使用U-Net方法对航空图像进行语义分割
在机器学习中,模型是在各种应用中训练的,特别是在深度学习和图像数据集上。基于卷积运算的方法在许多领域都进行了研究,尤其是手臂检测、自动驾驶汽车、无人机航拍图像、战争技术。人眼能够很容易地对所看到的进行分类和区分


在机器学习中,模型是在各种应用中训练的,特别是在深度学习和图像数据集上。基于卷积运算的方法在许多领域都进行了研究,尤其是手臂检测、自动驾驶汽车、无人机航拍图像、战争技术。人眼能够很容易地对所看到的进行分类和区分。然而,在人工智能技术中,这种能力的等价物,即理解图像的问题,属于计算机视觉领域。顾名思义,计算机视觉是以计算机可以理解的方式引入(分类)图像,下一步是使用不同的方法对这些图像进行操作。本文介绍了一种分割方法,即U-Net体系结构,该体系结构是为生物医学图像分割而开发的,并包括一个实际项目,该项目使用U-Net对无人机捕获的航空图像进行分割。
目录
1.语义分割
2.U-Net架构
3.教程
3.1. 数据预处理
3.2. 基于U-Net的语义分割
3.3. 基于迁移学习的U-Net语义分割
4.结论
5.参考文献
语义分割
图像是由数字组成的像素矩阵。在图像处理技术中,对这些数字进行一些调整,然后以不同的方式表示图像,并使其适合相关研究或解释。
卷积过程是一种基本的数学像素运算,它提供了从不同角度评估图像的机会。
例如,可以使用滤波器进行图像的边缘检测,也可以通过将图像从RGB格式转换为灰度,从不同角度解释和使用图像。
基于深度学习模型和卷积层,人们对图像内容进行了更全面的研究,如特征提取和分类。

如上图所示,使用边界框检测图像内容中的对象称为对象检测。
语义分割是一种逐像素的标记操作,它用一个标签来显示图片中相同类型的对象(天空、猫、狗、人、路、车、山、海等),即颜色。
即时分割是指每个实例都被单独标记,通过以不同的颜色显示来分隔每个对象。
如上所述,在这些操作的背景下,针对不同的用途开发了各种彼此不同的CNN模型和复杂模型。PSPNet、DeepLab、LinkNet、U-Net、Mask R-CNN就是其中的一些模型。我们可以说,分割过程是基于机器学习的应用(如自动驾驶汽车)项目的核心。
总之,计算机视觉中的语义分割是一种基于像素的标记方法。如果相同类型的对象用单一颜色表示,则称为语义分割;如果每个对象用唯一的颜色(标签)表示,则称为实例分割。
U-Net体系结构
U-Net是一种特定类型的卷积神经网络架构,2015年在德国弗莱堡大学计算机科学系和生物信号研究中心为生物医学图像(计算机断层扫描、显微图像、MRI扫描等)开发。
当我们考虑技术思想时,该模型由编码器和解码器组成,编码器(收缩)是下采样(主要是迁移学习中的预训练权重),解码器(提取)是上采样部分,它被命名为U-Net,因为它的方案是U形的,如下图所示。该模型可根据不同的研究进行配置。
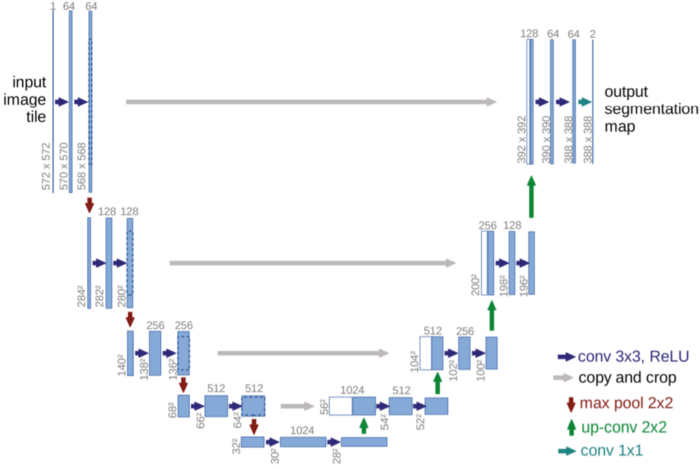
在以下教程中,为航空图像的语义分割配置了U-Net模型,如下所示:
# -*- coding: utf-8 -*-
"""
@author: Ibrahim Kovan
https://ibrahimkovan.medium.com/
"""
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenate, Conv2DTranspose, BatchNormalization, Dropout, Lambda
from tensorflow.keras import backend as K
def multiclass_unet_architecture(n_classes=2, height=256, width=256, channels=3):
inputs = Input((height, width, channels))
#Contraction path
conv_1 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(inputs)
conv_1 = Dropout(0.1)(conv_1)
conv_1 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_1)
pool_1 = MaxPooling2D((2, 2))(conv_1)
conv_2 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(pool_1)
conv_2 = Dropout(0.1)(conv_2)
conv_2 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_2)
pool_2 = MaxPooling2D((2, 2))(conv_2)
conv_3 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(pool_2)
conv_3 = Dropout(0.1)(conv_3)
conv_3 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_3)
pool_3 = MaxPooling2D((2, 2))(conv_3)
conv_4 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(pool_3)
conv_4 = Dropout(0.1)(conv_4)
conv_4 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_4)
pool_4 = MaxPooling2D(pool_size=(2, 2))(conv_4)
conv_5 = Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(pool_4)
conv_5 = Dropout(0.2)(conv_5)
conv_5 = Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_5)
#Expansive path
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(conv_5)
