使用迁移学习加强你的图像搜索
图像相似度正如你可能知道的,反向图像搜索的问题是寻找相似的图像。但是如何定义图像相似性呢?给出两个样本图像,从视觉上我们可以很容易地确定它们是否相似。我们如何通过编程来做到这一点?一种非常简单的方法将基于与图像关联的元数据



图像相似度
正如你可能知道的,反向图像搜索的问题是寻找相似的图像。
但是如何定义图像相似性呢?给出两个样本图像,从视觉上我们可以很容易地确定它们是否相似。我们如何通过编程来做到这一点?
一种非常简单的方法将基于与图像关联的元数据。换句话说,我们可以将图像大小、RGB值、类别标签等元数据信息与每张图像关联起来。
许多web应用程序仍然利用这种方法进行反向图像搜索。此类应用程序通常将此类元数据存储在ElasticSearch?或Solr?等优化文本搜索平台中。这种方法很简单,但存在许多缺陷。最明显的一个是需要大量的手工工作来标记每个图像。
一种更复杂的、基于计算机视觉的技术是从图像本身提取不同的特征。传统的计算机视觉算法,如SIFT和SURF,在提取特征时具有很强的鲁棒性,可以通过比较特征来识别相似的图像。
SIFT、SURF和其他一些传统方法都擅长从输入图像中提取关键特征。图1描述了如何利用基于SIFT的特征来查找类似的图像。
图1:基于SIFT特征的图像相似性。它非常适用于坚硬或不变的物体。这个例子展示了两张从不同角度拍摄的自由女神像的照片。使用彩色线条显示了两个图像之间的前50个匹配特征。

这个是一个快速和强大的方法,在我们有坚硬对象的场景中非常有用。
例如,用矩形盒子如包装盒或圆形圆盘如表盘等识别图像,用这种方法是非常有效的。另一方面,不那么坚硬的物体很难匹配。例如,两个不同的人体模型以不同的姿势展示同一件衬衫/裙子,这可能会让传统技术难以处理。
你可能知道,可以尝试使用基于元数据的方法或甚至使用传统的基于计算机视觉的技术来识别类似的图像。两者都有各自的优点和缺点。现在让我们从深度学习的角度来探索图像的相似性。
图像特征与迁移学习
迁移学习可以用于特征提取、微调和预训练设置。
回顾cnn的特征提取,我们知道预训练的模型中的初始层可以理解图像。
在迁移学习的帮助下,我们可以训练由预训练好的网络作为特征提取器,然后再训练几个浅层。
反向图像搜索用例巧妙地利用了预训练模型的特征提取特征(迁移学习)。
让我们利用预训练好的ResNet-50将图像转化为特征。这些特征通常是密集的一维向量。将输入转换为向量的过程也称为向量化。
我们首先需要准备一个预训练ResNet-50模型的实例。接下来,我们需要一个实用函数来预处理输入图像并得到向量输出。代码清单1给出了实现。
代码清单1:使用预训练的ResNet-50将图像转换为特征向量
# 获取预训练模型的工具函数
def get_pretrained_model(name):
if (name == 'resnet'):
# keras API轻松使用预训练模型
model = ResNet50(weights='imagenet',
include_top=False,
input_shape=(224, 224, 3),
pooling='max')
else:
print("Specified model not available")
return model
# 将图像转换为矢量的实用函数
def extract_features(img_path, model):
input_shape = (224, 224, 3)
img = image.load_img(img_path,
target_size=(input_shape[0], input_shape[1]))
img_array = image.img_to_array(img)
expanded_img_array = np.expand_dims(img_array, axis=0)
preprocessed_img = preprocess_input(expanded_img_array)
features = model.predict(preprocessed_img)
flattened_features = features.flatten()
normalized_features = flattened_features / norm(flattened_features)
return normalized_features
# 获取一个随机图像的特征向量
features = extract_features('101_ObjectCategories/Faces/image_0003.jpg',
model)
如果我们仔细看一下清单1中的代码,keras API使得准备预训练模型的实例和使用它来进行我们预期的特征提取非常容易。
如图所示,该函数将图像输入转换为2048维密集向量输出。2048维向量是从ResNet模型的平均池化层中获得的,该模型在没有分类层的情况下实例化。
注意:我们利用ResNet-50来获得图像向量,但我们可以自由使用任何其他预训练模型。我们只需要记住一些方面,例如预训练网络的领域和我们的反向图像搜索数据集以及输出向量的维数。
例如,如果我们用vgg -16来代替ResNet-50,特征向量就会减少到512维。我们将进一步讨论这些选择的影响。
在我们开始实际的反向图像搜索任务之前,我们需要一个数据集开始。为了说明目的,我们将使用加州理工学院101?数据集。这个数据集是由李飞飞和他的团队在2003年收集的,包含了大约40到800张图像,分别属于101个不同的对象类别。
该数据集具有相当高质量的图像,非常适合我们的理解目的。

