如何构建和部署机器学习web应用程序?
本文我将带领大家构建一个Web应用程序以对榴莲进行分类,在这里(https://durian-classifier.herokuapp.com/) 可以查看相关信息。如果你不知道榴莲是什么,那我向你说明一下
本文我将带领大家构建一个Web应用程序以对榴莲进行分类,在这里(https://durian-classifier.herokuapp.com/) 可以查看相关信息。
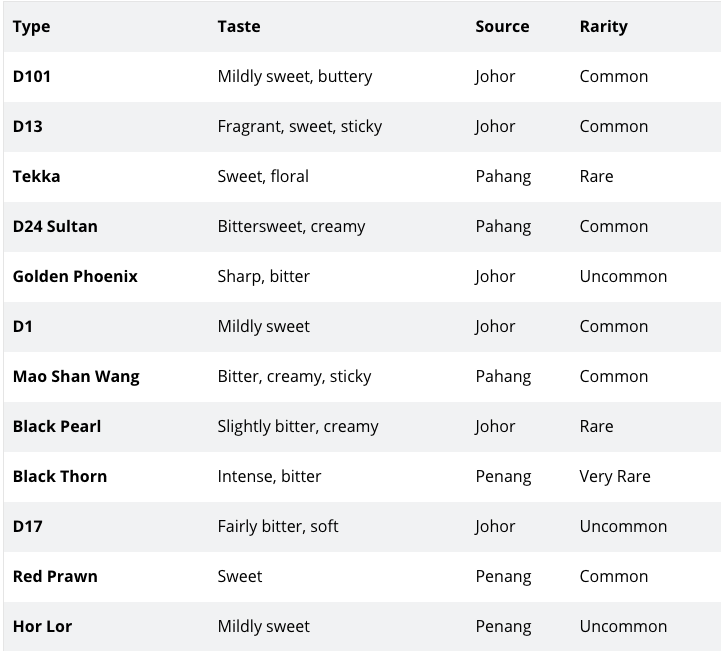
如果你不知道榴莲是什么,那我向你说明一下。它是一种质地乳脂状、气味刺鼻(见下图)和外表刺眼的水果(在新加坡我们称之为水果之王),这意味着刺鼻的气味让人要么讨厌它,要么绝对喜欢它(很明显,我属于后者)。如果你觉得它闻起来很香,那么它的味道可能会更好。问题陈述是的,这个项目的动力源于我对榴莲的热爱。你一定想知道,我们到底在分类什么?你会发现,榴莲有很多种,它们的味道、质地和颜色各不相同。对于此项目,我们将对四种不同类型的榴莲进行分类,即:猫山王金凤凰D24红虾下表总结了这些榴莲的不同之处:
榴莲的品种还有很多,但我认为这些榴莲的细微差别可能会让我们的模型难以学习。数据收集每个项目都从数据收集开始。由于我们将部署的模型用于个人和教育目的,因此我们将从google获取图像,如果你将图片用于其他用途,请检查版权。我们将使用此API(https://github.com/ultralytics/google-images-download) 来获取图像。只需按照repo上的说明安装软件包。在说明的第3步中,我们将针对特定的用例运行此命令(将路径替换为chromedriver):python3 bing_scraper.py --url 'https://www.bing.com/images/search?q=mao+shan+wang' --limit 100 --download --chromedriver <path_to_chromedriver>在这里,我们将下载的图片数量限制在100张,因为没有多少具体的“猫山王”图片。我们重复以上步骤三次,用其他品种的榴莲进行搜索。请注意,由于我们在API中修改了搜索URL,查询中的空格将替换为“+”(即mao+shan+wang,red+prawn+durian等)。当然,你可以对任何要分类的图像执行此步骤。数据清理在我们的用例中,由于没有公开的榴莲图像,因此下载的许多图像可能与正确的榴莲品种不符(例如,在搜索“ mao shan wang”时可能会找到通用的“未标记”榴莲) )。
因此,我需要手动检查所有下载的图像,以确保图片的质量,毕竟拥有高质量(即正确标记)的数据胜过大数量的数据,对吧?此步骤确实需要一些领域知识,并且可能会花费一些时间。(但是,数据清理是机器学习管道中的基本步骤,反映了数据科学家和AI工程师的实际情况。)清除数据后,剩下55张 D24、39张金凤,59张猫山王和68张红虾图像。训练榴莲分类器我选择使用TensorFlow框架,我相信大多数实践者都已经熟练使用了(当然,可以随意使用Pytorch)。
由于我们只有很少的图像,我们无疑必须使用一个预先训练好的模型,并在我们的数据集上对其进行微调。首先,确保你有下面的文件夹结构,这是之后使用 flow_from_directory 所必需的。train|-- d24|-- golden-phoenix|-- mao-shan-wang|-- red-prawnvalid|-- d24|-- golden-phoenix|-- mao-shan-wang|-- red-prawn让我们开始构建分类器!# Import relevant libraries we will be usingimport numpy as np
from tensorflow.keras.initializers import glorot_uniformfrom tensorflow.keras.regularizers import l2from tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom tensorflow.keras.applications import Xceptionfrom tensorflow.keras.layers import ( Flatten, Dense, AveragePooling2D, Dropout)from tensorflow.keras.optimizers import SGDfrom tensorflow.keras.preprocessing import imagefrom tensorflow.keras import Modelfrom tensorflow.keras.preprocessing.image import img_to_arrayfrom tensorflow.keras.callbacks import ( EarlyStopping, ModelCheckpoint, LearningRateScheduler)如上所示,我们将使用的基本模型是Xception,让我们实例化它并添加一些全连接层。