一文了解深度学习模型VAE的时序性解耦
现代深度学习架构一直被描述为一个黑匣子:被输入数据,并期望从中得到一些结果。然而,由于此类架构存在许多的复杂性,过程中发生的事情,通常难以解释和分析。这已发展成为整个社会未能广泛接受深度学习的主要原因之一,尤其是对于关键任务应用程序


现代深度学习架构一直被描述为一个黑匣子:被输入数据,并期望从中得到一些结果。然而,由于此类架构存在许多的复杂性,过程中发生的事情,通常难以解释和分析。这已发展成为整个社会未能广泛接受深度学习的主要原因之一,尤其是对于关键任务应用程序。
因此,“黑匣子”的解体已成为机器学习研究人员的一个重大开放问题,并且是该领域当前感兴趣的问题之一,这一研究领域通常被称为机器学习架构的“可解释性”。在本文中,我们将讨论可解释性研究中的一个重要主题,即解耦问题。
Disentangled
Sequential VAE
光的解耦(Ddisentangled)
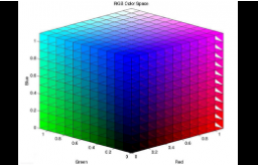
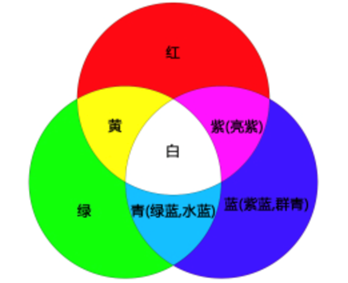
我们举个常见的例子:在日常生活中,太阳光看起来是白色的,但是如果我们让阳光通过三棱镜,就会发现阳光分别折射出多种色彩。这说明白光其实是多种颜色混合的体现,而我们可以通过三棱镜把它分解成基本七种颜色,其中包括红、绿、蓝三原色。

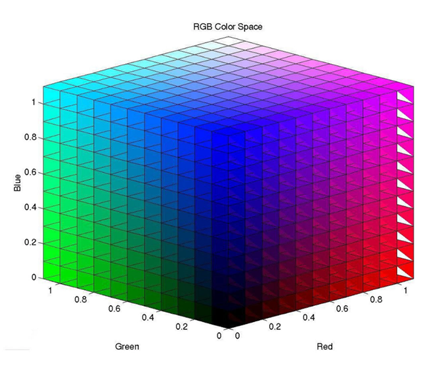
我们继续聊聊白光:在广泛意义上说光是由RGB三种颜色组成的。这也就定义了光的解耦过程:光可以分离成R、G、B三种颜色,同时我们也可以用这三种颜色,进行不同程度的叠加,产生丰富而广泛的颜色。
计算机定义颜色时R、G、 B三种成分的取值范围是0-255,0表示没有刺激量,255表示刺激量达最大值。R、G、B均为255时就合成了白光,R、G、B均为0时就形成了黑色。在这个区间范围内,我们可以通过任意的数值组合构造出无数种不同的颜色,让我们的生活充满色彩。
白光和解耦又有什么关系呢?那关系就大了!我们下面简单聊一下一种深度学习模型——变分自编码器模型(VAE:variational autoencoder),然后用它来解释解耦。

