一文搞懂 Flink 端到端精准一次处理语义
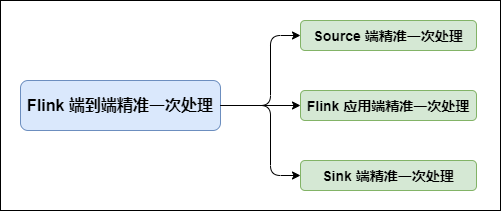
Flink在 Flink 中需要端到端精准一次处理的位置有三个:Flink 端到端精准一次处理Source 端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消费。Flink 内部端:这个
Flink
在 Flink 中需要端到端精准一次处理的位置有三个:
Flink 端到端精准一次处理
Source 端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消费。
Flink 内部端:这个我们已经了解,利用 Checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。不了解的小伙伴可以看下我之前的文章:
Flink可靠性的基石-checkpoint机制详细解析
Sink 端:将处理完的数据发送到下一阶段时,需要保证数据能够准确无误发送到下一阶段。
在 Flink 1.4 版本之前,精准一次处理只限于 Flink 应用内,也就是所有的 Operator 完全由 Flink 状态保存并管理的才能实现精确一次处理。但 Flink 处理完数据后大多需要将结果发送到外部系统,比如 Sink 到 Kafka 中,这个过程中 Flink 并不保证精准一次处理。
在 Flink 1.4 版本正式引入了一个里程碑式的功能:两阶段提交 Sink,即 TwoPhaseCommitSinkFunction 函数。该 SinkFunction 提取并封装了两阶段提交协议中的公共逻辑,自此 Flink 搭配特定 Source 和 Sink(如 Kafka 0.11 版)实现精确一次处理语义(英文简称:EOS,即 Exactly-Once Semantics)。
Flink端到端精准一次处理语义(EOS)
注:以下内容适用于 Flink 1.4 及之后版本
对于 Source 端:Source 端的精准一次处理比较简单,毕竟数据是落到 Flink 中,所以 Flink 只需要保存消费数据的偏移量即可, 如消费 Kafka 中的数据,Flink 将 Kafka Consumer 作为 Source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性。
对于 Sink 端:Sink 端是最复杂的,因为数据是落地到其他系统上的,数据一旦离开 Flink 之后,Flink 就监控不到这些数据了,所以精准一次处理语义必须也要应用于 Flink 写入数据的外部系统,故这些外部系统必须提供一种手段允许提交或回滚这些写入操作,同时还要保证与 Flink Checkpoint 能够协调使用(Kafka 0.11 版本已经实现精确一次处理语义)。
我们以 Flink 与 Kafka 组合为例,Flink 从 Kafka 中读数据,处理完的数据在写入 Kafka 中。
为什么以Kafka为例,第一个原因是目前大多数的 Flink 系统读写数据都是与 Kafka 系统进行的。第二个原因,也是最重要的原因 Kafka 0.11 版本正式发布了对于事务的支持,这是与Kafka交互的Flink应用要实现端到端精准一次语义的必要条件。
当然,Flink 支持这种精准一次处理语义并不只是限于与 Kafka 的结合,可以使用任何 Source/Sink,只要它们提供了必要的协调机制。
Flink 与 Kafka 组合
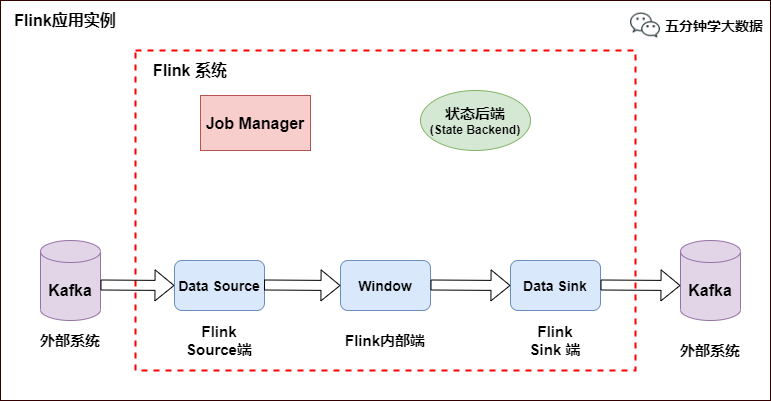
Flink 应用示例
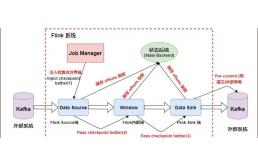
如上图所示,Flink 中包含以下组件:
一个 Source,从 Kafka 中读取数据(即 KafkaConsumer)
一个时间窗口化的聚会操作(Window)
一个 Sink,将结果写入到 Kafka(即 KafkaProducer)
若要 Sink 支持精准一次处理语义(EOS),它必须以事务的方式写数据到 Kafka,这样当提交事务时两次 Checkpoint 间的所有写入操作当作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
当然了,在一个分布式且含有多个并发执行 Sink 的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一个一致性的结果。Flink 使用两阶段提交协议以及预提交(Pre-commit)阶段来解决这个问题。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

