综合指南:postgresql shared buffers
综合指南:postgresql shared buffers本文主要针对下面问题详述PG的共享内存:PG中需要给共享内存分配多少内存?为什么?非常奇怪,为什么我的RDS PG需要使用系统RAM的25%
综合指南:postgresql shared buffers
本文主要针对下面问题详述PG的共享内存:PG中需要给共享内存分配多少内存?为什么?
非常奇怪,为什么我的RDS PG需要使用系统RAM的25%,而Aurora的PG却需要分配75%?
理解PG中的共享内存及操作系统的缓存
首先提出个问题:PG中的bgwriter进程是干什么的?
如果回答是将脏页刷到磁盘的,那这就错了。他仅仅将脏页刷写到操作系统的缓存,然后由操作系统调用sync将操作系统缓存刷写到磁盘。有点迷惑?那么接着我们说道说道。
由于PG轻量的特性,他高度依赖操作系统缓存,通过操作系统感知文件系统、磁盘布局以及读写数据文件。下图帮助了解数据如何在磁盘和共享缓存之间流动。
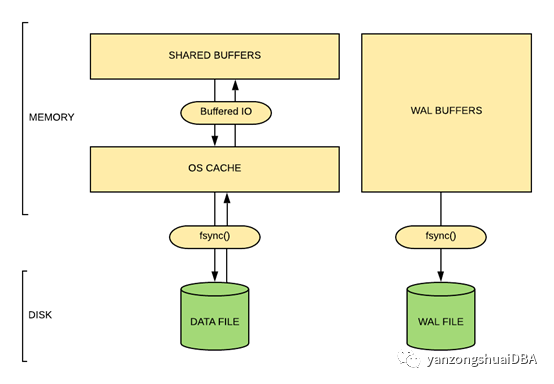
因此当发起“select *from emp”时,数据会加载到操作系统缓存然后才到shared buffer。同样当将脏页向磁盘刷写时,也是先到操作系统缓存,然后由操作系统调用fsync()将操作系统缓存中数据持久化到磁盘。这样PG实际上由两份数据,看起来有些浪费空间,但是操作系统缓存是一个简单的LRU而不是数据库优化的clock sweep algorithm。一旦在shared_buffers中命中,那么读就不会下沉到操作系统缓存。如果shared buffer和操作系统缓存有相同页,操作系统缓存中的页很快会被驱逐替换。
我能影响操作系统的fsync将脏页刷回磁盘吗?
当然,通过postgresql.conf中参数bgwriter_flush_after,该参数整型,默认512KB。当后台写进程写了这么多数据时,会强制OS发起sync将cache中数据刷到底层存储。这样会限制内核页缓存中的脏数据数量,从而减小checkpoint时间或者后台大批量写回数据的时间。
不仅仅时bgwriter,即使checkpoint进程和用户进程也从shared buffer刷写脏页到OS cache。可以通过checkpoint_flush_after影响checkpoint进程的fsync,通过backend_flush_after影响后台进程的fsync。
如果给OS cache很小值会怎么样?
正如上文所述,一旦页被标记为脏,他就会刷写到操作系统缓存。操作系统可以更加自由地根据传入的流量进行IO调度。如果OS cache太小,则无法重新对write进行排序从而优化IO。这对于写操作频繁的工作负载尤为重要,所以操作系统缓存大学也很重要。
如果给shared buffer很小值会怎么样?
数据库操作都在shared buffer,所以最好为shared buffer分配足够空间。
建议值多大?
PG推荐系统内存的25%给shared buffer,当然可以根据环境进行调整。
如果查看shared buffer中内容?