u6 = concatenate([u6, conv_4])
conv_6 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
conv_6 = Dropout(0.2)(conv_6)
conv_6 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_6)
u7 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(conv_6)
u7 = concatenate([u7, conv_3])
conv_7 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
conv_7 = Dropout(0.1)(conv_7)
conv_7 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_7)
u8 = Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(conv_7)
u8 = concatenate([u8, conv_2])
conv_8 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
conv_8 = Dropout(0.2)(conv_8)
conv_8 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_8)
u9 = Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(conv_8)
u9 = concatenate([u9, conv_1], axis=3)
conv_9 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
conv_9 = Dropout(0.1)(conv_9)
conv_9 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(conv_9)
outputs = Conv2D(n_classes, (1, 1), activation='softmax')(conv_9)
model = Model(inputs=[inputs], outputs=[outputs])
model.summary()
return model
def jacard(y_true, y_pred):
y_true_c = K.flatten(y_true)
y_pred_c = K.flatten(y_pred)
intersection = K.sum(y_true_c * y_pred_c)
return (intersection + 1.0) / (K.sum(y_true_c) + K.sum(y_pred_c) - intersection + 1.0)
def jacard_loss(y_true, y_pred):
return -jacard(y_true,y_pred)
如果我们采用上述代码块:
1、输入定义为256x256x3。
2、使用16个滤波器的conv_1,可获得256x256x16的输出。使用pool_1中的Maxpooling,它将减少到128x128x16。
3、使用32个滤波器的conv_2,可获得256x256x32的输出。使用pool_2,可获得64x64x32的输出。
4、使用64个滤波器的conv_3,可获得64x64x64的输出。使用pool_3,可获得32x32x64的输出。
5、使用128个滤波器的conv_4,可获得32x32x128的输出。使用pool_4,可获得16x16x128的输出。
6、使用256个滤波器的conv_5,可获得16x16x256的输出,并从此点开始进行上采样。在滤波器数量为128和(2x2)的u6中,conv_5通过Conv2DTranspose和级联得到32x32x128的输出,级联通过u6、conv_4执行。因此,u6输出为32x32x256。使用带有128个滤波器的conv_6,它将变为32x32x128。
7、滤波器数量为64且(2x2)的u7通过应用于conv_6并将u7与conv_3串联,变为64x64x64。此操作的结果是,u7被定义为64x64x128,并在conv_7中变为64x64x64。
8、滤波器数量为32和(2x2)的u8通过应用于conv_7并将u7与conv_2串联,变为128x128x32。此操作的结果是,u8被定义为128x128x64,并使用conv_8变为128x128x32。
9、通过应用于conv_8并将u9与conv_1串联,滤波器数量为16和(2x2)的u9变为256x256x16。此操作的结果是,u9被定义为256x256x32,并通过conv_9变为256x256x16。
10、输出使用softmax激活完成分类过程,最终输出采用256x256x1的形式。
使用不同速率的dropout来防止过拟合。
教程
在编码部分,可以使用不同的方法对数据集进行训练。
在本研究中,RGB(原始图像)数据集定义为x,并且该模型是通过使用真实标签(分割标记图像)作为y来训练的。在未来的文章中,还将讨论使用掩码数据集的方法。
RGB图像和标签如下图所示。该研究旨在用这种方法训练数据集,并使外部呈现的图像能够像训练数据一样进行分割。

它关注的是编码体系结构部分,而不是实现高性能。这是由于使用图像数据集时涉及的计算复杂性。
例如,虽然原始图像为6000x4000像素,但已将其转换为256x256像素以避免计算复杂性。通过这些操作,目的是通过放弃准确性来确保编码体系结构正常工作。
数据预处理
# -*- coding: utf-8 -*-
"""
@author: Ibrahim Kovan
https://ibrahimkovan.medium.com/
dataset: http://www.dronedataset.icg.tugraz.at/
dataset link: https://www.kaggle.com/awsaf49/semantic-drone-dataset
License: CC0: Public Domain
