在 R 中使用 Keras 构建深度学习图像分类器
介绍深度学习和人工智能的一个重要应用是图像分类。图像分类是根据图像所包含的特定特征或特征对图像进行标记的过程。该算法识别这些特征并利用它们来区分图像并为它们分配标签。卷积神经网络 (CNN) 是深度学习图像分类模型的主要构建块,通常用于图像识别、图像分类、对象检测和其他类似任务



介绍
深度学习和人工智能的一个重要应用是图像分类。图像分类是根据图像所包含的特定特征或特征对图像进行标记的过程。该算法识别这些特征并利用它们来区分图像并为它们分配标签。
卷积神经网络 (CNN) 是深度学习图像分类模型的主要构建块,通常用于图像识别、图像分类、对象检测和其他类似任务。
Python 广泛用于图像分类问题。TensorFlow 和 Keras 是用于在 Python 中构建图像分类器的两个流行包。但是,这两个库也可以在 R 环境中使用。本文介绍了在 R 中使用 Keras 构建深度学习图像分类器模型的分步方法。
MNIST 时尚图像分类器
我们将构建一个图像分类器,可以对服装图像进行分类,例如连衣裙、衬衫和夹克。

我们将使用 Fashion MNIST 数据集,该数据集包含 70,000 张灰度图像。每张图像都是灰度 28 x 28 图像,分为 10 个不同的类别。每个图像都附有一个标签。总共有十个标签:
· T恤/上衣
· 裤子
· 套衫
· 裙子
· 外套
· 凉鞋
· 衬衫
· 运动鞋
· 包
· 踝靴
让我们首先导入所有必需的库。
library(keras)
library(tidyverse)
然后使用以下命令直接从 Keras 导入 Fashion MNIST 数据集。此外,将使用 60,000 张图像来训练模型,并使用 10,000 张图像来评估模型对图像进行分类的学习效果。
fashion_mnist <- dataset_fashion_mnist()
c(train_images, train_labels) %<-% fashion_mnist$train
c(test_images, test_labels) %<-% fashion_mnist$test
我们现在有四个数组:train_images 和 train_labels 数组包含训练集,这是模型用来训练的数据。该模型针对测试集进行验证,包括 test_images 和 test_label 数组。
每张图片都是一个 28 x 28 的数组,像素值范围从 0 到 255。标签是从 0 到 9 的整数数组。这些与衣服的类别有关。之后,为每个图像分配一个标签。因为类名不包含在数据集中,我们将使用以下命令将它们保存在向量中,并在稍后绘制图像时使用它们。
class_names = c('T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot')
在我们训练模型之前,让我们看一下数据集的格式。使用下面的命令,我们将打印训练图像和训练标签的尺寸,它们是 60,000 张图像,每张 28 × 28 像素。
dim(train_images)
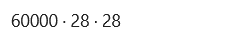
dim(train_labels)
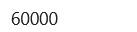
同样,使用以下命令打印测试图像和测试标签的尺寸,即 10,000 张图像,每张图像的大小为 28 x 28 像素。
dim(test_images)
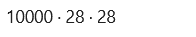
dim(test_labels)
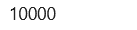
然后,我们将使用以下命令查看数据集中的示例图像。
options(repr.plot.width=7, repr.plot.height=7)
sample_image <- as.data.frame(train_images[7, , ])
colnames(sample_image) <- seq_len(ncol(sample_image))
sample_image$y <- seq_len(nrow(sample_image))
sample_image <- gather(sample_image, "x", "value", -y)
sample_image$x <- as.integer(sample_image$x)
ggplot(sample_image, aes(x = x, y = y, fill = value)) +
geom_tile() + scale_fill_gradient(low = "white", high = "black", na.value = NA) +
scale_y_reverse() + theme_minimal() + theme(panel.grid = element_blank()) +
theme(aspect.ratio = 1) + xlab("") + ylab("")

在训练模型之前,必须对数据进行预处理。为了减少像素值,我们必须对数据进行归一化。目前,所有图像像素的值都在 0-255 之间,我们想要介于 0 和 1 之间的值。因此,我们将所有像素值除以 255.0 分为训练集和测试集。
train_images <- train_images / 255
test_images <- test_images / 255
为确保数据格式正确,让我们查看训练集中的前 30 张图像。我们还将在每个图像下方显示类名。
options(repr.plot.width=10, repr.plot.height=10)
par(mfcol=c(10,10))
par(mar=c(0, 0, 1.5, 0), xaxs='i', yaxs='i')
for (i in 1:30) {
img <- train_images[i, , ]
img <- t(apply(img, 2, rev))
image(1:28, 1:28, img, col = gray((0:255)/255), xaxt = 'n', yaxt = 'n',
main = paste(class_names[train_labels[i] + 1]))}

