计算机视觉简史:被称为“人脸识别”的计算机视觉经历了什么?
导语:发展60多年来,机器视觉作为AI技术的急先锋,经历了几轮起落,终于迎来技术上的爆发。但随着技术进入深水区,寻找合适的商业模式真正成为了机器视觉这门技术的最大难点。1999年上映的《黑客帝国》虽然不是人类关于人工智能的第一次影视化探索,却可以说是最有影响力的一次


导语:发展60多年来,机器视觉作为AI技术的急先锋,经历了几轮起落,终于迎来技术上的爆发。但随着技术进入深水区,寻找合适的商业模式真正成为了机器视觉这门技术的最大难点。
1999年上映的《黑客帝国》虽然不是人类关于人工智能的第一次影视化探索,却可以说是最有影响力的一次。
电影讲述的是基努李维斯饰演的网络黑客尼奥发现自己生活的世界被某种外部力量控制并通过调查发现自己活在人工智能的虚拟世界里,之后同一个反抗者组织奋起而抗争的故事。
在《黑客帝国》设定的真实世界中,他们的肉体早已被当作被养殖的作物,为母体供应能量,只有意识在母体Matrix中活动,误以为自己还在过正常生活。
2011年,英剧《黑镜》第一季上线,之后连续推出四季,这是一部探讨科技对人类生活改变的电影,其中也包含诸多人工智能对于人类生活的改变与颠覆故事。
2016年,HBO发行的科幻类美剧《西部世界》上线,讲述了由一座巨型高科技以西部世界为主题的成人乐园,提供机器人接待员给游客,让他们实现杀戮与性欲的满足;但后来随着接待员有了自主意识和思维,他们开始怀疑这个世界的本质,进而觉醒并反抗人类的故事。
这些电影,讲述的多是人工智能发展的高级阶段,更是最近大家讨论的“元宇宙”的形象化表现。
抛开道德上的善恶对错不谈,回到人工智能技术本身,在达成这些了不起的成就之前,在计算机能够“思考”之前,最早需要开始学习的技能是“感知”,其中最重要部分之一就是学会“看”,这也几乎是公认的人工智能第一步。
就在《黑镜》上映的同一年——2011年,如今被称为“AI四小龙”之一的旷视科技在三个天才少年的带领下成立了,随后四年间,商汤科技、依图科技和云从科技业全部拔地而起,所选择的赛道都是“人脸识别”,其实本质就是让计算机看图。
最近,在经过多年的奋战之后,基于抢占赛道或者抢占资金的想法,他们如今终于走进了资本市场的视野。除了依图科技已经撤回上市申请之外,其他三家都离上市仅一步之遥了。

这些年,被称为“人脸识别”的计算机视觉都经历了什么?
起步阶段:人类对教会机器“看”的执念
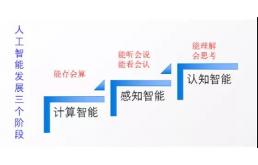
在我们讲述计算机视觉之前,先要了解目前人工智能所处的阶段,那就是“感知智能”,无论是AI四小龙的“人脸识别”还是科大讯飞的“语音识别”,都落在这一阶段。
在此之前,我们还只是用计算机来计算数据、运行代码,但这只是初级的“计算智能”阶段。现在计算机已经学会了“感知”,不过距离计算机“能理解、会思考”的认知智能阶段,也就是最开始讲的那些电影里能达到的最终水平,还差得很远。

让计算机学会“感知”,最重要的一步就是”看“了。
眼睛,是人类用来观察这个世界的最重要器官,也是唯一的视觉器官。在佛家所谓的六根——眼耳鼻舌身意中,眼睛也排在首位。
用眼睛看,是人类与生俱来的能力,刚出生的婴儿只需要几天的时间就能学会模仿父母的表情,人们能从复杂结构的图片中找到关注重点、在昏暗的环境下认出熟人。
人类对眼睛的功能是有执念的。
为了将自己看到的东西保存下来,人类发明了照相机。最早的真正照相机来自1839年1月,当时中国还在清朝的道光年间。摄影师达盖尔在巴黎沙龙上展示了银板照相法,将涂有碘化银的铜片暴露在光线下,然后通过汞蒸汽和食盐溶液来显影,震惊了法国科学院,并于当年推广开来。
银板照相法所使用的就是这种用木箱子装的相机。
自此人类终于学会长时间保存眼睛看到的图像了,之后又有了胶卷和即显摄影。
但似乎对于人类来说,光是记录并不够,我们还想让机器自己去看,并且告诉我它们看到了什么。
为了让机器学会如何去“看”,就有了计算机视觉,当然,它更为大家所熟知的名称是“人脸识别”。
最初的探讨发生在1956年左右。在当年的达特茅斯会议上,约翰麦卡锡、马文闵斯基、克劳德香农、艾伦纽厄尔和赫伯特西蒙等科学家聚在一起,讨论着一个完全不食人间烟火的主题:用机器来模仿人类学习以及其他方面的智能。
会议一共开了两个月的时间,虽然大家没有达成普遍的共识,但是却为会议讨论的内容起了一个名字:人工智能。因此,1956年也就成为了人工智能元年。
1957年春天,美国国家标准局的科学家拉塞尔·基尔希为他的儿子瓦尔登拍了一张照,并将其扫描到了东部标准自动计算机(SEAC)中。为了使图片可以放进SEAC有限的存储空间中,他将图片分割成176176的网格——共30976位二进制,并进行了多次扫描。这张边长5厘米的正方形图片就是历史上第一张数字图像,从某种意义上来讲它甚至是CT扫描、卫星图像和数码摄影的鼻祖。
1959年,神经生理学家大卫·休伯尔和托斯坦·维厄瑟尔通过猫的视觉实验,首次发现了视觉初级皮层神经元对于移动边缘刺激敏感,发现了视功能柱结构,为视觉神经研究奠定了基础——促成了计算机视觉技术40年后的突破性发展,奠定了深度学习的核心准则。
到了60年代,劳伦斯罗伯茨在《三维固体的机器感知》描述了从二维图片中推导三维信息的过程,成为计算机视觉的前导之一,开创了理解三维场景为目的的计算机视觉研究。这个研究给世界带来了很大启发,并且对边缘、线条、明暗等各种特征建立了各种数据结构和推理规则。