"""
#%% Libraries
"""1"""
from architecture import multiclass_unet_architecture, jacard, jacard_loss
from tensorflow.keras.utils import normalize
import os
import glob
import cv2
import numpy as np
from matplotlib import pyplot as plt
import random
from skimage.io import imshow
from PIL import Image
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import segmentation_models as sm
from tensorflow.keras.metrics import MeanIoU
#%% Import train and mask dataset
"""2"""
train_path = r"C:UsersibrahDesktopU-Netdataset raining_setimages.jpg"
def importing_data(path):
sample = []
for filename in glob.glob(path):
img = Image.open(filename,'r')
img = img.resize((256,256))
img = np.array(img)
sample.append(img)
return sample
data_train = importing_data(train_path)
data_train = np.asarray(data_train)
mask_path = r"C:UsersibrahDesktopU-Netdataset raining_setgtsemanticlabel_images.png"
def importing_data(path):
sample = []
for filename in glob.glob(path):
img = Image.open(filename,'r')
img = img.resize((256,256))
img = np.array(img)
sample.append(img)
return sample
data_mask = importing_data(mask_path)
data_mask = np.asarray(data_mask)
#%% Random visualization
x = random.randint(0, len(data_train))
plt.figure(figsize=(24,18))
plt.subplot(1,2,1)
imshow(data_train[x])
plt.subplot(1,2,2)
imshow(data_mask[x])
plt.show()
#%% Normalization
"""3"""
scaler = MinMaxScaler()
nsamples, nx, ny, nz = data_train.shape
d2_data_train = data_train.reshape((nsamples,nx*ny*nz))
train_images = scaler.fit_transform(d2_data_train)
train_images = train_images.reshape(400,256,256,3)
#%% Labels of the masks
"""4"""
labels = pd.read_csv(r"C:UsersibrahDesktopU-Netdataset raining_setgtsemantic/class_dict.csv")
labels = labels.drop(['name'],axis = 1)
labels = np.array(labels)
def image_labels(label):
image_labels = np.zeros(label.shape, dtype=np.uint8)
for i in range(24):
image_labels [np.all(label == labels[i,:],axis=-1)] = i
image_labels = image_labels[:,:,0]
return image_labels
label_final = []
for i in range(data_mask.shape[0]):
label = image_labels(data_mask[i])
label_final.append(label)
label_final = np.array(label_final)
#%% train_test
"""5"""
n_classes = len(np.unique(label_final))
labels_cat = to_categorical(label_final, num_classes=n_classes)
x_train, x_test, y_train, y_test = train_test_split(train_images, labels_cat, test_size = 0.20, random_state = 42)
1-导入库。从architecture import multiclass_unet_architecture中,定义了jacard,jacard_loss,并从上述部分导入。
2-6000x4000像素的RGB原始图像和相应标签的大小调整为256x256像素。
3-MinMaxScaler用于缩放RGB图像。
4-导入真实标签。数据集中有23个标签,并根据像素值将标签分配给图像。
5-标签数据集是用于分类的one-hot编码数据集,数据被分离为训练集和测试集。
使用U-Net的语义分割(从头开始)
#%% U-Net
"""6"""
img_height = x_train.shape[1]
img_width = x_train.shape[2]
img_channels = x_train.shape[3]
