国内有百度自研,国外亚马逊、Facebook、微软、苹果等都在自研。
战术上,深度学习框架开源背后是商业利益的捆绑,而且在技术层面,TensorFlow、PyTorch也并非没有提升空间。
举个简单的例子,像TensorFlow在语音交互、神经网络翻译等核心技术上,很少有中文数据集以及中文领域的技术探索。
换言之,只有深谙中国开发者需求和中国AI市场生态的深度学习框架,才能精准满足本土用户需求。
并且,中国有其他国家无法比拟的商业优势,数据红利和庞大的应用场景促使AI相关技术更快落地。但是,无法逃避的一个问题是,不掌握底层技术,上层应用仍要面临「卡脖子」。
所以,无论是百度,还是阿里、华为等后来者,自研+开源是摆脱「卡脖子」的最佳方案。
百度飞桨作为国内AI开源的扛把子,2012年就开始着手深度学习平台框架研发,2016年飞桨正式开源。飞桨开源的历史动机由主观因素主导,也有客观因素存在。

百度飞桨全景图
主观因素是百度一直以来的技术背景和开源策略,从2009年大规模定制Hadoop开始到2013年率先开源ECharts,百度从布局AI开始,就一直坚持开源战略。
这种战略的具体落地,正是不断开源AI能力,这里面不仅有百度的基因和能力因素,更重要是表达一种开放的态度。
客观因素则是谷歌、Facebook、IBM等海外科技巨头先后将AI框架开源,AI框架开源背后往往跟随着各个公司的业务,比如谷歌的云服务、TPU资源等等,打一个形象的比方,深度学习框架是一条高速公路,你可以免费在上面行驶,但你也需要服务区加油、吃饭、休息,这一连串的配套设施就形成了一个生态。
经过4年开源发展,百度飞桨已经筹备起了自己的生态模型,在完备性、易用性、高效性三个方面搭建了一定的壁垒。
完备性:
百度飞桨集核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,并根据本土化特点将开源框架与应用层面做了更好的结合,旨在打造自主可控的人工智能操作系统,持续赋能广大开发者。2020 年也迎来一系列重要升级,比如在核心框架上实现了动静统一,全面支持动态图调试,自动转静态图训练和部署的理想开发模式。
易用性:
相比于其他开源的深度学习框架,飞桨最大的特点在于easy to use,对很多算法进行了完整封装,开发者只需要略微了解下源码原理,导入自己的数据就可以执行运行的命令。
高效性:
基于其简洁、灵活、快速的特性,百度飞桨推动了各个行业的深度学习应用,在液晶显示屏的检测、机器人安全巡检、遥感监测等领域发挥着不可代替的作用。
拿液晶显示屏检测来说,精测电子应用飞桨开源深度学习框架开发后,基于其分类、检测、分割等多种功能模块,对具有缺陷的液晶屏幕检测的精度上有很大提升。
解远虑:国家新基建战略下的自主创新
近两年,基础技术的「卡脖子」话题成为近两年中国科技界探讨的热点,担心中国AI的发展会像芯片发展那样遭遇空中楼阁的困境。
与其信任他人「不作恶」的承诺,不如技术自立。
一定程度上,华为中兴事件之后,人工智能竞赛已经演化成一场「框架之争」。以高文院士为代表的AI专家就在四处布道「做人工智能必须要做开源,中国要想发展好新一代的人工智能,必须要有高效和风险可控的开源开放平台」的观点。
与此同时,国家也在战略层面给予支持。
对于AI基础设施的建设,中国政府在《新一代人工智能发展规划》等关于AI顶层规划的政策中都着重提及,除了加大应用层技术落地,更希望业界和学界深入AI底层技术研发。
而AI底层技术研发的根基就在深度学习框架,跑在自家的高速公路上,不会有被拦路、断供的风险,而且在生态建设层面,自研深度学习框架的成熟度并不亚于TensorFlow或PyTorch。
以百度飞桨为例,数据显示,飞桨当前支持140+个产业及开源算法,累计开发者230万,服务企业9万家,基于飞桨开源深度学习平台产生了31万个模型。今年9月,百度飞桨深度学习平台还入选了2020服贸会「科技创新服务示范案例」。
此外,在城市、工业、电力、通信等很多关乎国计民生的领域都有飞桨在发挥作用。