因为我们有很多图像,所以我们将使用较小的批处理大小8。我们还需要警惕我们的小型数据集过度拟合。SHAPE = 224BATCH_SIZE = 8
model = Xception( input_shape=(SHAPE, SHAPE, 3), include_top=False, weights='imagenet')
x = model.outputx = AveragePooling2D(pool_size=(2, 2))(x)x = Dense(32, activation='relu')(x)x = Dropout(0.1)(x)x = Flatten()(x)x = Dense(4, activation='softmax', kernel_regularizer=l2(.0005))(x)
model = Model(inputs=model.inputs, outputs=x)
opt = SGD(lr=0.0001, momentum=.9)model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])在此之后,让我们使用TensorFlow的ImageDataGenerator及其flow_from_directory创建图像生成器对象。由于我们没有足够的训练图像,图像增强比以往任何时候都更重要。train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=15, width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
valid_datagen = ImageDataGenerator( rescale=1./255, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, horizontal_flip=False)
train_generator = train_datagen.flow_from_directory( 'train/', target_size=(SHAPE, SHAPE), shuffle=True, batch_size=BATCH_SIZE, class_mode='categorical',)
valid_generator = valid_datagen.flow_from_directory( 'valid/', target_size=(SHAPE, SHAPE), shuffle=True, batch_size=BATCH_SIZE, class_mode='categorical',)
>>> Found 178 images belonging to 4 classes.>>> Found 42 images belonging to 4 classes.让我们在.fit()即我们的模型之前定义一些回调函数。earlystop = EarlyStopping(monitor='val_loss', patience=4, verbose=1)
checkpoint = ModelCheckpoint( "model-weights/xception_checkpoint.h5", monitor="val_loss", mode="min", save_best_only=True, verbose=1)我们的模型终于开始训练了!history = model.fit_generator( train_generator, epochs=30, callbacks=[earlystop, checkpoint], validation_data=valid_generator)
