2020年10篇必读的NLP突破论文
尽管 2020 年是充满挑战的一年,但人工智能学术研究并未因此停滞,仍然诞生了许多有意义的技术突破。在 NLP 领域,OpenAI 的 GPT-3 可能是其中最 “出圈” 的,但除它之外,肯定还有很多其他研究论文值得关注
尽管 2020 年是充满挑战的一年,但人工智能学术研究并未因此停滞,仍然诞生了许多有意义的技术突破。在 NLP 领域,OpenAI 的 GPT-3 可能是其中最 “出圈” 的,但除它之外,肯定还有很多其他研究论文值得关注。
整体来看,2020 年的主要 NLP 研究进展仍以大型预训练语言模型为主,特别是 transformers。今年出现了许多有趣的更新,使得 transformers 架构更加高效,更适用于长文档。
另一个热点话题与 NLP 模型在不同应用中的评估有关。业界仍然缺乏普适的评估方法以清晰定义一个模型究竟哪里失败了,以及如何修复这些问题。
另外,随着 GPT-3 等语言模型能力的不断增强,对话式人工智能正受到新一轮的关注。聊天机器人正在不断改进,今年顶级技术公司推出的多款聊天机器人(例如 Meena 和 Blender 等)令人印象深刻。
在 2020 年年尾,国外 AI 技术博客 topbots.com 总结了 2020 年的 10 篇重要机器学习研究论文,入选论文也多为今年的顶会论文奖斩获者,具有较高的权威度,“数据实战派” 在此基础上有所延伸,以便让读者对今年的 NLP 研究进展有一个大致的了解,当然,名单之外,也仍有很多突破性的论文值得阅读。也欢迎读者后台留言与我们交流反馈。
2020 年 10 篇必读的 NLP 突破论文 LIST:
1.WinoGrande: An Adversarial Winograd Schema Challenge at Scale
2.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
3.Reformer: The Efficient Transformer
4.Longformer: The Long-Document Transformer
5.ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
6.Language Models are Few-Shot Learners
7.Beyond Accuracy: Behavioral Testing of NLP models with CheckList
8.Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics
9.Towards a Human-like Open-Domain Chatbot
10.Recipes for Building an Open-Domain Chatbot
1、WinoGrande 挑战

WSC 挑战是一个人类常识推理的测评集。它包含了 273 个由专家设计的问题,这些问题无法单纯依靠统计模型来解决。但是,最近的语言模型在这个测试集上取得了 90% 的准确率。这就提出了一个问题,即语言模型是真正学会了推理,还是仅仅依靠一些对数据集的偏好?
为回答这个问题,华盛顿大学艾伦人工智能研究所的一支团队提出了一个新的挑战 ——WINOGRANDE,一个用于常识推理的新的大规模数据集。WINOGRANDE 是对 WSC 挑战的升级,同时增加了问题的难度和规模。
WINOGRANDE 的开发有两大关键:在众包设计过程中,众包人员需要写出符合 WSC 要求并包含某些 anchor words 的双句子,最终收集的问题会通过一组众包工作者进行验证。在收集的 77,000 个问题中,有 53K 被视为有效。
另一个关键在于研究人员开发用于系统减少偏差的新颖算法 AfLite,将出现的人类可检测偏差巧妙转换为了基于嵌入的机器可检测的偏差。应用 AfLite 算法后,去除偏见的 WinoGrande 数据集包含 44K 样本。
在 WINOGRANDE 测试集上,现在最好的方法只能达到 59.4 – 79.1% 的准确率,比人类表现(94.0%)低 15%-35%。