我们已经准备了一个将图像转换为向量的工具,让我们利用相同的函数来获得参考数据集中图像的向量表示。这也有助于可视化这些向量,以更好地理解他们。
这个想法是,相似的物体/图像应该有附近的向量。但我们如何可视化一个2048维空间呢?为此,我们将采用一种降维技术,称为t-SNE。不用讲太多细节,把t-SNE看作是将高维向量转换为低维空间的方法,同时保持重要的特征。
有一个非常简化的例子,目前有一个非常长的杂货清单。将清单上的单个项目分类为蔬菜、水果、乳制品等少数类别,可以看作是向低维空间的转变,同时仍然保留重要特征。
在我们目前的情况下,我们将使用t-SNE将2048维向量转换为2维或3维。通过降低维度,我们可以很容易地可视化。
代码清单2展示了将我们的参考数据集转换为向量,然后为了可视化目的降低它们的维数。代码清单2:向量化Caltech-101数据集和基于t-SNE的降维
batch_size = 64
root_dir = '101_ObjectCategories/'
datagen = tensorflow.keras.preprocessing.
image.ImageDataGenerator(preprocessing_function=preprocess_input)
# ImageDataGenerator对象可以根据需要从磁盘读取
# 而不用占用大量内存
generator = datagen.flow_from_directory(root_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode=None,
shuffle=False)
num_images = len(generator.filenames)
num_epochs = int(math.ceil(num_images / batch_size))
start_time = time.time()
feature_list = []
# 模型预测是特征向量,因为最终的分类层被移除
feature_list = model.predict(generator, num_epochs)
end_time = time.time()
# 功能被规范化以避免缩放问题。
# 限制一个特征可能采用的值的范围,以确保一个或几个维度不会主导整个特征空间。
for i, features in tqdm(enumerate(feature_list)):
feature_list[i] = features / norm(features)
print("Num images = ", len(generator.classes))
print("Shape of feature_list = ", feature_list.shape)
print("Time taken in sec = ", end_time - start_time)
# output
Num images = 9144
Shape of feature_list = (9144, 2048)
Time taken in sec = 30.623387098312378
我们已经完成了一半,准备了一个反向图像搜索的解决方案。下一步使用这些特征来识别类似的图像。
ANNOY:超快的邻居搜索ANNOY是一个高度优化的超快的最近邻居搜索方法。ANNOY由Spotify开发,旨在为用户提供音乐推荐。由于每天有数百万用户在他们的手机和网络上使用它,实现的重点是速度和准确性。
ANNOY是用C++开发的,并且提供Python包装器,ANNOY是一个基于树的向量相似度搜索方法,它有效地利用了内存和并行处理。它提供了许多距离度量选项,如欧几里得、余弦、汉明等。
让我们在代码清单3中查看使用ANNOY来进行反向图像搜索的快速实现。
代码清单3 (a):基于ANNOY的反向图像搜索
from annoy import AnnoyIndex
annoy_index = AnnoyIndex(2048,'angular')
# 添加特征到annoy_index
for i in range(num_images):
feature = feature_list[i]
# 为每个annoy_index添加特征向量
annoy_index.add_item(i, feature)
# 构建40个搜索树
annoy_index.build(40)
annoy_index.save('annoy_caltech101index.ann')
# 测试搜索性能
%timeit annoy_index.get_nns_by_vector(feature_list[random_image_index],
5,
include_distances=True)
# 输出
1000 loops, best of 3: 770 ?s per loop
代码清单3 (b):测试基于ANNOY的反向图像搜索性能
# 测试一个更大的样本
def calculate_annoy_time():
for i in range(0, 100):
random_image_index = random.randint(0, num_images)
# 这个函数返回类似于查询的vector
indexes = annoy_index.get_nns_by_vector(feature_list[random_image_index],
5,
include_distances=True)
%time calculate_annoy_time()
# output
CPU times: user 139 ms, sys: 0 ns, total: 139 ms
Wall time: 142 ms
如清单3所示,使用ANNOY非常简单。它是高效的,搜索时间惊人的快。搜索结果也非常令人印象深刻,如图2所示。
图2:基于ANNOY的反向图像搜索。每一行表示一个搜索查询。最左边的列代表查询图像,最右边代表搜索结果。每个匹配结果都标有其与查询图像的欧氏距离。

