更加实用的姿态估计
本文?将通过强调推理过程中的一个关键问题来讨论如何使姿势估计算法更有效,并讨论如何缓解这个问题。?还介绍了一个示例,使得姿势估计变得更加实用。关键词:human pose-estimation, ji


本文?将通过强调推理过程中的一个关键问题来讨论如何使姿势估计算法更有效,并讨论如何缓解这个问题。?还介绍了一个示例,使得姿势估计变得更加实用。
关键词:human pose-estimation, jitter, low-pass filter, signal.
人体姿势估计是计算机视觉中非常具有挑战性的问题之一,其目标是定位人体关键点(如臀部、肩部、手腕等)。
它有无数的应用程序,包括AR、基于VR的游戏(如Microsoft Kinect)、交互式健身、治疗、运动捕捉等。结果的逐帧平滑对于这些应用程序的任何用途都至关重要。

抖动问题
几乎每种姿态估计算法在推理过程中都存在抖动问题。点周围关键点的高频振荡是噪声信号的特征,称为抖动。

抖动原因可归因于我们在整个视频输入的帧级别上执行这些推断。这些连续的帧具有不同的遮挡(以及一系列复杂的姿势)。另一个原因可能是训练数据中注释的不一致性导致姿势估计的不确定性。抖动会带来以下问题:
1. 故障数据和噪声数据会导致算法性能下降。
2. 关键点太过嘈杂,无法在生产环境中构建任何有用的功能和应用程序。
3. 获得假阳性数据点的概率很高。
4. 例如:假设你想使用姿势估计建立一个静止记分器(对于做冥想的人来说),这些抖动会显著影响分数,导致结果不准确。
抖动问题的解决方案
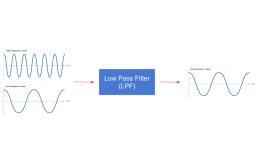
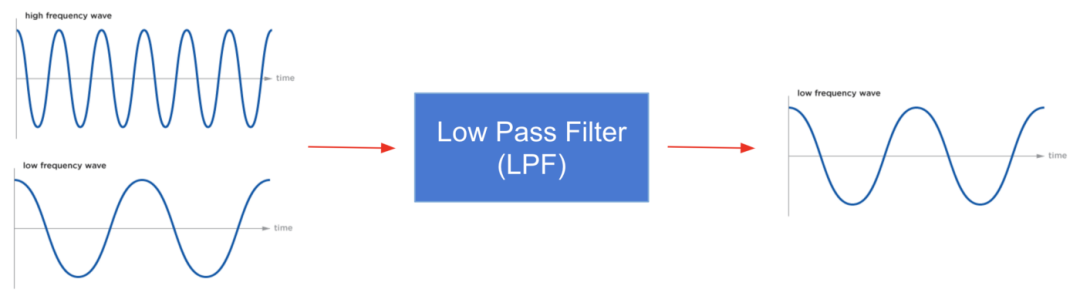
信号处理提供了两种主要的方法来衰减信号中的噪声。低通滤波器:将信号中的所有频率衰减到指定阈值频率以下,并使其余信号保持不变的滤波器。
高通滤波器:一种滤波器,将信号中的所有频率衰减到指定阈值频率以上,并使其余信号保持不变。
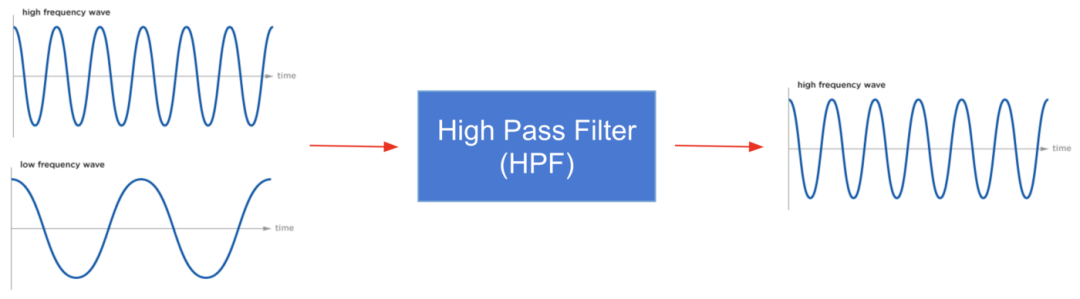
我们的自然运动是低频信号,而抖动是高频信号。因此,为了解决抖动问题,我们可以使用低通滤波器来过滤所有更高频率的信号。
解决抖动问题的其他方法包括使用神经网络进行姿势优化。其中一个例子是SmoothNet。然而,LPF更容易实现和使用。LPF的另一个变体是One Euro滤波器,它在实时过滤噪声信号方面也非常强大。
Movenet姿态估计
让我们从一些代码开始,让LPF在python中工作。为了在本博客中进行说明,我使用了Tensorflow的Movenet姿势估计模型。这个模型非常快速和准确。
现在,让我们考虑一些将用于推理的简单函数。
tf.lite中提供了用于在tflite上运行推理的Python API。(参考:使用tflite在python中加载并运行模型)。
# Initialize the TFLite interpreter
input_size = 256
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
# Movenet model: Runs detection on an input image
def movenet(input_image):