一句话总结现实影响:有助于探索减少系统偏差的新算法,并避开其他 NLP 基准的偏差。
这篇文章获得了 AAAI2020 的最佳论文奖 (Outstanding Paper Award)。
2、打造更强大的 Transformer
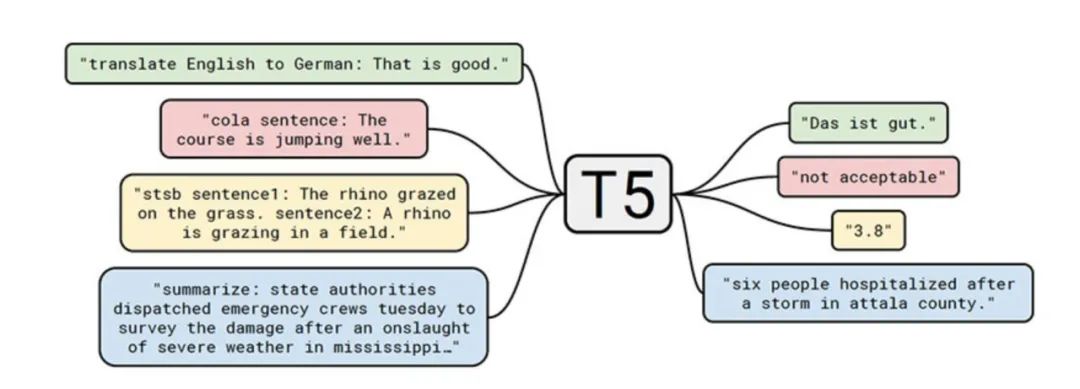
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 一文中,谷歌研究团队建议在 NLP 中采用统一的转移学习方法,目标是在该领域树立一个新的标准。为此,他们提出将每个 NLP 问题都视为一个 "文本到文本" 的问题,这样的框架将允许在不同的任务中使用相同的模型、目标、训练过程和解码过程,包括总结、情感分析、问题回答和机器翻译。
研究人员将他们为此打造的模型,称为文本到文本传输转化器 (Transfer Text-to-Text Transformer,T5),并在大量网络抓取数据的语料库上对其进行训练。
通过探索和比较现有的技术,T5 的诞生为 NLP 领域的发展提供一个全面的视角。特别是提出把每个 NLP 问题都当作文本到文本的任务来处理,为 NLP 的迁移引入了新的方法。由于在原始输入句子中添加了特定任务的前缀(例如,"将英语翻译成德语:","总结:"),T5 可以理解应该执行哪些任务。
伴随着 T5 的诞生,还有一个名为 C4 的数据集。研究团队从 Common Crawl(一个公开的网页存档数据集,每个月大概抓取 20TB 文本数据) 里整理出了 750 GB 的训练数据,取名为 “Colossal Clean Crawled Corpus (超大型干净爬取数据)”,用来训练 T5.
最终,文中提到的 24 个任务中,拥有 110 亿个参数的 T5 模型在 17 个任务上取得了最先进的性能,包括:GLUE 得分 89.7 分,在 CoLA、RTE 和 WNLI 任务上的性能大幅提升;在 SQuAD 数据集上的精确匹配得分 90.06 分;SuperGLUE 得分 88.9,比之前最先进的结果 (84.6) 有非常显著的提高,非常接近人类的表现 (89.8);在 CNN/Daily Mail 抽象总结任务中,ROUGE-2-F 得分 21.55。
一句话总结现实影响:即使该研究引入的模型仍具有数十亿个参数,并且可能过于笨重而无法在业务环境中应用,但是所提出的思想,仍有助于改善不同 NLP 任务的性能,包括摘要、问题回答和情感分析。
3、更高效的 Reformer

因为参数数量非常大、需要存储每一层的激活以进行反向传播、中间前馈层占内存使用的很大一部分等诸多原因,Transformer 模型需要大量的计算资源。
面对这样一个 “庞然大物”,往往只有大型研究实验室才有条件对其进行实际训练。
为了解决这个问题,谷歌的研究团队在 Reformer: The Efficient Transformer 一文中,介绍了几种可提高 Transformer 效率的技术。
特别是,他们建议,使用可逆层以仅对每个层而不是每个层存储一次激活,以及通过局部敏感散列来避免昂贵的 softmax 计算。在多个文本任务上进行的实验表明,该论文引入的 Reformer 模型可以与完整的 Transformer 的性能相匹配,但是运行速度更快,内存效率更高。Reformer 在表现出更高的速度和内存效率的同时,可以与完整的 Transformer 模型媲美,例如,在将机器从英语翻译成德语的 newstest2014 任务上,Reformer 基本模型的 BLEU 得分为 27.6 ,而 Transformer 的 BLEU 得分为 27.3 。
一句话总结现实影响:Reformer 实现的效率改进可以助推更广泛的 Transformer 应用程序,特别是对于依赖于大上下文数据的任务,例如文字生成、视觉内容生成、音乐的产生、时间序列预测。
该论文被选为 ICLR 2020 的 oral presentation 。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