今年5月,百度发布了Paddle Quantum,这是建立在百度飞桨深度学习平台之上的开放源代码的机器学习工具包,它包括量子开发工具集,量子化学库以及一系列优化工具,可以帮助领域内的科研人员以及开发者在量子计算应用程序中训练和开发AI,也为相关领域的爱好者开发量子人工智能的应用提供了强有力的支撑。
百度「开源」家族
在技术领域,一枝独秀不是春,没有对外开源,很多技术和产品不会拓展如此之快。还是高速公路的例子,在别人为你搭建好的公路上驰骋,相当于站在巨人的肩膀上做创新,不仅加速了自我产品迭代,更有助于AI技术生态的构建。
信奉技术的巨头都甚至「开源」的重要性,百度更是如此。
从2009年大规模定制Hadoop到2013年率先开源ECharts,百度的开源之路从未停止。
2017年,对百度而言是开源的突破之年,从深度学习平台飞桨 PaddlePaddle,到Apollo自动驾驶,百度落实了多项重大开源技术,也将AI开源提升到前所未有的战略高度。
2016年开源飞桨后,次年百度发布全球首个自动驾驶Apollo自动驾驶开放平台。
截至目前,百度Apollo平台已经汇聚了全球177家生态合作伙伴。在全球,有97个国家超过3.6万名开发者使用Apollo开源代码,开源代码数量超过56万,Apollo自动驾驶平台已成为全球最强大、最开放、最活跃的自动驾驶平台。
除了飞桨和Apollo,疫情期间从红到白、可视化的疫情地图背后还有早已开源的ECharts身影。
作为当前最流行、最强大的可视化库之一,ECharts提供了直观、生动、可交互、可个性化定制的数据可视化图表,包括常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、treemap、旭日图,多维数据可视化的平行坐标,还有用于BI的漏斗图,仪表盘。
ECharts创新的拖拽重计算、数据视图、值域漫游等特性大大增强了用户体验,赋予了用户对数据进行挖掘、整合的能力。
通过ECharts的数据可视化图表可以直观、生动的展现数据
目前,Apache ECharts (incubating) 在Github中的star数已经超过41.4k,每周npm下载量超过22万。
除了自身开源,百度还参与了国内外顶级开源基金会和组织,成为了 Apache基金会、Linux基金会以及云原生计算基金会的金牌会员,其旗下Echarts、Doris、Brpc等多个项目已经成为Apache基金会孵化项目,Baetyl、IME、EDL 等项目也捐赠给了Linux基金会进行孵化。
2019年,百度战略投资了开源中国,作为中国最大的开源技术社区,开源中国旗下运营的Gitee代码托管平台是全球仅次于GitHub的代码托管平台,每日约增加5000名开发者、200家企业客户、1.7万代码仓库,已经具备了在国际市场与GitHub全面抗衡的基础。
诺贝尔奖得主理查德费曼曾说过,what you can not create, you can not understand,不会创造出来就不理解。
深度学习框架也一样,只会使用,不会研发,就不会理解。不理解,不仅仅是能不能研发出来深度学习框架的问题,也意味着不能在算法上领先,不能在芯片上领先,最终会导致在应用层面也不能领先,结局只能是全面的落后。
实际上,包括百度在内,腾讯、阿里、华为等科技巨头纷纷将AI框架开源的道理也在此。开源,某种程度上能有效减少闭源垄断市场的局面出现,同时,还能在根本上解决「卡脖子」的窘迫。
开源深度学习框架意味着,在语音识别、自然语言理解、计算机视觉、广告等很多地方可以应用,同时,例如百度这样的领航者也提供了深度学习算法之外,海量数据收集和工程系统架构的搭建,为AI开发者提供了一站式服务。
总的来说,开源对于中国本土的AI开发者和公司来说,有能力理解并基于一个与国际同步的深度学习框架开发AI技术、应用,这将大大降低深度学习在各个行业中的应用难度。
正如李彦宏在2020百度世界大会上提到,推动人工智能扎实渗透,行业要充分利用开源、开放平台,它在人工智能发展当中的作用会越来越受到重视。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