# TF Lite format expects tensor type of uint8.
input_image = tf.cast(input_image, dtype=tf.uint8)
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], input_image.numpy())
interpreter.invoke() # Invoke inference.
# Get the model prediction.
kps = interpreter.get_tensor(output_details[0]['index'])
return kps
# Obtain inference from the Movenet model
def get_inference(image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Padding and Resizing the input image.
image = pad(image, input_size, input_size)
image = cv2.resize(image, (input_size, input_size))
input_image = image
# Movenet expects a [1, height, width, 3] tensor input
input_image = np.expand_dims(input_image, axis=0)
# Run model inference.
kps = movenet(input_image)[0]
return kps[0], image
使用以下命令在本地运行推理(首先,在克隆后执行“cd motion-detection”):
python -m inference.movenet_infer — path file.mp4 — lpf n
让我们看看使用Movenet模型的示例推断结果:

显然,推断看起来相当准确,延迟也很小。
现在,让我们回到一开始看到的抖动示例,看看如何解决抖动问题。为了便于演示,我们使用了低通滤波器。我们还可以使用Python-Scipy中流行的信号处理库,该库支持不同类型的低通滤波器(例如signal.lfilter模块)。
1? LPF的使用情况如下所示:
while True:
old_curr_kp, image = get_inference(frame2)
curr_kp = [x[:] for x in old_curr_kp] # deepcopy
if j == 0:
x_track = [OneEuroFilter(j, curr_kp[k][0], 0.6, 0.015) for k in range(num_kps)] # track for all keypoints
y_track = [OneEuroFilter(j, curr_kp[k][1], 0.6, 0.015) for k in range(num_kps)]
if lpf and j > 1:
for i in range(num_kps):
## x coordinate
curr_kp[i][0] = x_track[i](j, curr_kp[i][0])
## y coordinate
curr_kp[i][1] = y_track[i](j, curr_kp[i][1])
output = draw_pose(image, curr_kp)
output = cv2.cvtColor(output, cv2.COLOR_BGR2RGB)
outimage = np.asarray(output, dtype=np.uint8)
outimage = cv2.resize(outimage, size)
prev_kp = curr_kp
ret, frame2 = cap.read()
cframe = cap.get(cv2.CAP_PROP_POS_FRAMES)
j += 1
if not ret:
break
k = cv2.waitKey(1)
if k == ord('q') or k == 27:
break
cap.release()
cv2.destroyAllWindows()
使用以下命令在本地运行推理(使用LPF):(首先,克隆后执行“cd motion-detection”)
python -m inference.stillness_scorer — path file.mp4 — lpf y
应用程序示例
现在,让我们看一个非常简单的例子,在这个例子中,使用上述概念,姿势估计可以变得更加实用。
考虑下面的问题陈述:“只根据身体静止来给一个人冥想打分。”
除了姿势估计之外,你能想出一些其他技术来解决这个问题吗?
