技术:Python抓取百度贴吧评论区图片
【一、项目背景】 百度贴吧是全球最大的中文交流平台,你是否跟我一样,有时候看到评论区的图片想下载呢?或者看到一段视频想进行下载呢? 今天,小编带大家通过搜索关键字来获取评论区的图片和视频
【一、项目背景】
百度贴吧是全球最大的中文交流平台,你是否跟我一样,有时候看到评论区的图片想下载呢?或者看到一段视频想进行下载呢?
今天,小编带大家通过搜索关键字来获取评论区的图片和视频。
【二、项目目标】
实现把贴吧获取的图片或视频保存在一个文件。
【三、涉及的库和网站】
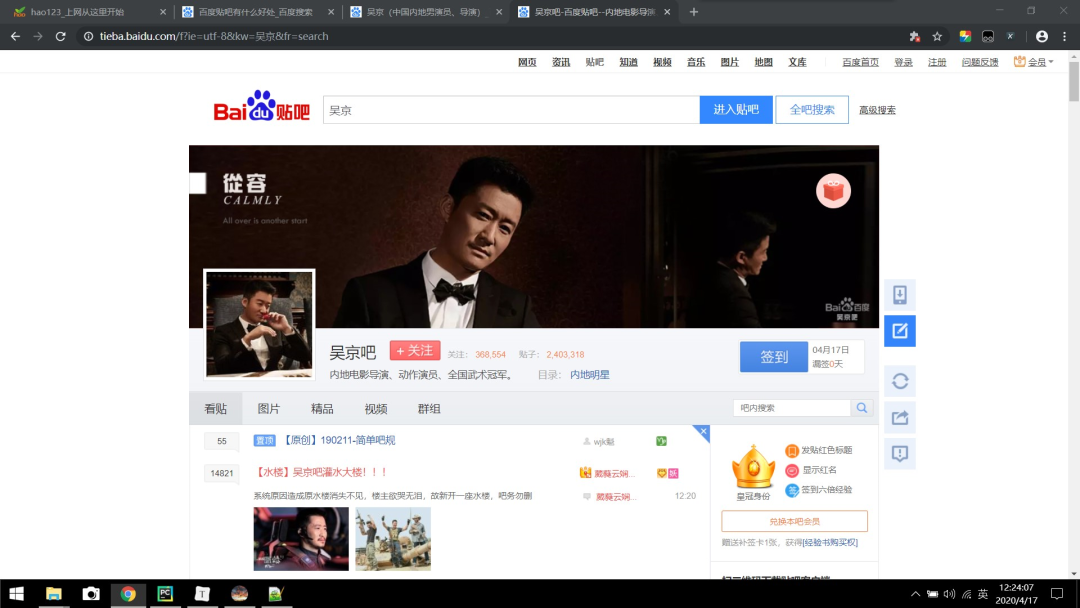
1、网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=吴京&fr=search
2、涉及的库:requests、lxml、urrilb
【四、项目分析】
1、反爬措施的处理
前期测试时发现,该网站反爬虫处理措施很多,测试到有以下几个:
1) 直接使用requests库,在不设置任何header的情况下,网站直接不返回数 据。
2) 同一个ip连续访问40多次,直接封掉ip,起初我的ip就是这样被封掉的。
为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决。
获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
2、如何实现搜索关键字?
通过网址我们可以发现只需要在kw=() ,括号中输入你要搜索的内容即可。这样就可以用一个{}来替代它,后面我们在通过循环遍历它。
【五、项目实施】
1、创建一个名为BaiduImageSpider的类,定义一个主方法main和初始化方法init。导入需要的库。import requestsfrom lxml import etreefrom urllib import parseclass BaiduImageSpider(object): def __init__(self, tieba_name): pass def main(self): passif __name__ == '__main__': inout_word = input("请输入你要查询的信息:")
spider.main() passif __name__ == '__main__': spider= ImageSpider() spider.main()
2、准备url地址和请求头headers 请求数据。import requestsfrom lxml import etreefrom urllib import parseclass BaiduImageSpider(object): def __init__(self, tieba_name): self.tieba_name = tieba_name #输入的名字 self.url = "http://tieba.baidu.com/f?kw={}&ie=utf-8&pn=0" self.headers = { 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)' }
'''发送请求 获取响应''' def get_parse_page(self, url, xpath): html = requests.get(url=url, headers=self.headers).content.decode("utf-8") parse_html = etree.HTML(html) r_list = parse_html.xpath(xpath) return r_list def main(self): url = self.url.format(self.tieba_name)if __name__ == '__main__': inout_word = input("请输入你要查询的信息:") key_word = parse.quote(inout_word) spider = BaiduImageSpider(key_word) spider.main()
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