现在是时候建立我们的模型了。
构建模型
要构建神经网络,我们需要如下配置模型的层:
1.卷积或Conv2D层:卷积层从图像或图像的一部分中提取特征。我们在这里指定三个参数:
· 过滤器——这是将在卷积中使用的过滤器的数量。例如,32 或 64。
· 内核大小——卷积窗口的长度。例如 (3,3) 或 (4,4)。
· 激活函数——例如,ReLU、Leaky ReLU、Tanh 和 Sigmoid。
2.Pooling 或 MaxPooling2D 层:该层用于减小图像的大小。
3.Flatten Layer:该层将n维数组缩减为一维。
4.Dense Layer:这一层是全连接的,这意味着当前层的所有神经元都链接到下一层。对于我们的模型,第一密集层有 128 个神经元,第二密集层有 10 个神经元。
5.Dropout Layer:为了防止模型过拟合,该层忽略了一组神经元(随机)。
model <- keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3),
activation = 'relu', input_shape = c(28, 28, 1)) %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = 10, activation = 'softmax')
在模型准备好进行训练之前,需要进行一些额外的设置。这些是在模型的编译步骤中添加的:
1.损失函数——这个函数评估我们的算法如何有效地表示数据集。根据我们的数据集,我们可以从“categorical_cross_entropy”
“binary_cross_entropy”和“sparse categorical_cross_entropy”等备选方案中进行选择。
2.优化器——有了这个,我们可以调整神经网络的权重和学习率。我们可以从许多优化器中进行选择,例如 Adam、AdaDelta、SGD 等。
3.Metrics – 这些用于评估我们模型的性能。例如,准确度、均方误差等。
model %>% compile(
loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = c('accuracy')
)
我们模型层中的所有参数和形状都可以使用“summary”函数查看,如下所示。
summary(model)

要开始训练,我们将调用 fit 方法,它将使用训练和测试数据以及以下输入来拟合我们的模型:
history % fit(x_train, train_labels, epochs = 20,verbose=2)
1.Epochs – 整个数据集通过神经网络向前和向后发送的次数。verbose – 查看我们输出的选择。例如,verbose = 0 不打印任何内容
2.verbose = 1 打印进度条和每个 epoch 一行,verbose = 2 每个 epoch 打印一行。
用 20 个 Epoch 运行模型后,我们得到了 97.36% 的训练准确率。
score % evaluate(x_train, train_labels)
cat('Train loss:', score$loss, "n")
cat('Train accuracy:', score$acc, "n")

我们可以使用以下命令绘制精度损失图以及 Epoch :
plot(history)

现在我们将看到模型在测试数据集上的表现:
score % evaluate(x_test, test_labels)
cat('Test loss:', score$loss, "n")
cat('Test accuracy:', score$acc, "n")

我们在测试数据集上获得了 91.6% 的准确率。我们可以利用训练好的模型对一些测试图像进行预测。
predictions % predict(x_test)
我们从模型中得到预测,即测试集中每个图像的标签。我们来看第一个预测:
predictions[1, ]

预测是一组十个数字。这些表达了模特的“信心”。
作为替代方案,我们还可以使用以下命令直接打印类预测:
class_pred % predict_classes(x_test)
class_pred[1:20]
现在我们将绘制一些带有他们预测的图像。正确的预测是蓝色的,而错误的预测是红色的。
options(repr.plot.width=7, repr.plot.height=7)
par(mfcol=c(5,5))
par(mar=c(0, 0, 1.5, 0), xaxs='i', yaxs='i')
for (i in 1:25) {
img <- test_images[i, , ]
img <- t(apply(img, 2, rev))
predicted_label <- which.max(predictions[i, ]) - 1
true_label <- test_labels[i]
if (predicted_label == true_label) { color <- 'blue' }
else
{ color <- 'red' }
image(1:28, 1:28, img, col = gray((0:255)/255), xaxt = 'n', yaxt = 'n',
main = paste0(class_names[predicted_label + 1],
"(",class_names[true_label + 1], ")"),col.main = color)}

这就是在 R 中使用 Keras 进行图像分类的方法!
结论
在本文中,我们学习了如何在 R 中使用 Keras 构建深度学习图像分类器。该模型在测试数据上具有很高的准确性。但是,必须记住,准确度可能会根据训练集而改变。因此,该模型不适用于与训练图像不同的图像。
以下是本文的一些主要内容:
Tensorflow 和 Keras 都有官方的 R 支持。就像 Python 一样,在 R 中设置和训练模型很容易。本文中的方法可以应用于另一个图像数据集进行分类,或者可以将训练好的模型保存并部署为应用程序。

原文标题 : 在 R 中使用 Keras 构建深度学习图像分类器
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