图像处理
也许我们可以使用简单的图像处理方法来解决这个问题。我们可以从两个连续帧开始,然后我们可以应用二进制阈值来获得减去的掩码;这里,白色像素的数量将指示静止。

这种方法很好,但当有一个风扇或一只猫在后台移动时,问题就会出现;在这种可能的情况下,这种方法将不会有效。因为移动的猫会成为掩码的一部分。目标是想出一种专门针对人类的方法。
图像(人体)分割
使用一些分割技术怎么样?我们可以使用分割专门分割出一个人,然后取两个连续分割帧的差值,检查白色像素的数量。局限性:当分割区域内有运动时,此方法不起作用。
姿态估计
这里,我们计算连续帧中特定身体部位关键点的欧氏距离。我们的最终分数是所有这些欧几里德距离的加权和。显然,如果一个人做了一些运动,关键点的欧几里德距离会更高,反之亦然。
得分:如果没有明显的移动,得分应该低。分数越低意味着冥想越好(基于身体静止,实际上有很多因素有助于良好的冥想,而不仅仅是静止)。
请注意,如果我们没有提前平滑姿势关键点,抖动将导致得分变高,从而导致糟糕和不准确的结果。下图显示了y轴上的运动分数与x轴上的时间。
首先,让我们看看分数在没有平滑的情况下是如何表现的。
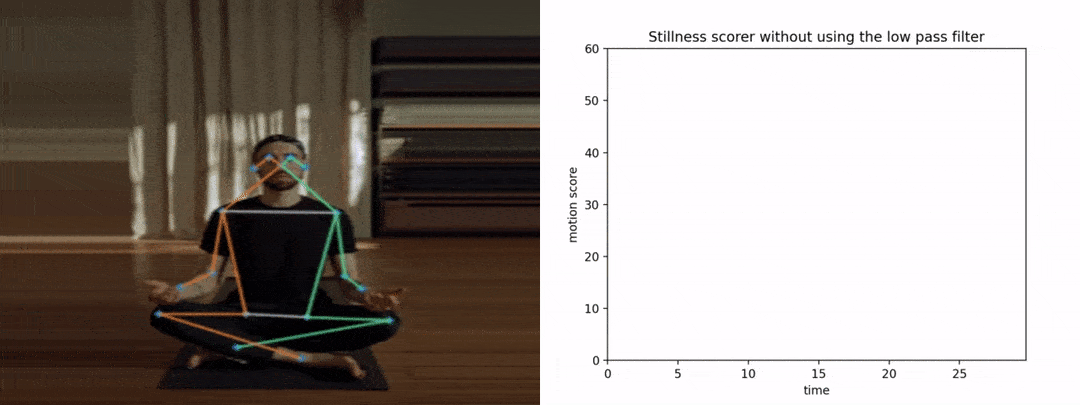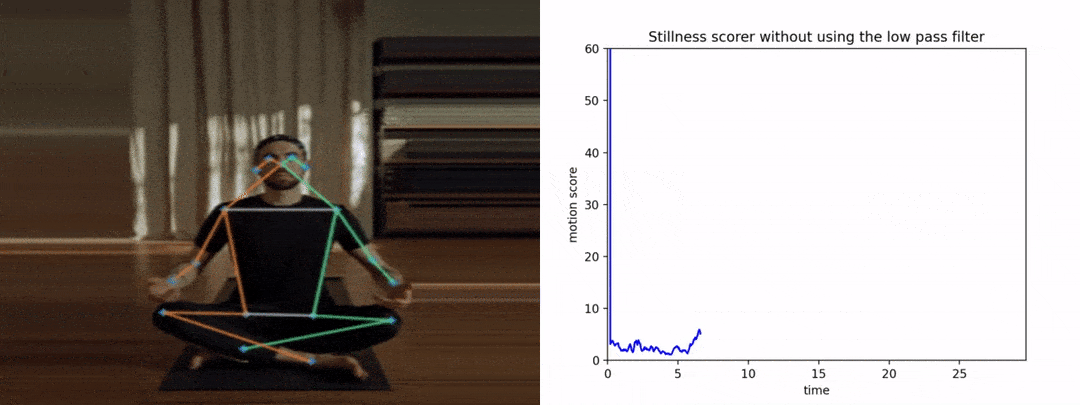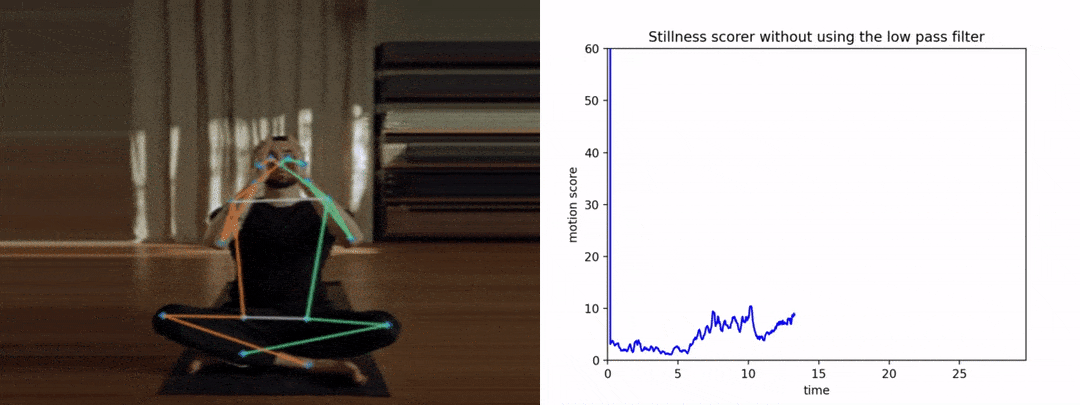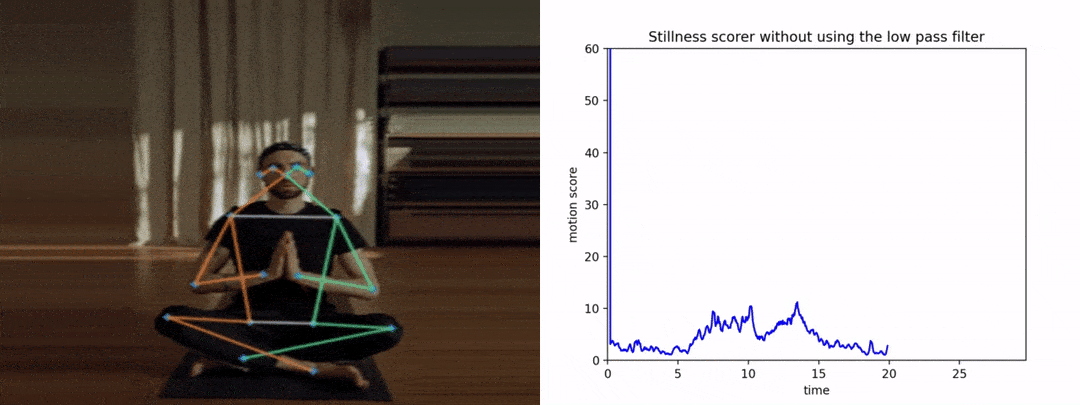
很明显,由于抖动,图形看起来很嘈杂。
让我们看看使用LPF的情况。
