如何对图像进行去噪来绕过验证码的方法
?通过使用广度优先搜索算法对图像进行去噪来绕过验证码的新方法验证码被广泛用作确保对系统执行的操作是由人类而不是机器人完成的一种方式。然而,这种方法并不是万无一失的,尤其是在OCR和计算机视觉技术如此发达的今天

?通过使用广度优先搜索算法对图像进行去噪来绕过验证码的新方法
验证码被广泛用作确保对系统执行的操作是由人类而不是机器人完成的一种方式。然而,这种方法并不是万无一失的,尤其是在OCR和计算机视觉技术如此发达的今天。让我们从用户的角度来看,每次想要访问某个网站时都必须解决验证码是一件非常痛苦的事情,尤其是当你每天都需要这样做时!在本文中,将探索我自己的绕过特定类型验证码的方法。该方法利用广度优先搜索 (BFS) 和OpenCV在将图像传递给OCR引擎 (Tesseract) 之前对图像进行去噪。由于有太多不同类型的文本验证码具有不同形式的失真/增强,因此我的方法仅适用于我试图绕过的特定验证码源。但也许你会在我的文章中找到一些对你自己解决验证码问题有用的细节!验证码

正如我所提到的,有许多不同类型的文本验证码。我试图绕过的验证码的变化对单词应用倾斜失真,同时用雪状图案覆盖图像。从根本上(并且幸运的是),这种类型的验证码并不太难解决。这是因为验证码文本本身没有任何噪音,可以被 OCR 引擎识别。如果文本被进一步扭曲,像 Tesseract 这样的开源 OCR 库将无法读取文本。因此,我们现在需要做的是一系列图像过滤以去除所有噪声并仅保留验证码文本。方法我将要讨论的方法具有概率特性,这意味着它不能保证在每次试验中都有效。但是,我们可以利用验证码和系统的一些先验知识来确保我们最大化验证码的成功概率。但首先,让我们谈谈验证码图像的去噪方法。该过程可以概括为以下步骤:转换为灰度中值滤波器(内核大小 3)图像阈值处理岛屿去除中值滤波器(内核大小 3)

图像首先转换为灰度,以将通道数减少到仅 1。然后注意到在现有的随机雪花噪声之上放置了一致的明暗像素点图案。中值滤波器可以有效去除这种密集和重复的噪声模式。尽管有轻微的模糊,但经过中值滤波器后的图像更加清晰。我们要做的下一步是对图像进行阈值处理,将所有像素强度推到 1 或 0。阈值通过反复试验进行微调,以确保保留文本的所有像素。
在此之后,我们留下了验证码文本,周围是点状噪声,这是阈值化的残留物。这些点分散在图像周围,但更多地集中在文本周围。这就是使用 BFS 的地方,因为我们将使用这种我称之为“岛屿去除”的方法来去除所有的点状噪声。该方法访问了图像上的所有黑色像素。在每个黑色像素上,它使用 BFS 找到所有也是黑色的邻居。
本质上,该函数识别图像上的所有黑色像素簇,如果簇大小小于预定阈值,则将其移除(即转换为白色像素)。这种“去除岛屿”方法的灵感来自于相当流行的编程问题Number of Islands,你应该使用 BFS 或 DFS 来计算二维数组(即岛屿)中 1 的簇数。最后一步是应用另一个内核大小为 3 的中值滤波器来平滑图像的边缘。然后,它准备好传递到 Tesseract OCR 进行文本提取。从上面的步骤图可以看出,去噪过程产生了相当积极的输出。最重要的是,Tesseract 能够识别输出正确验证码文本的单词就足够了。下面是去噪的代码片段。
def bfs(visited, queue, array, node):
# I make BFS itterative instead of recursive
def getNeighboor(array, node):
neighboors = []
if node[0]+1
neighboors.append((node[0]+1,node[1]))
if node[0]-1>0:
if array[node[0]-1,node[1]] == 0:
neighboors.append((node[0]-1,node[1]))
if node[1]+1
neighboors.append((node[0],node[1]+1))
if node[1]-1>0:
if array[node[0],node[1]-1] == 0:
neighboors.append((node[0],node[1]-1))
return neighboors
queue.append(node)
visited.add(node)
while queue:
current_node = queue.pop(0)
for neighboor in getNeighboor(array, current_node):
if neighboor not in visited:
# print(neighboor)
visited.add(neighboor)
queue.append(neighboor)
def removeIsland(img_arr, threshold):
# !important: the black pixel is 0 and white pixel is 1
while 0 in img_arr:
x,y = np.where(img_arr == 0)
point = (x[0],y[0])
visited = set()
queue = []
bfs(visited, queue, img_arr, point)
if len(visited) for i in visited:
img_arr[i[0],i[1]] = 1
else:
# if the cluster is larger than threshold (i.e is the text),
# we convert it to a temporary value of 2 to mark that we
# have visited it.
for i in visited:
img_arr[i[0],i[1]] = 2
img_arr = np.where(img_arr==2, 0, img_arr)
return img_arr
img = cv2.imread("temp.png")
# Convert to grayscale
c_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# Median filter
kernel = np.ones((3,3),np.uint8)
out = cv2.medianBlur(c_gray,3)
# Image thresholding
a = np.where(out>195, 1, out)
out = np.where(a!=1, 0, a)
# Islands removing with threshold = 30
out = removeIsland(out, 30)
# Median filter
out = cv2.medianBlur(out,3)
# Convert to Image type and pass it to tesseract
im = Image.fromarray(out*255)
print(pytesseract.image_to_string(im))
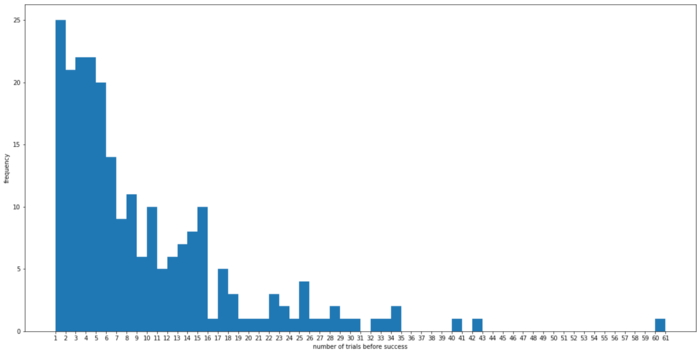
以上是此方法在输出正确验证码之前进行的试验次数分布的直方图。数据是我自己记录的,因为我个人每天都使用这种方法超过 3 个月。可以看出,大多数试验次数低于 20,精确平均值为 9.02。结论本文中介绍的方法有一定的优缺点。优点是该方法不需要任何训练,因此不需要标记数据集。计算速度快,实现简单。然而,缺点是该方法是概率性的,因此对于在多次错误尝试验证码后阻止用户的系统,使用这种方法可能会锁定你的帐户。此外,该方法针对非常特定类型的验证码,需要微调,甚至可能不适用于其他类型的验证码。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