在很大程度上,ANNOY克服了与搜索速度和内存需求相关的限制。
它还提供了一些额外的选项来进行调整,以进一步提高性能。其中一个与特征向量的大小有关。这也是很明显的。如果我们减少向量的大小,它将直接减少寻找邻居所需的内存大小。我们利用ResNet-50输出2048维向量。如果我们使用像VGG-16, VGG-19甚至是MobileNet这样的模型,VGG模型的特征向量将减少到512个,而MobileNet的特征向量将减少到1024个(几乎减少了50%的大小)。
除此之外,我们甚至可以利用典型的降维技术,如主成分分析(PCA)或甚至t-SNE,这是一些最广泛使用的技术。这样的技术可以帮助我们大幅减少特征向量的大小,从而减少总体的计算和内存需求(尽管这将与搜索性能进行权衡)。
优化近邻搜索方法的需求是如此之大,许多可扩展的解决方案已经开发了多年。
在不深入细节的情况下,诸如雅虎的LOPQ5,NGT6已经在商业应用程序应用。在同一直线上,Facebook AI相似性搜索或FAISS为GPU优化实现。
本节讨论的反向图像搜索的不同方法和实现是基于首先将图像转换为特征向量,然后是相似度搜索算法的核心思想。优化后的实现进一步关注内存的利用,同时返回结果的速度仍然非常快。
从这一节可以明显看出,反向图像搜索是一个活跃的研究领域,通过这些技术,研究人员正在不断地突破边界。这些方法的成功开辟了越来越多的用例,其中反向图像搜索是一个重要的方面。
现在我们对反向图片搜索有了一个很好的理解,我们可以使用这些知识从电子商务网站轻松地找到类似的产品,甚至从一组照片中删除重复。
同样,反向图片搜索也被Flickr等服务广泛使用,用于推荐类似图片、谷歌购物、Pinterest的“相似”功能、亚马逊的产品扫描仪,识别剽窃作品。
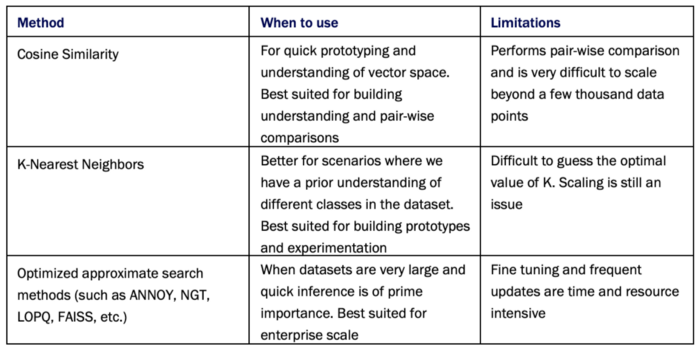
不同的场景需要不同的技术,表1简要介绍了本节中讨论的每种方法,以供快速参考。
表1:各种邻域搜索方法的总结
参考文献

原文标题 : 使用迁移学习加强你的图像搜索
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