metrics=['accuracy', jacard]
def get_model():
return multiclass_unet_architecture(n_classes=n_classes, height=img_height,
width=img_width, channels=img_channels)
model = get_model()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=metrics)
model.summary()
history = model.fit(x_train, y_train,
batch_size = 16,
verbose=1,
epochs=100,
validation_data=(x_test, y_test),
shuffle=False)
#%%
"""7"""
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'y', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
acc = history.history['jacard']
val_acc = history.history['val_jacard']
plt.plot(epochs, acc, 'y', label='Training Jaccard')
plt.plot(epochs, val_acc, 'r', label='Validation Jaccard')
plt.title('Training and validation Jacard')
plt.xlabel('Epochs')
plt.ylabel('Jaccard')
plt.legend()
plt.show()
#%%
"""8"""
y_pred=model.predict(x_test)
y_pred_argmax=np.argmax(y_pred, axis=3)
y_test_argmax=np.argmax(y_test, axis=3)
test_jacard = jacard(y_test,y_pred)
print(test_jacard)
#%%
"""9"""
fig, ax = plt.subplots(5, 3, figsize = (12,18))
for i in range(0,5):
test_img_number = random.randint(0, len(x_test))
test_img = x_test[test_img_number]
ground_truth=y_test_argmax[test_img_number]
test_img_input=np.expand_dims(test_img, 0)
prediction = (model.predict(test_img_input))
predicted_img=np.argmax(prediction, axis=3)[0,:,:]
ax[i,0].imshow(test_img)
ax[i,0].set_title("RGB Image",fontsize=16)
ax[i,1].imshow(ground_truth)
ax[i,1].set_title("Ground Truth",fontsize=16)
ax[i,2].imshow(predicted_img)
ax[i,2].set_title("Prediction",fontsize=16)
i+=i
plt.show()
6-在训练过程中使用准确度和Jaccard指数。优化器设置为“adam”,损失设置为“categorical_crossentropy”,因为它只是一个复杂的分类问题。该模型配备了这些设置。
7-val_jaccard和训练过程的损失是可视化的。下图显示了val_jaccard。
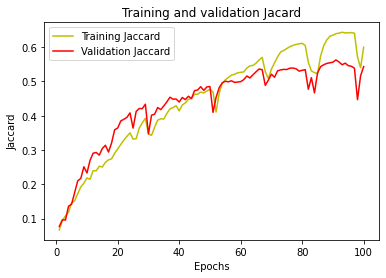
8-测试数据集的Jaccard系数计算为0.5532。
9-从测试数据集中选择5幅随机图像,用训练好的算法进行预测,结果如下图所示。

基于迁移学习的U-Net语义分割
#%% pre-trained model
"""10"""
BACKBONE = 'resnet34'
preprocess_input = sm.get_preprocessing(BACKBONE)
# preprocess input
x_train_new = preprocess_input(x_train)
x_test_new = preprocess_input(x_test)
# define model
model_resnet_backbone = sm.Unet(BACKBONE, encoder_weights='imagenet', classes=n_classes, activation='softmax')
metrics=['accuracy', jacard]
# compile keras model with defined optimozer, loss and metrics
#model_resnet_backbone.compile(optimizer='adam', loss=focal_loss, metrics=metrics)
model_resnet_backbone.compile(optimizer='adam', loss='categorical_crossentropy', metrics=metrics)
print(model_resnet_backbone.summary())
history_tf=model_resnet_backbone.fit(x_train_new,
y_train,
batch_size=16,
epochs=100,
verbose=1,
validation_data=(x_test_new, y_test))
#%%
"""11"""
history = history_tf
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'y', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
