facebook:用音乐生成3D动画
说到以VR演奏乐器,目前应用市场中已有的VR乐器应用并不罕见。VR乐器的诞生帮助很多对音乐向往却囿于乐器价格和摆放空间的爱好者过上了把手瘾、耳瘾。


说到以VR演奏乐器,目前应用市场中已有的VR乐器应用并不罕见。VR乐器的诞生帮助很多对音乐向往却囿于乐器价格和摆放空间的爱好者过上了把手瘾、耳瘾。

就在上一周,小编提到的关于facebook对手部的精准追踪,更是助了VR演奏一臂之力,十八般乐器,样样不在话下。

这些应用都是以人为演奏者,根据人的动作发出对应的音调声响。可若是把这个过程反过来又会是怎么样的一种情形呢?
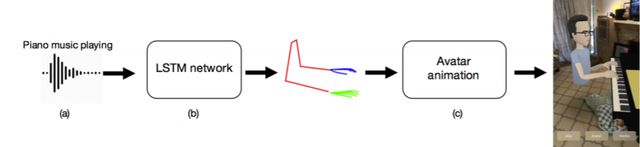
最近,facebook又又公布了一篇论文,名叫“音频到身体动力学”,讲的就是如何以3D动画的形式将一段音频转化为演奏时的肢体动作。依据人的动作,发出声音,我们已经见过许多,但根据声音,模拟出相应动作,这还是首次。

想要进行这种转化,就需要知道每个音符所对应的演奏者可能会做出的动作。按照传统方法,自然是请几位演奏家到实验室内,在他们的手指和身体关节处贴上传感器,再让他们演奏上几个小时。但这种方法实施起来还是有些麻烦,怕麻烦的研究人员想出了一个更好的点子。
不知道大家还记不记得去年这个时候曾流传过一个用黑科技合成奥巴马说话的视频。华盛顿大学的研究人员分析了14个小时的奥巴马讲话的视频,判断奥巴马在讲话时其脸部是如何运动的,如嘴唇、牙齿、面部皱纹以及下巴的活动,再通过神经网络与人工智能技术根据海量数据掌握了与不同声音相关联的嘴型,因此只要随意放出一段音频就可以制作奥巴马讲话的视频。
正是受到了“奥巴马”的启发,facebook的研究人员也采用了相似的视频学习方法。研究人员通过检测视频中每一帧中的上半身和手指来处理视频。每帧上取50个点,其中每只手占21个点,上半身占8个点。接着,分别通过OpenPose、MaskRCNN 和DeepFace三个库运行视频,其中OpenPose提供面部,身体和手部关键点,MaskRCNN 和DeepFace则为人脸识别算法。
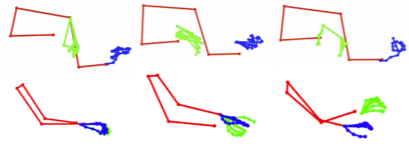
当然在采集过程中,也是成功与失败并存。为了采集的数据更精准,研究人员在每段视频中都选择一帧作为参考帧。倘若在参考帧附近的连续帧中有与参考帧参数相差较大的帧,例如面部、手部关键点不匹配,则自动消除掉那一帧。下图手部糊在一起的便是失败帧。
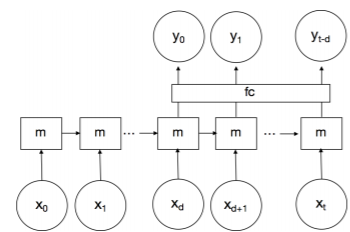
研究人员的目标是学习音频特征和身体动作之间的相关性,因此,完成了关键点采集,便要构建一个Long-Short-TermMemory(LSTM长短期记忆)网络开始学习音频特征和身体骨架标志之间的相关性了。

这也与“奥巴马”那个使用的是同款学习网络。研究人员选择使用具有时间延迟的单向单层LSTM。 xi是特定时间实例i的音频MFCC特征,yi是身体关键点的PCA系数,m是存储器(隐藏状态)。研究人员还添加了一个标记为'fc'的完全连接层,经过试验发现它可以提高系统学习效率。
最后动画的生成是基于ARkit实现的。研究人员使用ARkit构建了一个增强现实应用程序,该应用程序可以在手机上实时运行。使用带有骨骼的3D身体模型,通过将预测点与3D世界坐标对齐来初始化动画形象。研究人员通过所有帧平均下拉的左右肩点距离计算得出模型的刚性变换数据。然后再分别考虑身体,手臂和手指。对于身体,研发人员创建了一条IK链,其中根节点定义为左右臀部之间的平均值,并连接到左肩和右肩的平均值。然后,估计所有帧的平均脊柱长度,并据此相应地缩放动画模型的脊柱。对于手臂,以手腕为参考点,由前臂长度决定偏移量。对于手指,通过小指的根关节和指针的根关节确定手的旋转。最后,应用根旋转偏移来匹配琴与人的姿势角。
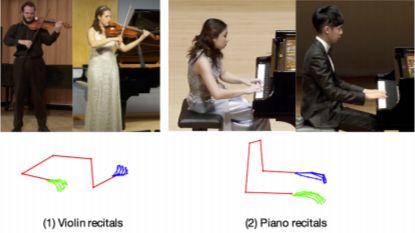
除了钢琴,还有小提琴的演奏

虽然目前这个应用还仅限于钢琴与小提琴演奏的转化,但是相信随着进一步的开发,将支持更多种乐器演奏的转化。甚至于将来还有可能发展出除乐器之外其他形式的转化,比如,放一段音乐,可以Freestyle出一段舞蹈;再比如,根据一段霹雳扒拉的拳打脚踢声,生成一段3D动画的打斗场面。总之,能够依声定形还是很有趣的。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