1969年秋天,贝尔实验室的两位科学家韦拉德博伊尔和乔治史密斯正忙于电荷耦合器件(CCD)的研发。它是一种将光子转化为电脉冲的器件,很快成为了高质量数字图像采集任务的新宠,逐渐应用于工业相机传感器,标志着计算机视觉走上应用舞台,投入到工业机器视觉中。
70年代是人工智能发展的低潮期。
80年代后计算机视觉成为一门独立学科,并开始从实验室走向应用。80年日本科学家福岛邦彦建立了第一个神经网络,82年大卫马尔发表了一篇非常有影响力的论文,介绍了处理视觉数据的算法框架,同年《Vision》这本书问世,标志着计算机视觉正式成为了一门独立学科。

大发展:卷积神经网络与深度学习
90年代计算机视觉的发展整体比较落寞,因为训练神经网络是一项资源非常密集、并且进展极为缓慢的工作。
一直到2005年之后,才又迎来快速发展阶段。

2006年左右,杰弗里·希尔顿(Geoffrey Hilton)和他的学生首次提出了深度置信网络(DBN)的概念。他给多层神经网络相关的学习方法赋予了一个新名词–“深度学习”(Deep Learning)。
人脑视觉系统的信息处理是分层的。简单来说,就是要先从功能相对低级的区域分辨出朝向、空间位置和运动方向,然后到下一个区域再去处理形状和颜色等信息。
比如当你看《黑客帝国》时,你是先看到一个人朝着镜头走过来,然后才分出这个人的脸型和各种面部特征、穿着的衣服颜色,根据这些信息和你大脑中原有的海量信息做匹配,你就能够判断出来这个正在运动的人是基努里维斯。
所以在大脑中,对一个形象的判别是分层次处理的,并不是一股脑把所有信息交给某个部分,然后它突然得出结论这个人是里维斯。
而深度学习就是借鉴人脑的信息处理过程,对信息进行分层处理,进行特征提取和分类。深度学习的实质,是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类的准确性。
计算机需要学习足够的数据,才能训练出一个能够用于识别的模型。

数据量很重要,对你的大脑也是一样。一个不是特别恰当的例子是,如果你没见过里维斯,你就算看到了这个五官、清晰地分别出头发和瞳孔颜色,也没有办法判断他到底是谁。
这也是为什么,在网络数据受限的情况下,深度学习的资源就不够。
此外,神经网络的分层也是在不断进步的。
2005 年以前提出的人工神经网络只是一种浅层模型,只含有一层隐层节点,但这比人脑简化太多了,效果也就差得多。
而用深度置信网络解决来这个问题,可以构建更多层的模型,更接近人的视觉神经系统的结构。
不过随着时间的推移,深度置信模型(DBP)也有一些问题,包括计算量太大、样本量太大等等。卷积神经网络(CNN)又可以解决这个问题,它将每一层信息仅通过一个“卷积核”相连。
你可以理解两个平面之间,前者是需要每个点直接相连,现在只需要中间的一个点直接相连。
等于DBN需要计算机一次性看完整张图,全局对比;但CNN可以一步一步一块一块地对比小特征,和分布式系统的感觉有点像。
这样处理样本的速度就显著加快了。
据广证恒生在2019年的研究报告,美国国家标准与技术研究院(NIST)公布了全球权威人脸识别比赛(FRVT)最新报告,从前十名企业在千分之一的误报率下的识 别准确率来看,其平均能达到 99.69%,在千万分之一误报下的识别准确率超过 99%,意味着机器几乎可 以做到在 1000 万人的规模下准确识别每一个人。
而人脑记忆100个人的身份都有可能出错。

这几年,无论是安防中的人脸识别,还是高铁闸机上的人脸识别,抑或是证券在线开户、交易等,大家都开始自由地使用人脸作为个人识别的特征。
当技术不再困难的时候,在讨论伦理之前,创业公司们却首先迎来了商业化的难题。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

