Python+PCA+SVM:实现人脸识别模型
在本文中,我们将使用主成分分析和支持向量机来建立人脸识别模型。首先,让我们了解PCA和SVM是什么:主成分分析:主成分分析(PCA)是一种机器学习算法,广泛应用于探索性数据分析和建立预测模型,它通常用于降维,通过将每个数据点投影到前几个主成分上,以获得低维数据,同时尽可能保留数据的变化

在本文中,我们将使用主成分分析和支持向量机来建立人脸识别模型。
首先,让我们了解PCA和SVM是什么:
主成分分析:主成分分析(PCA)是一种机器学习算法,广泛应用于探索性数据分析和建立预测模型,它通常用于降维,通过将每个数据点投影到前几个主成分上,以获得低维数据,同时尽可能保留数据的变化。
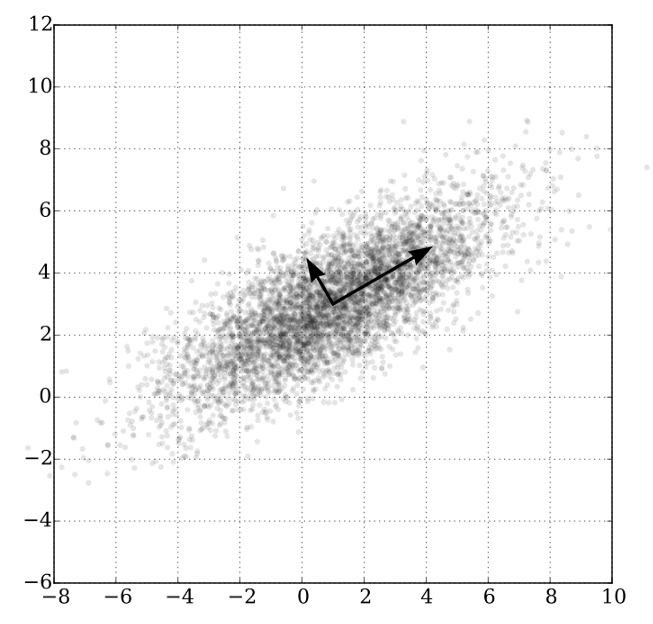
Matt Brems的文章全面深入地介绍了该算法。现在,让我们用更简单的术语来理解算法:假设我们现在正在收集数据,我们的数据集产生了多个变量、多个特征,所有这些都会在不同方面影响结果。我们可能会选择删除某些特征,但这意味着会丢失信息。因此我们开源使用另一种减少特征数量(减少数据维数)的方法,通过提取重要信息并删除不重要的信息来创建新的特征,这样,我们的信息就不会丢失,但起到减少特征的作用,而我们模型的过拟合几率也会减少。支持向量机支持向量机(SVM)是一种用于两组分类问题的有监督机器学习模型,在为每个类别提供一组带标签的训练数据后,他们能够对新的测试数据进行分类。
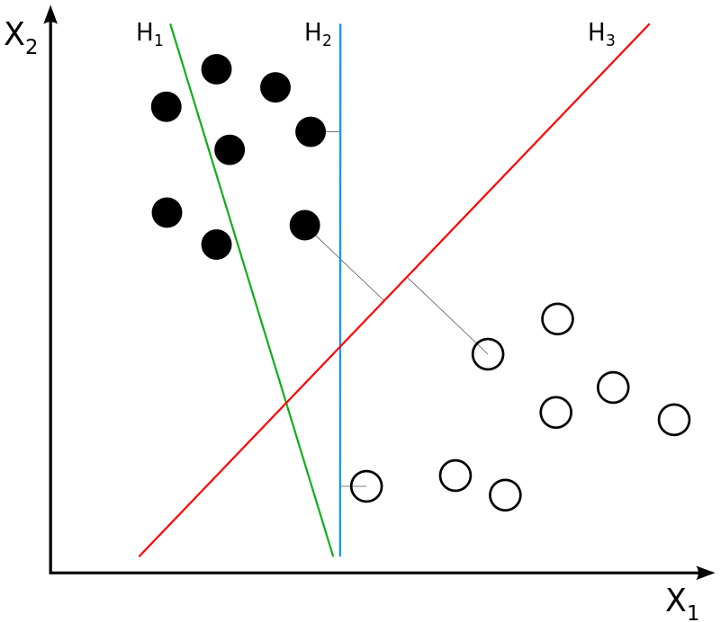
支持向量机基于最大化间隔的平面对数据进行分类,决策边界是直的。支持向量机是一种很好的图像分类算法,实验结果表明,支持向量机在经过3-4轮相关优化后,其搜索精度明显高于传统的查询优化方案,这对于图像分割来说也是如此,包括那些使用改进的支持向量机。Marco Peixeiro的文章解释了需要有一个最大间隔超平面来分类数据,开源帮助你更好地理解SVM!人脸识别人脸是由许多像素组成的高维数据。高维数据很难处理,因为不能用二维数据的散点图等简单技术进行可视化。我们要做的是利用PCA对数据的高维进行降维处理,然后将其输入到SVM分类器中对图像进行分类。下面的代码示例取自关于eigenfaces的sklearn文档,我们将一步一步地实现代码,以了解其复杂性和结果。导入相关库和模块首先,我们将导入所需的库和模块,我们将在后文深入讨论我们为什么要导入它们。import pylab as pl
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.svm import SVC
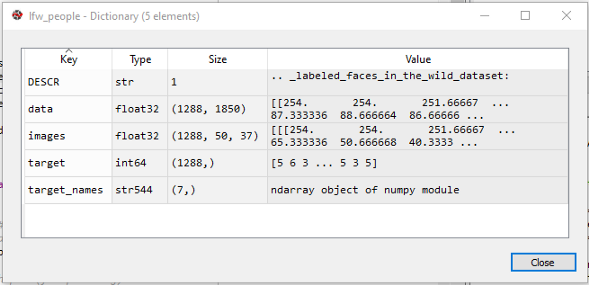
将数据加载到Numpy数组中接下来,我们将数据下载到磁盘中,并使用fetch_lfw_people将其作为NumPy数组加载到sklearn.datasetslfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
lfw数据集包括一个用于研究无约束人脸识别问题的人脸图像数据库,它从网络收集的13000多张照片中包含了超过13000张照片,每个人脸都贴上了照片,1680个人脸在数据集中有两张或两张以上不同的照片。图像采用灰度值(像素值=0-255)。
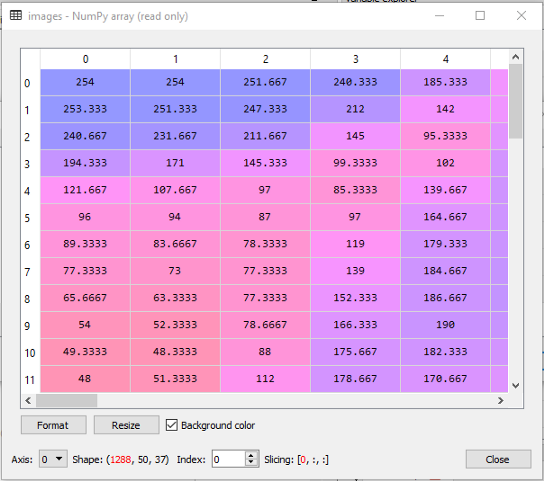
图像Numpy数组接下来,我们将寻找图像数组图片的形状。我们使用NumPy shape属性,该属性返回一个元组,每个索引都有对应元素的数量。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

