Spark性能调优-RDD算子调优篇
Spark调优之RDD算子调优不废话,直接进入正题!1. RDD复用在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示:RDD的重复计算对上图中的RDD计算架构进行
Spark调优之RDD算子调优
不废话,直接进入正题!
1. RDD复用
在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示:
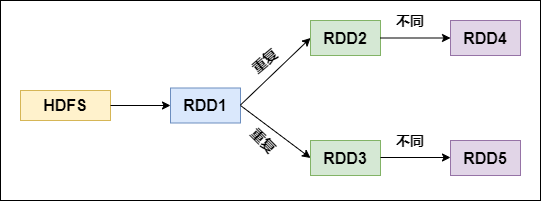
RDD的重复计算
对上图中的RDD计算架构进行修改,得到如下图所示的优化结果:
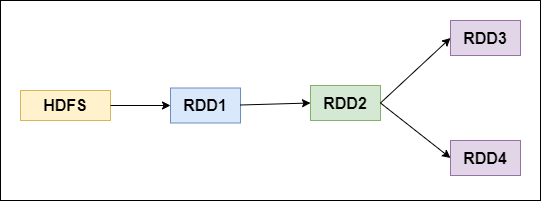
RDD架构优化
2. 尽早filter
获取到初始RDD后,应该考虑尽早地过滤掉不需要的数据,进而减少对内存的占用,从而提升Spark作业的运行效率。
3. 读取大量小文件-用wholeTextFiles
当我们将一个文本文件读取为 RDD 时,输入的每一行都会成为RDD的一个元素。
也可以将多个完整的文本文件一次性读取为一个pairRDD,其中键是文件名,值是文件内容。
val input:RDD[String] = sc.textFile("dir.log")
如果传递目录,则将目录下的所有文件读取作为RDD。文件路径支持通配符。
但是这样对于大量的小文件读取效率并不高,应该使用 wholeTextFiles
返回值为RDD[(String, String)],其中Key是文件的名称,Value是文件的内容。
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions): RDD[(String, String)])
wholeTextFiles读取小文件:
val filesRDD: RDD[(String, String)] =
sc.wholeTextFiles("D:\data\files", minPartitions = 3)
val linesRDD: RDD[String] = filesRDD.flatMap(_._2.split("\r\n"))
val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
wordsRDD.map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
4. mapPartition和foreachPartition
mapPartitions
map(_….) 表示每一个元素
mapPartitions(_….) 表示每个分区的数据组成的迭代器
普通的map算子对RDD中的每一个元素进行操作,而mapPartitions算子对RDD中每一个分区进行操作。
如果是普通的map算子,假设一个partition有1万条数据,那么map算子中的function要执行1万次,也就是对每个元素进行操作。
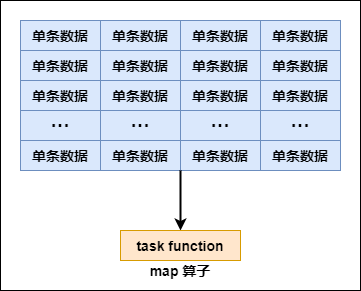
map 算子
如果是mapPartition算子,由于一个task处理一个RDD的partition,那么一个task只会执行一次function,function一次接收所有的partition数据,效率比较高。
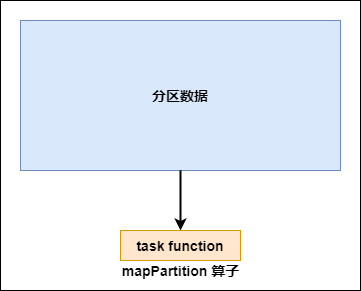
mapPartition 算子
比如,当要把RDD中的所有数据通过JDBC写入数据,如果使用map算子,那么需要对RDD中的每一个元素都创建一个数据库连接,这样对资源的消耗很大,如果使用mapPartitions算子,那么针对一个分区的数据,只需要建立一个数据库连接。
mapPartitions算子也存在一些缺点:对于普通的map操作,一次处理一条数据,如果在处理了2000条数据后内存不足,那么可以将已经处理完的2000条数据从内存中垃圾回收掉;但是如果使用mapPartitions算子,但数据量非常大时,function一次处理一个分区的数据,如果一旦内存不足,此时无法回收内存,就可能会OOM,即内存溢出。
因此,mapPartitions算子适用于数据量不是特别大的时候,此时使用mapPartitions算子对性能的提升效果还是不错的。(当数据量很大的时候,一旦使用mapPartitions算子,就会直接OOM)
在项目中,应该首先估算一下RDD的数据量、每个partition的数据量,以及分配给每个Executor的内存资源,如果资源允许,可以考虑使用mapPartitions算子代替map。
foreachPartition
rrd.foreache(_….) 表示每一个元素
rrd.forPartitions(_….) 表示每个分区的数据组成的迭代器
在生产环境中,通常使用foreachPartition算子来完成数据库的写入,通过foreachPartition算子的特性,可以优化写数据库的性能。
如果使用foreach算子完成数据库的操作,由于foreach算子是遍历RDD的每条数据,因此,每条数据都会建立一个数据库连接,这是对资源的极大浪费,因此,对于写数据库操作,我们应当使用foreachPartition算子。
与mapPartitions算子非常相似,foreachPartition是将RDD的每个分区作为遍历对象,一次处理一个分区的数据,也就是说,如果涉及数据库的相关操作,一个分区的数据只需要创建一次数据库连接,如下图所示:

foreachPartition 算子
使用了foreachPartition 算子后,可以获得以下的性能提升:
对于我们写的function函数,一次处理一整个分区的数据;
对于一个分区内的数据,创建唯一的数据库连接;
只需要向数据库发送一次SQL语句和多组参数;
在生产环境中,全部都会使用foreachPartition算子完成数据库操作。foreachPartition算子存在一个问题,与mapPartitions算子类似,如果一个分区的数据量特别大,可能会造成OOM,即内存溢出。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

