声纹识别:比面容、指纹识别更精准
除了指纹识别、面容识别,你还能想到什么生物识别方法呢?没错!就是声纹识别。虽然声纹识别一直非常低调,但也不能否认它是人工智能领域的又一黑科技。语音识别并不是声纹识别▲ 设置Siri时的声纹识别声纹识别听上去好像很高级,其实不少小伙伴的手机里就有这个功能哦

除了指纹识别、面容识别,你还能想到什么生物识别方法呢?没错!就是声纹识别。虽然声纹识别一直非常低调,但也不能否认它是人工智能领域的又一黑科技。
语音识别并不是声纹识别

▲ 设置Siri时的声纹识别
声纹识别听上去好像很高级,其实不少小伙伴的手机里就有这个功能哦。小黑以iPhone为例,当你开启Siri语音助手时,系统会先让你读出一些特定的句子。这个步骤就是为了识别你的声纹,以免其他人可以唤醒你的Siri。
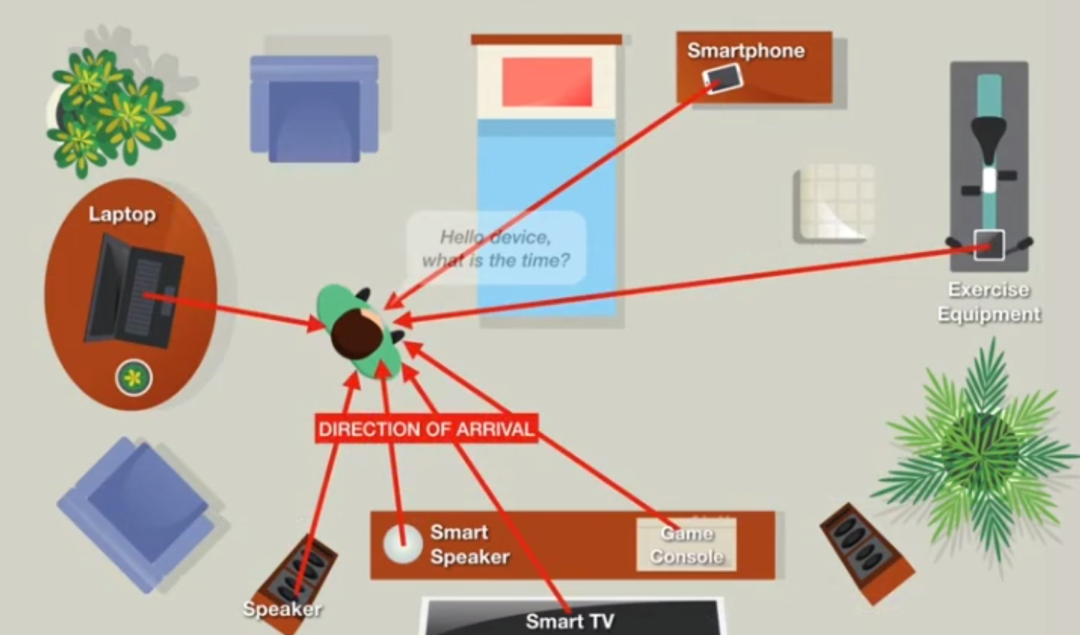
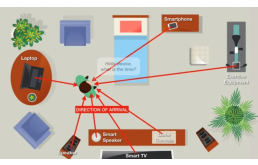
▲ 通过声音可控制许多智能家居
现在很多智能家居都可以通过声音来操控,比如用小爱音箱来开关灯具,或者对智能电视发出指令来调换频道等。于是就会有许多小伙伴认为,这也是声纹识别。其实目前大多数的声音操控都属于语音识别。
简而言之,语音识别是为了识别语音中的内容,并用AI自动将我们说出的话转换成相应的文字。而声纹识别可以识别出说话人的身份,实现“一对一”语音控制。因此,声纹识别不注重语音信号的语义,而是从语音信号中提取个人声纹特征,挖掘出包含在语音信号中的个性因素。
声纹识别究竟特别在哪里?
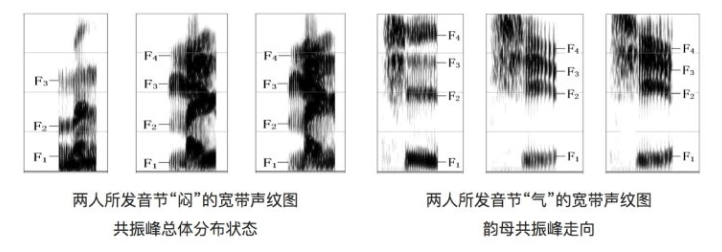
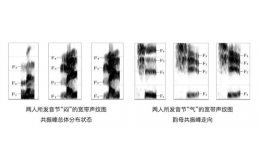
我们平时在说话时的发声器官在尺寸和形状方面每个人的差异都很大,所以任何两个人的声纹图谱都不可能相同。声纹识别也正是通过这个特点来通过对比语音的相同音素上的发声来判断声音是否属于同一个人。
声纹识别基于语音中所包含的说话人特有的个性信息,再利用计算机以及现有的识别技术,自动鉴别当前语音对应的说话人身份。声纹识别系统包含了说话人模型训练和测试语音识别两个阶段。
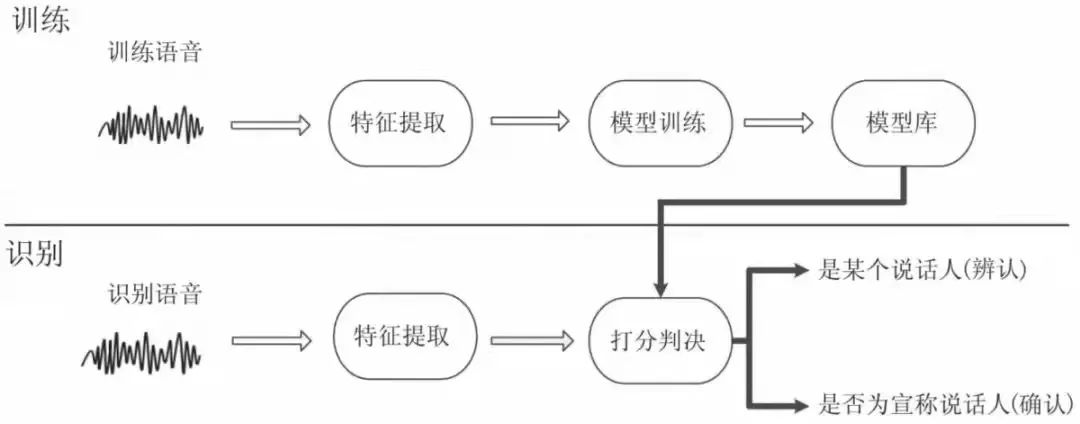
▲ 声纹识别的系统框架
训练阶段:对使用系统的说话人预留了充足的语音,并对不同说话人的语音提取声学特征,然后根据每个说话人的语音特征,训练得到对应的说话人模型,最终将全体说话人模型集合在一起组成系统的说话人模型库。
识别阶段:说话人进行识别认证的时候,系统对识别语音进行相同的特征提取,并将语音特征与说话人模型库进行比对,得到对应说话人模型的相似性打分,最后根据识别打分,判断说话人身份。

