基于SQL的批流一体化ETL
转载本文需注明出处:微信公众号EAWorld,违者必究。本文介绍了 SparkSQL 和 Flink 对于批流支持的特性以及批流一体化支持框架的难点。在介绍批流一体化实现的同时,重点分析了基于普元 SparkSQL-Flow 框架对批流支持的一种实现方式
转载本文需注明出处:微信公众号EAWorld,违者必究。
本文介绍了 SparkSQL 和 Flink 对于批流支持的特性以及批流一体化支持框架的难点。在介绍批流一体化实现的同时,重点分析了基于普元 SparkSQL-Flow 框架对批流支持的一种实现方式。希望对大家的工作有所帮助,也希望能对 DatasetFlow 模型作为框架实现提供一些启发。
目录:
1.SparkSQL 和 Flink 对于批流支持的特性介绍
2.基于SparkSQL-Flow的批量分析框架
3.基于SparkStreaming SQL模式的流式处理支持
4.对于批流一体化ETL的思考
一、SparkSQL 和 Flink
对于批流支持的特性介绍
关于流和批的一些争论
对于广泛使用的Spark和新秀Flink,对于批和流实现方式上,以及在论坛和一些文章上,对批和流都有不同看法。批是流的特例 还是 流是批的特例?
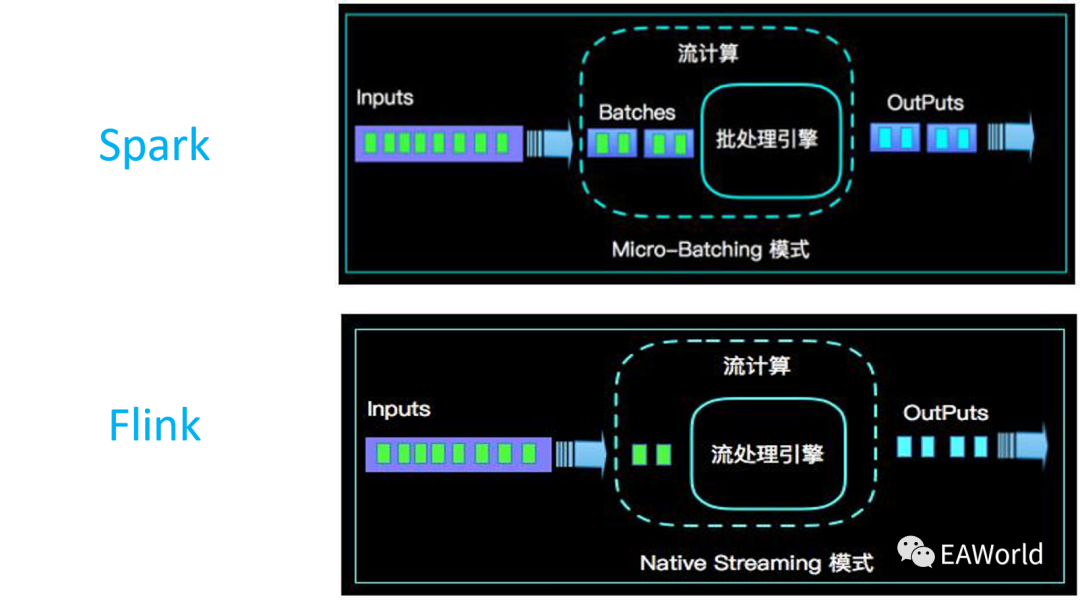
1.从批的角度看,流是多个批次一份一份的进行。无限个这样批次构成整个流处理流程,类如SparkStreaming的处理模式;
2.从流的角度看,批是流的有限流处理。它只不过在某个时间点,完成某个条件停止了而已;类如 Flink 的处理模式;
Spark 和 Flink 都具有流和批处理能力,但是他们的做法是截然相反。Spark Streaming是把流转化成一个个小的批来处理,这种方案的一个问题是我们需要的延迟越低,额外开销占的比例就会越大,这导致了Spark Streaming很难做到秒级甚至亚秒级的延迟。Flink是把批当作一种有限的流,这种做法的一个特点是在流和批共享大部分代码的同时还能够保留批处理特有的一系列的优化。数据仓库早期以及大数据早期都是从批处理开始的,所以很多系统都是从批处理做起,包括Spark。在批处理上Spark有着较深的积累,是一个比较优秀的系统。随着技术的发展,很多原来只有批处理的业务都有了实时的需求,流处理将会变得越来越重要,甚至成为一些数据分析的主要场景,如实时管控、预警相关。
