华为ai系列研究:昇腾的Atlas 800训练服务器
上一篇了解到华为昇腾的Atlas 500智能小站,今天学习一下华为昇腾的Atlas 800训练服务器。大家发现没?越往后研究越是高级的产品。Atlas 800 训练服务器(型号:9000)是基于华为鲲鹏920+昇腾910处理器的AI训练服务器,具有最强算力密度、超高能效与高速网络带宽等特点
上一篇了解到华为昇腾的Atlas 500智能小站,今天学习一下华为昇腾的Atlas 800训练服务器。大家发现没?越往后研究越是高级的产品。
Atlas 800 训练服务器(型号:9000)是基于华为鲲鹏920+昇腾910处理器的AI训练服务器,具有最强算力密度、超高能效与高速网络带宽等特点。该服务器广泛应用于深度学习模型开发和训练,适用于智慧城市、智慧医疗、天文探索、石油勘探等需要大算力的行业领域。
这里面非常关键的一个信息是,AI处理器从昇腾310换成了昇腾910,这也是算力的增强。我们就先说一下310和910的区别。
昇腾310:昇腾310是一款高效、灵活、可编程的AI处理器。基于典型配置,八位整数精度(INT8)下的性能达到22TOPS,16位浮点数(FP16)下的性能达到11 TFLOPS,而其功耗仅为8W。昇腾310芯片采用华为自研的达芬奇架构,集成了丰富的计算单元,在各个领域得到广泛应用。随着全AI业务流程的加速,昇腾310芯片能够使智能系统的性能大幅提升,部署成本大幅降低。
昇腾310在功耗和计算能力等方面突破了传统设计的约束。随着能效比的大幅提升,昇腾310将人工智能从数据中心延伸到边缘设备,为平安城市、自动驾驶、云服务和IT智能、智能制造、机器人等应用场景提供了全新的解决方案,使能智慧未来。

图片来自华为官网
昇腾910 AI处理器:昇腾910是一款具有超高算力的AI处理器,其最大功耗为310W,华为自研的达芬奇架构大大提升了其能效比。八位整数精度(INT8)下的性能达到640TOPS,16位浮点数(FP16)下的性能达到320 TFLOPS。
作为一款高集成度的片上系统(SoC),除了基于达芬奇架构的AI核外,昇腾910还集成了多个CPU、DVPP和任务调度器(Task Scheduler),因而具有自我管理能力,可以充分发挥其高算力的优势。
昇腾910集成了HCCS、PCIe 4.0和RoCE v2接口,为构建横向扩展(Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法。HCCS是华为自研的高速互联接口,片内RoCE可用于节点间直接互联。最新的PCIe 4.0的吞吐量比上一代提升一倍。

图片来自华为官网
通过两款芯片的对比,它们的主要区别是算力大小以及算力管理能力,大算力者可以做训练服务器。研究完主芯片之后,我们再回到Atlas 800 训练服务器,它用又分风冷和液冷两种:

图片来自华为官网
它的外形如下图:



图片来自华为官网
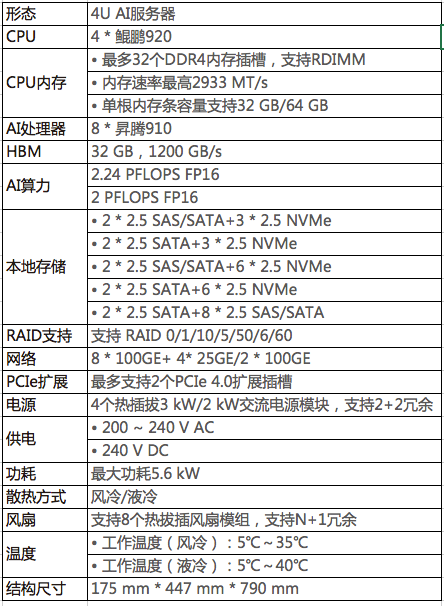
产品规格表
更多研究,请参考链接:华为800。接下来的每周研究,将会对使用场景进行深入研究,包括应用的生态,华为是大厂中做生态做得最好的公司了,敬请期待。
免责声明:
本公众号为个人研究专题学习分享,非商业公众号无任何商业目的,如果文章内容有侵权或者非法信息,请立即与本号联系删除谢谢
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