# Save our model for inferencemodel.save("model-weights/xception.h5")
不幸的是,由于我们拥有的图像数量有限,我们的模型在验证集上无法获得非常好的准确性,但是,模型微调并不是本文的重点,因此我们不会对此进行过多介绍。选择我们的Web框架在这个项目中,我选择使用streamlit(https://www.streamlit.io/) ,因为它可以实现机器学习应用程序的超快速可视化,并且科可以方便地用Python编写。建立好这些之后,剩下要做的就是部署它。首先,导入所需的库并指定模型权重的路径,同样由于我们使用了flow_from_directory ,TensorFlow按字母顺序分配类编号,因此,D24将为0类,依此类推。import numpy as np
from PIL import Imagefrom tensorflow.keras.models import load_modelfrom tensorflow.keras.preprocessing.image import img_to_arrayfrom tensorflow.keras.preprocessing import imageimport streamlit as st
PATH = "model-weights/"WEIGHTS = "xception.h5"CLASS_DICT = { 0: 'D24', 1: 'JIN FENG', 2: 'MAO SHAN WANG', 3: 'RED PRAWN'}
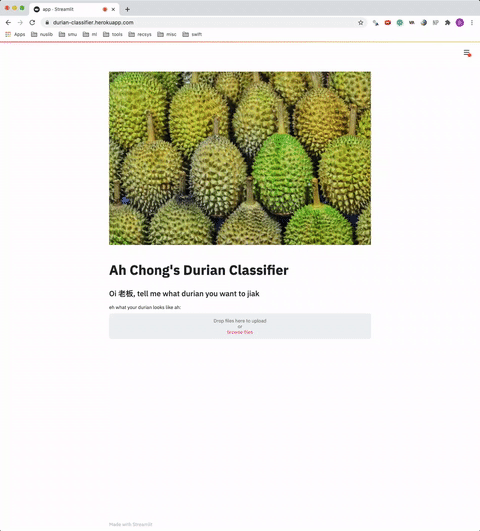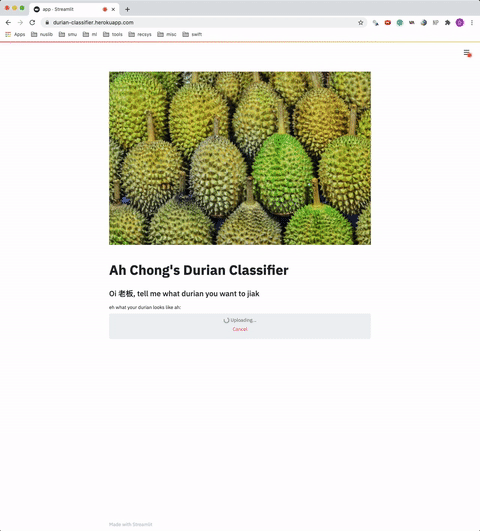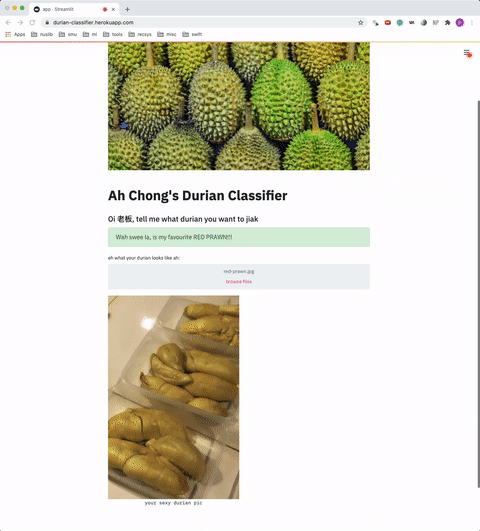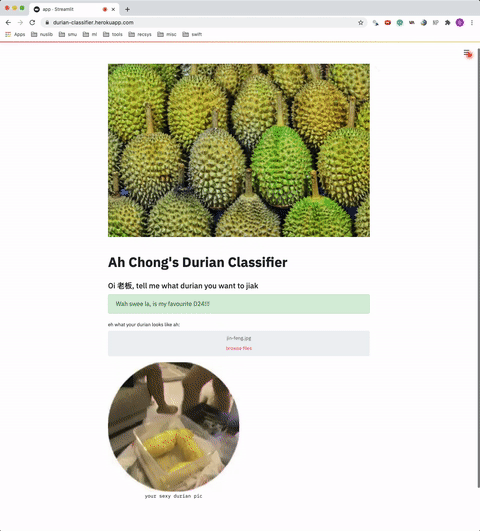
接下来,我们创建一个函数,将上传的图像转换为模型要使用的格式。我们使用PIL中的Image类,因为上传的图像是BytesIO格式的。def load_img(input_image, shape): img = Image.open(input_image).convert('RGB') img = img.resize((shape, shape)) img = image.img_to_array(img) return np.reshape(img, [1, shape, shape, 3])/255Streamlit的工作方式是,用户指定参数的每一次更改,脚本都会从上到下重新运行(因此它是交互式的UI),因此它以st.cache形式提供了一个缓存装饰器来缓存加载的对象。缓存通常用于数据加载步骤或任何需要长时间计算/处理的步骤。
请记住,我们使用allow_output_variation=True参数,因为默认情况下这是False,如果输出对象以任何方式发生了变化,则应用程序将被重新加载。在我们的例子中,模型对象将在每次预测中发生变化,因此我们将 allow_output_variation的参数设置为True。我们之所以要缓存我们的模型是因为我们不希望每次用户选择不同的图像时都加载它(即只加载一次模型)。@st.cache(allow_output_mutation=True)def load_own_model(weights): return load_model(weights)最后,我们只需要向UI添加一些代码即可:if __name__ == "__main__": result = st.empty() uploaded_img = st.file_uploader(label='upload your image:') if uploaded_img: st.image(uploaded_img, caption="your sexy durian pic", width=350) result.info("please wait for your results") model = load_own_model(PATH + WEIGHTS) pred_img = load_img(uploaded_img, 224) pred = CLASS_DICT[np.argmax(model.predict(pred_img))] result.success("The breed of durian is " + pred)我们用Python创建的web应用程序不需要太多的代码行。你可以确保它(假设它会被调用应用程序副本)可以通过在命令行中输入以下命令在本地运行:streamlit run app.py将我们的模型部署到Heroku就我个人而言,部署不是我最喜欢的部分,但是,如果web应用程序不在web上,那它还有什么意义呢?我们开始吧。你可以通过多种方式为web应用程序提供服务,也可以使用许多云服务提供商来托管它。在这种情况下,我选择使用Heroku主要是因为我以前没有尝试过。
什么是Heroku?