Spark 和 Flink 的异同点
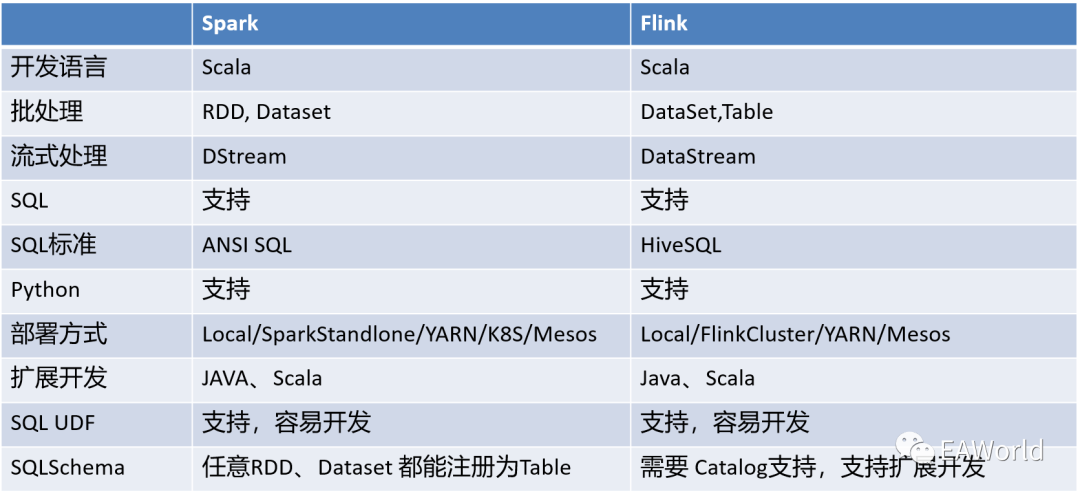
Flink 早期仅支持流式处理,这几年的Flink无论从API组织,还是运行方式,还是多样性都越来越像Spark。
批和流是数据融合的两种应用形态
传统的数据融合通常基于批模式。在批的模式下,我们会通过一些周期性运行的ETL JOB,将数据从关系型数据库、文件存储向下游的目标数据库进行同步,中间可能有各种类型的转换。
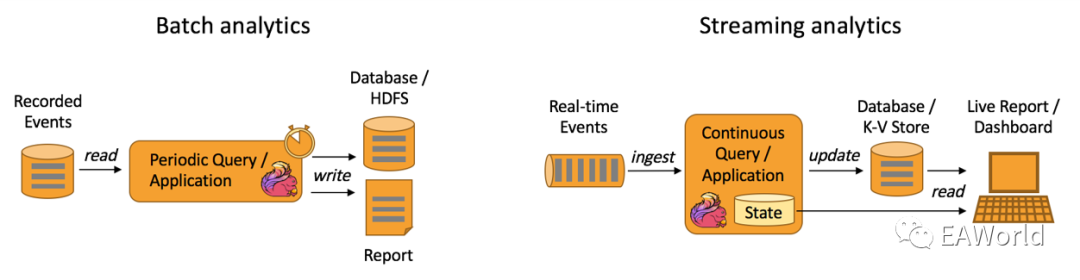
与批模式相比相比, 其最核心的区别是将批量变为实时:输入的数据不再是周期性的去获取,而是源源不断的来自于业务的日志、消息队列的消息。进而通过一个实时计算引擎,进行各种聚合运算,产生输出结果,并且写入下游。Spark 和 Flink 都能够支持批和流两种概念。只不过像 Flink,其原生就是为流而生,所以在流处理上更自然。
Spark 是有太多包袱,Spark 最早采用 RDD 模型,达到比 MapReduce 计算快 100 倍的显著优势,对 Hadoop 生态大幅升级换代。RDD 弹性数据集是分割为固定大小的批数据,自动容错、位置感知、本地计算、可调度可伸缩等众多重要特性。RDD 提供了丰富的底层 API 对数据集做操作,为持续降低使用门槛,Spark 社区开始开发高阶 API:DataFrame/DataSet,Spark SQL 作为统一的 API,掩盖了底层,同时针对性地做 SQL 逻辑优化和物理优化。Spark 早期的主要目标是替代 MapReduce,MapReduce 是大数据批处理的核心模型。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