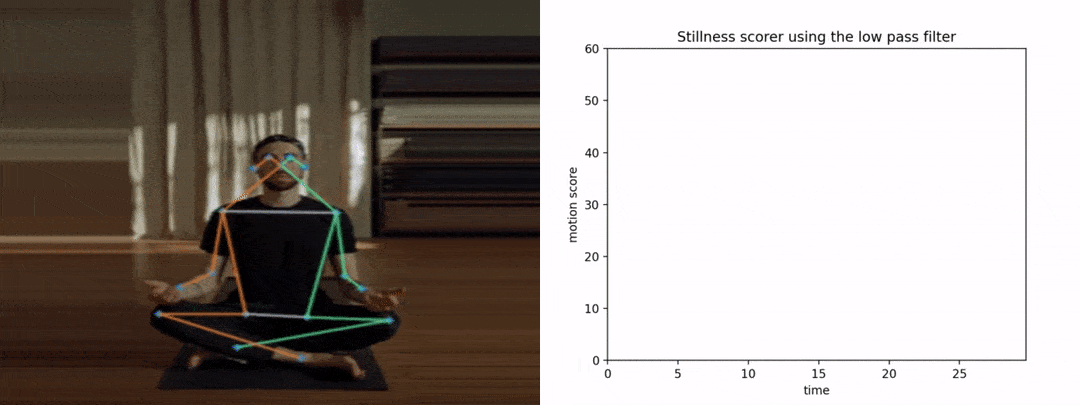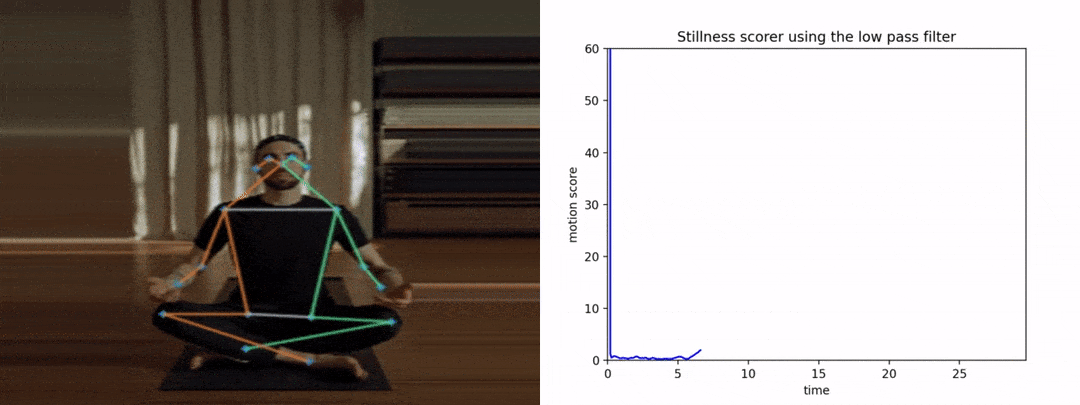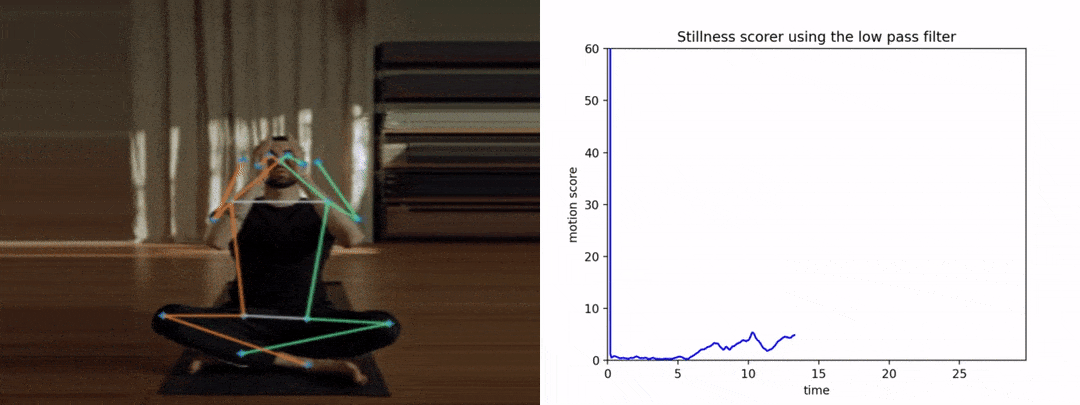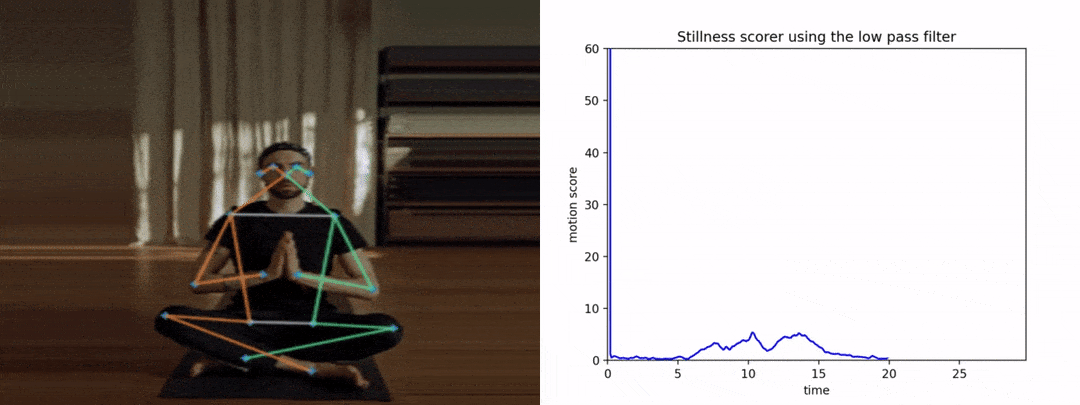
在这里,这次的图表看起来很平滑和干净。我们可以推断,任何运动都会影响曲线下的面积。因此,平滑关键点在此类应用中变得非常关键。
最终结果
还在android中集成了一个低通滤波器,并在自定义姿势估计模型上运行它。我们得到以下结果:

参考引用

希望你喜欢使用低通滤波器使姿势估计更加实用。希望这个例子足够合理,可以暗示在姿态估计的基础上构建应用程序时,消除抖动是最关键的优化之一。
原文标题 : 更加实用的姿态估计
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