Heroku是一个云平台即服务(PaaS),支持多种编程语言,允许开发人员完全在云中构建、运行和操作应用程序。下面这篇文章解释得很清楚。文章链接:https://devcenter.heroku.com/articles/how-heroku-works在Heroku部署为了部署应用程序,我们总是需要某种版本控制,以确保我们的应用程序运行在一个不同的服务器上,而不是在本地计算机上。为此,许多人使用Docker容器,指定所需的可运行应用程序和包。
使用Heroku进行部署类似于同时使用Docker容器和web托管服务,但是,它使用Git作为部署应用程序的主要手段。我们不需要将所有必需的文件打包到Docker容器中,而是创建一个用于版本控制的git存储库,然后我们可以使用熟悉的git push,但是要用到heroku远程。Heroku随后使用了相同的容器技术,以dyno的形式进行。每个应用程序都放在一个dyno(或容器)中,每个应用程序都消耗“dyno hours”。每个Heroku帐户都有一些可用的空闲小时数,消耗的小时数取决于应用程序的活动/流量。
如果你的应用程序不需要大量流量,那么免费套餐应已足够了。另外值得注意的是,当Heroku接收到应用程序源时,它会启动应用程序的构建(例如在requirements.txt创建必要的资产等),被组装成一个slug。术语解释:slug是源代码、获取的依赖项、语言运行时和编译生成的系统输出的捆绑包—为执行做准备。要在Heroku上部署,我们需要以下文件:(1)setup.sh创建必要的目录并将一些信息(例如端口号)写入.toml文件mkdir -p ~/.streamlit/
echo "[server]headless = trueport = $PORTenableCORS = false\n" > ~/.streamlit/config.toml(2) Procfile类似于Dockerfile,包含我们要执行的指令。我们将首先在setup.sh中执行一些bash命令,然后执行streamlit run app.py命令。web: sh setup.sh && streamlit run app.py(3) requirements.txt包含应用程序所需的所有包依赖项。请注意,这些是我正在使用的版本。你可以通过终端中的conda list或使用pip freeze > requirements.txt获取环境当前使用的软件包的详尽列表。numpy==1.18.1spacy==2.2.4pandas==1.0.1Pillow==7.1.2streamlit==0.61.0tensorflow-cpu==2.2.0我们的文件夹目录应如下所示:app.pyProcfileREADME.mdrequirements.txtsetup.shmodel-weights|-- xception.h5如果你以前从未创建过Github存储库,请按照以下一些简单步骤进行操作:创建一个新的存储库<repo_name>

复制红色框中的URL
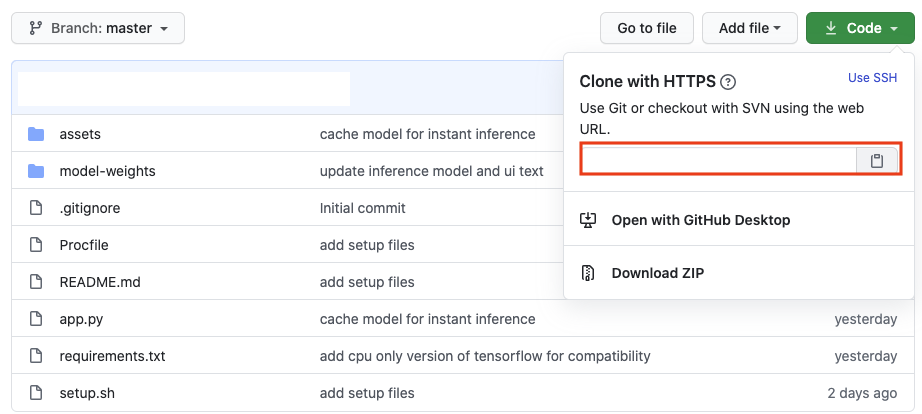
在终端上,运行以下命令:# Clone the repository into our local machinegit clone <repo URL in step 2>
# Enter the directory we just clonedcd <repo_name>将之前创建的文件复制到此文件夹中,然后在终端中运行以下命令:# Add all the files we just copied over to be committedgit add .
# Commit the files, along with a commit messagegit commit -m "deploy app"
# Push to master branch on our github repogit push origin master我们就快到了!这是最后的步骤。
(1)创建一个Heroku帐户并进行验证
(2)在此处(https://devcenter.heroku.com/articles/heroku-cli) 安装Heroku CLI
(3)通过终端登录到你的Heroku帐户。将打开一个浏览器窗口,供你进行身份验证。heroku login
(4)创建一个Heroku应用heroku create <project-name>完成此步骤后,你将能够在终端中看到指向你的项目的链接。
(5)将git repo推送到Heroku遥控器。在我们的github存储库的同一目录中,运行以下命令:git push heroku master我们完成了!构建完成后,你应该能够在上面的链接中看到部署的应用程序!

相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