▲ 指纹和面容识别无法做到无感知
和指纹识别相比,声纹识别技术可以做到无感知、无接触。你不需要用手指触摸很多人留下细菌的指纹识别设备。而相比于面容识别,特别在人人都戴口罩的特殊时期,不用摘下口罩依然可以利用声纹来辨别信息。
哪些场景会运用到声纹识别?
其实当今远程交互方式变得越来越多,在一些特定的智能场景中,是没有办法通过指纹或是面容来进行识别的,那么声纹识别就成为了唯一可以识别我们身份的技术。既然声纹识别这么厉害,它可以被运用到哪些场景中呢?
大家应该都在银行的电话客服上面办过业务吧,每一次都要报出身份证、手机号等一系列能够证明自己身份的信息。但如果声纹识别未来得到普及,银行就可以通过声纹来辨别身份,无论是电话还是网上都能够轻松办理业务了。
当然,社保局也可以运用声纹识别防止养老金被冒领。毕竟许多老人对于人工智能、生物识别并不很了解,而声纹识别只用通过声音,哪怕本人无法到达现场,也可以通过电话进行远程身份确认。
声纹识别还可以运用到火车、飞机的安检流程中,有效的对危险人物进行识别和提示。对于电话诈骗、刑事案件也有很大的帮助,公安司法人员可以通过声纹识别来锁定嫌犯或缩小侦查范围。
不过,声纹识别的缺点也十分明显,对环境的要求非常高,在嘈杂的环境混合说话下,声纹不易获取;人的声音也会随着年龄、身体状况、情绪等的影响而变化;不同的麦克风和信道对识别性能有影响等。

声纹识别作为最前沿的生物识别技术之一,未来一定会有更多有意义的使用场景,例如在操控智能音箱时,根据不同用户的声纹判断他们的使用习惯,来以此提供更人性化的服务。不过,小黑觉得想要达到真正的一对一声纹识别,人工智能还需要时间来学习。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