PG的buffer cache扩展可以帮助实时查看shared buffer中内容。从shared_buffers中采集信息保存到pg_buffercache表中:
create extension pg_buffercache;
安装好后,执行下面查询查看内容:
SELECT c.relname
, pg_size_pretty(count(*) * 8192) as buffered
, round(100.0 * count(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent
, round(100.0 * count(*) * 8192 / pg_relation_size(c.oid),1) AS percent_of_relation
FROM pg_class c
INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database())
WHERE pg_relation_size(c.oid) > 0
GROUP BY c.oid, c.relname
ORDER BY 3 DESC
LIMIT 10;
输出:
postgres=# SELECT c.relname postgres-# , pg_size_pretty(count(*) * 8192) as buffered postgres-# , round(100.0 * count(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent postgres-# , round(100.0 * count(*) * 8192 / pg_relation_size(c.oid),1) AS percent_of_relation postgres-# FROM pg_class c postgres-# INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode postgres-# INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database()) postgres-# WHERE pg_relation_size(c.oid) > 0 postgres-# GROUP BY c.oid, c.relname postgres-# ORDER BY 3 DESC postgres-# LIMIT 10; relname | buffered | buffers_percent | percent_of_relation ---------------------------+------------+-----------------+--------------------- pg_operator | 80 kB | 0.1 | 71.4 pg_depend_reference_index | 96 kB | 0.1 | 27.9 pg_am | 8192 bytes | 0.0 | 100.0 pg_amproc | 24 kB | 0.0 | 100.0 pg_cast | 8192 bytes | 0.0 | 50.0 pg_depend | 64 kB | 0.0 | 14.0 pg_index | 32 kB | 0.0 | 100.0 pg_description | 40 kB | 0.0 | 14.3 pg_language | 8192 bytes | 0.0 | 100.0 pg_amop | 40 kB | 0.0 | 83.3 (10 rows)
如何感知数据到达操作系统缓存层?
需要安装包pgfincore:
As root user: export PATH=/usr/local/pgsql/bin:$PATH //Set the path to point pg_config. tar -xvf pgfincore-v1.1.1.tar.gz cd pgfincore-1.1.1 make clean make make install Now connect to PG and run below command postgres=# CREATE EXTENSION pgfincore;
执行下面命令:
select c.relname,pg_size_pretty(count(*) * 8192) as pg_buffered,
round(100.0 * count(*) /
(select setting
from pg_settings
where name='shared_buffers')::integer,1)
as pgbuffer_percent,
round(100.0*count(*)*8192 / pg_table_size(c.oid),1) as percent_of_relation,
( select round( sum(pages_mem) * 4 /1024,0 )
from pgfincore(c.relname::text) )
as os_cache_MB ,
round(100 * (
select sum(pages_mem)*4096
from pgfincore(c.relname::text) )/ pg_table_size(c.oid),1)
as os_cache_percent_of_relation,
pg_size_pretty(pg_table_size(c.oid)) as rel_size
from pg_class c
inner join pg_buffercache b on b.relfilenode=c.relfilenode
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database()
and c.relnamespace=(select oid from pg_namespace where nspname='public'))
group by c.oid,c.relname
order by 3 desc limit 30;
输出:
relname |pg_buffered|pgbuffer_per|per_of_relation|os_cache_mb|os_cache_per_of_relation|rel_size
---------+-----------+------------+---------------+-----------+------------------------+--------
emp | 4091 MB | 99.9 | 49.3 | 7643 | 92.1 | 8301 MB
pg_buffered表示PG buffer cache中有多少数据,pgbuffer_percent表示pg_buffered/total_buffer_size*100。os_cache_mb表示OS cache中缓存多少。我们的表emp有8301MB数据,92%数据在OS cache,49.3%在shared buffers,大约50%的数据是冗余的。
为什么Aurora PG推荐75%的内存给shared buffer?
Aurora不使用文件系统缓存,因此可以提升shared_buffers大小以提升性能。最佳实践值为75%。Work_mem、maintenance_work_mem和其他本地内存不是shared buffer的一部分。如果应用请求大量客户端连接,或需要大量work_mem时,需要将这个值调小。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

