NLP预训练中的mask方式
目录一、为什么要mask二、这些年paper中出现过的mask方式2.1 padding Padding-mask2.2 sequence mask:transformer decoder部分2.3
目录
一、为什么要mask
二、这些年paper中出现过的mask方式
2.1 padding Padding-mask
2.2 sequence mask:transformer decoder部分
2.3 BERT: maskd LM
2.4 RoBERTa: dynamic maskd LM
2.5 ERNIE: Knowledge masking strategies
2.6 BERT-wwm
参考资料
一、为什么要mask
1.1 padding:
数据输入模型的时候长短不一,为了保持输入一致,通过加padding将input转成固定tensor
如:
一句话:[1, 2, 3, 4, 5]
input size: 1* 8
加padding:[1, 2, 3, 4, 5, 0, 0, 0]
1.2 padding 引入带来的问题:
padding填充数量不一致,导致均值计算偏离
如:
原始均值:(1 + 2 + 3 + 4 + 5) / 5 = 3
padding后的均值: (1 + 2 + 3 + 4 + 5) / 8 = 1.875
1.3 引入mask,解决padding的缺陷:
假设 m = [1, 1 , 1, 1, 1, 0, 0, 0]
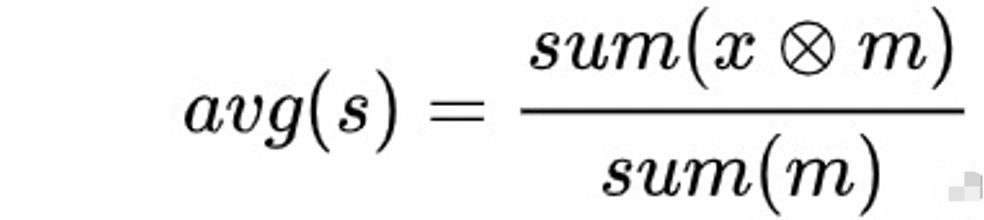
?:逐个相乘
mask后的avg = 3 (和原先结果一致)
1.4 除了上述的padding的场景,为了让模型学习到某个词或者关注到某个区域,也可以使用mask对信息做屏蔽。
二、这些年paper中出现过的mask方式
2.1 padding Padding-mask
原理同上
例:transformer mask encoder self-attention mask
2.2 sequence mask:transformer decoder部分
训练的时候,在Masked Multi-head attention层中,为了防止未来的信息被现在时刻看到,需要把将来的信息mask掉。

mask为下三角矩阵

使用mask矩阵,把当前之后的全部遮住。
可以防止看到t时刻之后的信息。
t-1时刻、t时刻、t+1时刻在masked Multi-head attention layer是并行计算的。
延伸问题:transformer decoder在预测时也用到了mask
是为了保持预测时和训练时,信息量一致。保证输出结果的一致。
2.3 BERT: maskd LM
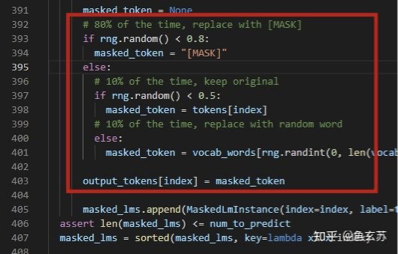
The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time. Then, Ti will be used to predict the original token with cross entropy loss.
——BERT 原文:训练数据中,被mask选中的概率是15%,选中的词,被[MASK]替换的概率是80%,不变的概率是10%,随机替换的概率是10%。
解释:训练分布和实际语言分布有差异,三种替换方式是为了告诉模型,输入的词有可能是错误的,不要太相信。
对应的代码:bert/create_pretraining_data.py
2.4 RoBERTa: dynamic maskd LM
The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training.
RoBERTa的原文对比了BERT的静态mask。并说明了RoBERTa为了避免静态mask导致每个epoch训练输入的数据mask是一样的,所以先把数据复制了10份,然后在40轮训练中,每个序列都以10种不同的方式被mask。
2.5 ERNIE: Knowledge masking strategies
ERNIE is designed to learn language representation enhanced by knowledge masking strategies, which includes entity-level masking and phrase-level masking.
给BERT加了知识图谱,加强了局部学习。BERT原先的方式,只是从mask出现的概率做填空。用knowledge level的填空方式,把knowledge挖空,保证了模型学到关键知识。

基本级别掩码(Basic-Level Masking):
这里采用了和BERT完全相同的掩码机制,在进行中文语料时,这里使用的是字符级别的掩码。在这个阶段并没有加入更高级别的语义知识。
短语级别掩码(Phrase-Level Masking):
在这个阶段,首先使用语法分析工具得到一个句子中的短语,例如图中的“a serious of”,然后随机掩码掉一部分,并使用剩下的对这些短语进行预测。在这个阶段,词嵌入中加入了短语信息。
实体级别掩码(Entity-Level Masking):
在这个阶段,将句子中的某些实体掩码掉,这样模型就有了学习更高级别的语义信息的能力。
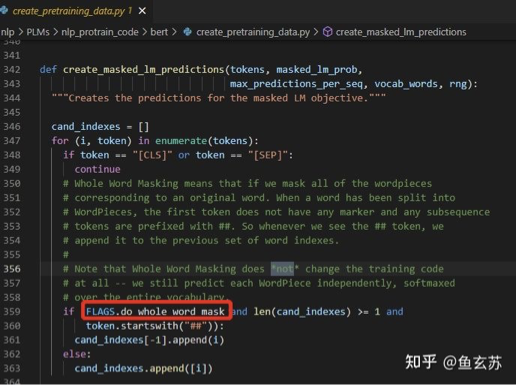
2.6 BERT-wwm
继2019年4月百度发布ERNIE1.0之后,同年7月讯飞+哈工大发布了BERT-WWM。
The whole word masking mainly mitigates the drawbacks in original BERT that, if the masked WordPiece token (Wu et al., 2016) belongs to a whole word, then all the WordPiece tokens (which forms a complete word) will be masked altogether.
连续mask所有能组成词的词
wwm的Roberta没有动态mask,因为不需要,所有词已经mask了。
wwm的代码解释参考[4]
例句:there is an apple tree nearby.
tok_list = ["there", "is", "an", "ap", "##p", "##le", "tr", "##ee", "nearby", "."]
bert没有wwm结果是:
there [MASK] an ap [MASK] ##le tr [RANDOM] nearby .
[MASK] [MASK] an ap ##p [MASK] tr ##ee nearby .
there is [MASK] ap [MASK] ##le tr ##ee nearby [MASK] .
bert-wwm结果是:
there is an [MASK] [MASK] [RANDOM] tr ##ee nearby .
there is [MASK] ap ##p ##le [MASK] [MASK] nearby .
there is! [MASK] ap ##p ##le tr ##ee nearby [MASK] .
可以看出,apple这个词,在没有wwm时,会被mask不同部分;wwm时,则同时被mask,或者不被mask。
wwm无需改动bert代码:

相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