什么是VAE?
什么是VAE呢?那要先从AE开始说起了。
AE(Autoencoder)
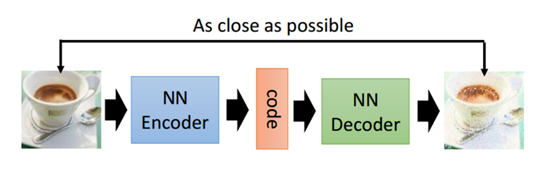
上图由两个部分组成,第一个部分是编码器(Encoder),第二部分是解码器(Decoder),图片经过编码器得到一个潜在的编码(code),编码再通过解码器还原输入的图片,因此得到的编码就是图片在一个潜在空间的表示。而编码器和解码器就是由神经网络组成的。图中例子就是希望能够生成一张一样的图片。
VAE (Variational Autoencoder)
变分编码器是自动编码器的升级版本,其结构跟自动编码器相似,也由编码器和解码器构成。在AE中,输入一个图片得到一个的编码(code),但这个编码是一个固定的编码,使得模型没有很好的泛化功能。所以VAE引入了一种新的方式有效解决了上述的问题,就是将编码问题变成一个分布问题,具体操作是在AE的基础上增加一个限制,迫使编码器得到的编码(code)能够粗略地遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
这样我们生成一张新图片就很简单了,我们只需要给它一个标准正态分布的随机隐含向量,这样通过解码器就能够生成我们想要的图片,而不需要给它一张原始图片先进行编码。
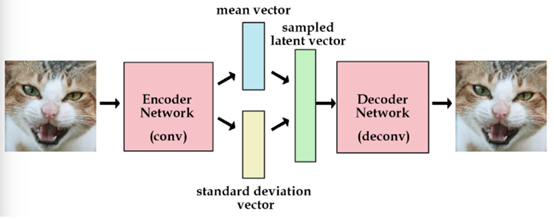
VAE的演变增加了模型的泛化性,以上图VAE的过程为例,当输入的图片是猫时,通过猫的特征来生成新的图片,VAE的好处就在于当输入的图片不是完整的图片时(训练集外),它依旧可以还原成原来的样子。
在深度学习中,不管是什么样的模型,数据都很重要,而VAE的好处就在于 :
它可以通过编码和解码的过程,通过抽样,生成新的数据。这样对于机器学习就有了更多的数据支撑从而得到更好的模型效果。
VAE在中间层会得到一个编码(code),也就是一个语义层,我们可以通过对于这个语义的理解,从而达到图片的分类、变换的效果。
如果我们类比光的解耦(将光分离成R、G、B三种颜色),VAE(Variational Autoencoder)就可以理解成是深度学习框架的三棱镜。
这是为什么呢?我们先给一个浅显的技术介绍,然后再回来聊颜色分离。
VAE是一种深度学习框架,更具体来说,它是一种生成模型。生成模型的操作很简单:它可以读取数据(多为图片),抽取数据的特征,然后自动生成有这些特征的新数据。我们这里关心的是提取特征这个环节。大多生成模型的特征提取模式,便是经过所谓的“潜在变量”(latent variables)来编码提取到的特征。
这里的一个明显的问题便是:我们怎么判断正式数据里的某一个特征对应的是哪个语义变量?我们可以回到类比成颜色分离和生成的过程,将一种颜色先编码(encoder)成R,G,B,再通过解码(decoder)形成一种颜色。

Disentangled Sequential VAE
随着对VAE的研究,越来越多的研究重点就放在了如何在VAE的基础上做到disentangled的过程。以下简单介绍一下深兰科学院对于该项目的研究内容:对于时序的数据解耦出其数据的动态信息和静态信息,并理解静态信息和动态信息的语义,后续团队的目标也是基于当前的项目,进行这个主流方向的基础研究。

本项目采用的数据是Sprites,这是个具有时序性的数据。如上图所示小精灵有着不同的颜色和动作,团队的任务就是通过这些小精灵的图片,解耦出小精灵的动态信息(小精灵的动作)和静态信息(小精灵的颜色)。通过深度学习来获得小精灵动静态信息的语义,并理解这语义从而生成新的小精灵。
如下图所示,通过深度学习得到小精灵的动态信息和静态信息,并改变他们的值的生成效果(上排是原始数据,下排是生成数据)。
1. 改变静态信息(颜色)

2.改变动态信息

对于VAE时序性解耦的工作可以更容易地说明神经网络的可解释性,这样的任务不仅可以对神经网络的基础研究作出贡献,还可以应用到很多人工智能的项目中,例如对图像视频的处理;动静的解耦可以实现换脸等效果;在自然语言处理中,可以改变声音的种类等。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

