GreenPlum数据分布机制
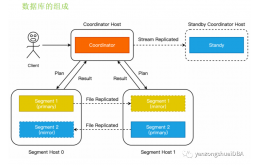
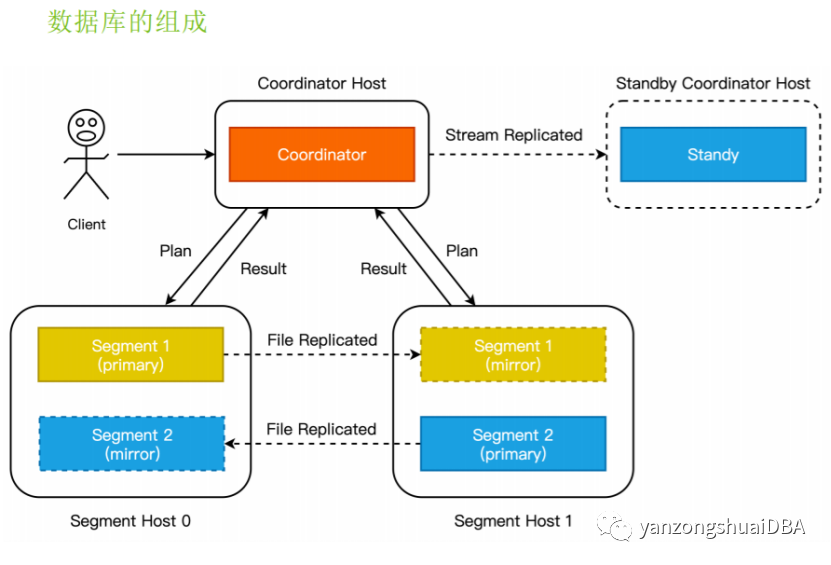
一、介绍GreenPlum是Coodinator/Segment架构,集群通常由一个Coodinator节点和一个standby coodinator节点以及多个segment节点组成,其中数据放置在segment节点上


一、介绍
GreenPlum是Coodinator/Segment架构,集群通常由一个Coodinator节点和一个standby coodinator节点以及多个segment节点组成,其中数据放置在segment节点上。Coodinator是整个数据库的入口,客户端只会连接到Coodinator上并执行相关查询操作,Standby节点为Coordinator提供高可用支持,Mirror为primary的备。
数据默认使用hash分布。
二、插入时数据是如何分布分发到哪个segment?
1、插入操作时值的由来
我们看下insert语句的执行计划:
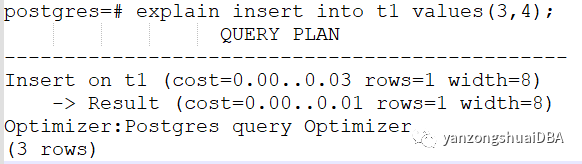
它没有Motion节点,仅1个slice,即root slice。Result节点是将insert的值物化以构建TupleTableSlot进行插入。也就是先物化然后insert。
这里主要关注物化的值从哪来。Result节点的执行堆栈为:

ExecInterpExpr计算物化值步骤:EEOP_CONST;EEOP_ASSIGN_TMP。也就是得到个常量值放到resultslot中。

通过gdb跟踪每个segment进程,可以了解到这里的常量值就是INSERT语句中VALUES的值。
此时就可以了解到,SQL语句中VALUES值是直接发送到对于的segment的。
那么,具体是如何发送的呢?
2、值的发送
发送函数由cdbdisp_dispatchX完成。我们来跟踪这个函数,看下是如何分发到指定的segment的。
了解GP原理的话,我们知道发送前需要先在master和segment之间建立一个连接,然后将执行计划通过这个连接发送过去。建立连接就是创建Gang,由函数AssignGangs完成。

最终创建Gang建立连接会调用函数cdbgang_createGang_async。下面我们看下这个函数是如何建立连接的。

cdbconn_doConnectStart连接时,SegmentDatabaseDescriptor segdbDesc中的segment_database_info::GpSegConfigEntry存有segment的端口及IP等信息,即gp_segment_configuration系统表中内容。基于此信息,可以建立连接。
那么segdbDesc内容从何而来?
从上述堆栈,segdbDesc是Gang中的db_descriptors[i],也就是buildGangDefinition函数生成:

SliceTable.slices[0].segments为入参segments链表,存储着执行该slice的所有segment的content id。segdbDesc是根据content id从系统表gp_segment_config来获取。
到这里可以知道,通过SliceTable中的segment链表得到该slice的segment的content。Insert仅一个slice,insert分发到执行该insert的segment,content就是该segment的content id。通过该content id从gp_segment_configuration系统表中得到相关port、IP等信息,从而据此在master和segment之间建立连接。构建链接后,insert语句通过此链接发送到对应的segment。
那么content id又是如何与分布键联系起来呢?
经过分析,由函数DirectDispatchUpdateContentIdsForInsert来完成映射:
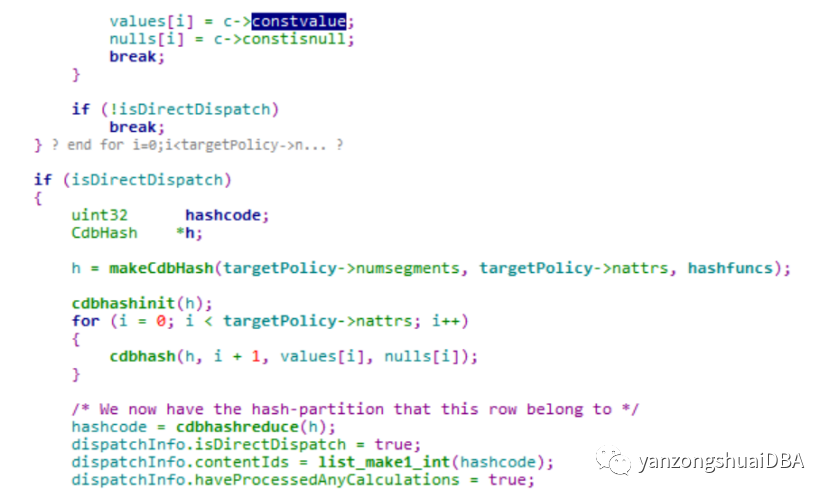
constvalue为分布键的key值,然后通过cdbhash函数通过系统hash函数将key值进行hash,最终得到hashcode,该值即为content id,放到contentIds链表中。
三、基础知识1、gp_segment_configuration

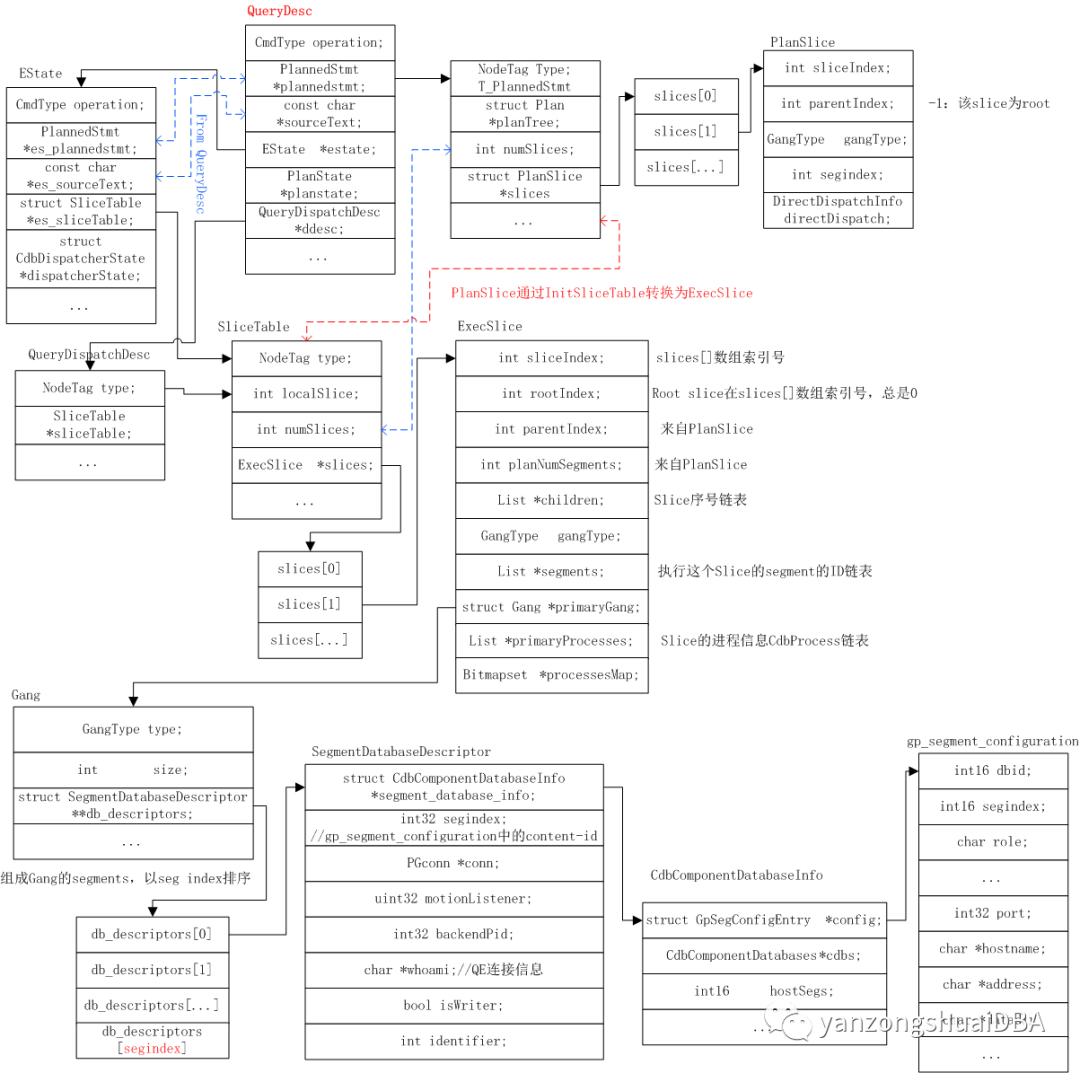
2、Gang、slice与QueryDesc之间关系
原文标题 : GreenPlum数据分布机制
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