acc = history.history['jacard']
val_acc = history.history['val_jacard']
plt.plot(epochs, acc, 'y', label='Training IoU')
plt.plot(epochs, val_acc, 'r', label='Validation IoU')
plt.title('Training and validation Jaccard')
plt.xlabel('Epochs')
plt.ylabel('Jaccard')
plt.legend()
plt.show()
#%%
"""12"""
y_pred_tf=model_resnet_backbone.predict(x_test)
y_pred_argmax_tf=np.argmax(y_pred_tf, axis=3)
y_test_argmax_tf=np.argmax(y_test, axis=3)
test_jacard = jacard(y_test,y_pred_tf)
print(test_jacard)
#%%
"""13"""
fig, ax = plt.subplots(5, 3, figsize = (12,18))
for i in range(0,5):
test_img_number = random.randint(0, len(x_test))
test_img_tf = x_test_new[test_img_number]
ground_truth_tf=y_test_argmax_tf[test_img_number]
test_img_input_tf=np.expand_dims(test_img_tf, 0)
prediction_tf = (model_resnet_backbone.predict(test_img_input_tf))
predicted_img_transfer_learning=np.argmax(prediction_tf, axis=3)[0,:,:]
ax[i,0].imshow(test_img_tf)
ax[i,0].set_title("RGB Image",fontsize=16)
ax[i,1].imshow(ground_truth_tf)
ax[i,1].set_title("Ground Truth",fontsize=16
ax[i,2].imshow(predicted_img_transfer_learning)
ax[i,2].set_title("Prediction(Transfer Learning)",fontsize=16)
i+=i
plt.show()
10-使用resnet34重新准备数据集。将“Adam”设置为优化器,“categorical_crossentropy”设置为损失函数,并对模型进行训练。
11-val_jaccard和训练过程的丢失是可视化的。下图展示了val_jaccard。
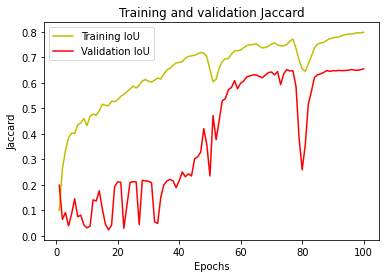
12-测试数据集的Jaccard索引值计算为0.6545。
13-从测试数据集中选择5幅随机图像,用训练好的算法进行预测,结果如下图所示。
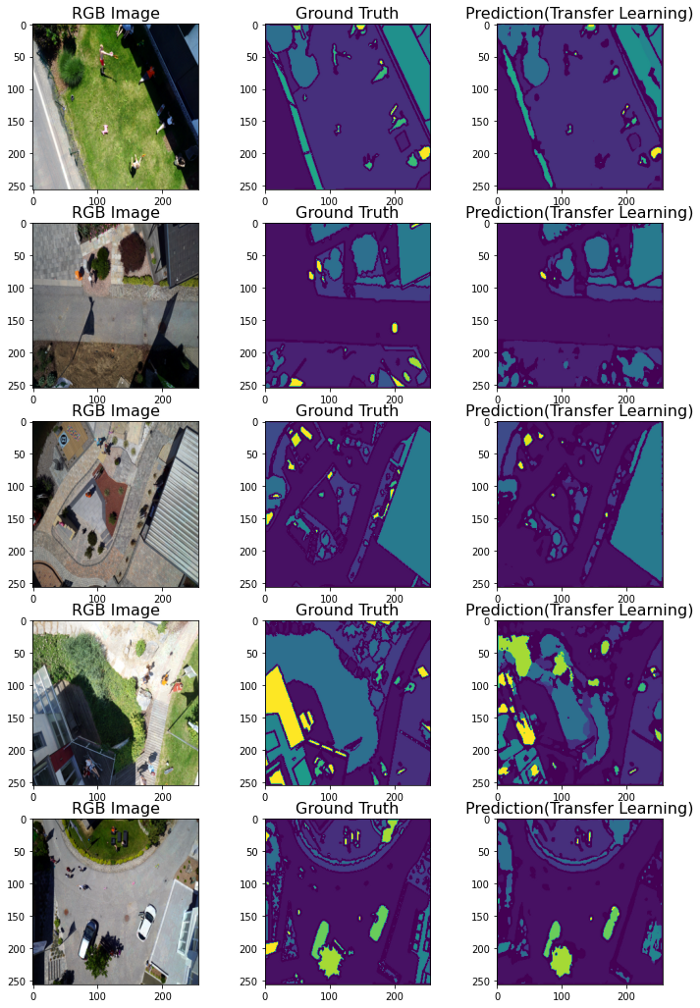
结论
本文提出了一种基于U-Net的卫星图像语义分割方法,该方法是为生物医学图像分割而开发的。
本研究考虑了两种主要方法。第一种方法涉及使用从头开始的实现来训练配置的u-net模型。第二种方法涉及使用迁移学习技术训练模型,即预训练权重。
在实现部分,对相应的带有真实标签的图像进行one-hot编码,并对模型进行分类训练。Jaccard系数作为度量。
"""14"""
fig, ax = plt.subplots(5, 4, figsize = (16,20))
for i in range(0,5):
test_img_number = random.randint(0, len(x_test))
test_img = x_test[test_img_number]
ground_truth=y_test_argmax[test_img_number]
test_img_input=np.expand_dims(test_img, 0)
prediction = (model.predict(test_img_input))
predicted_img=np.argmax(prediction, axis=3)[0,:,:]
test_img_tf = x_test_new[test_img_number]
ground_truth_tf=y_test_argmax_tf[test_img_number]
test_img_input_tf=np.expand_dims(test_img_tf, 0)
prediction_tf = (model_resnet_backbone.predict(test_img_input_tf))
predicted_img_transfer_learning=np.argmax(prediction_tf, axis=3)[0,:,:]
ax[i,0].imshow(test_img_tf)
ax[i,0].set_title("RGB Image",fontsize=16)
ax[i,1].imshow(ground_truth_tf)
ax[i,1].set_title("Ground Truth",fontsize=16)
ax[i,2].imshow(predicted_img)
ax[i,2].set_title("Prediction",fontsize=16)
ax[i,3].imshow(predicted_img_transfer_learning)
ax[i,3].set_title("Prediction Transfer Learning",fontsize=16)
i+=i
plt.show()
调整大小并不推荐,因为分割操作中的大小更改会出现不希望的偏移,但由于计算复杂性,数据集从6000x4000调整为256x256。因此,模型的成功率极低。防止这种情况的一些主要措施是使用高分辨率数据集和/或使用修补。
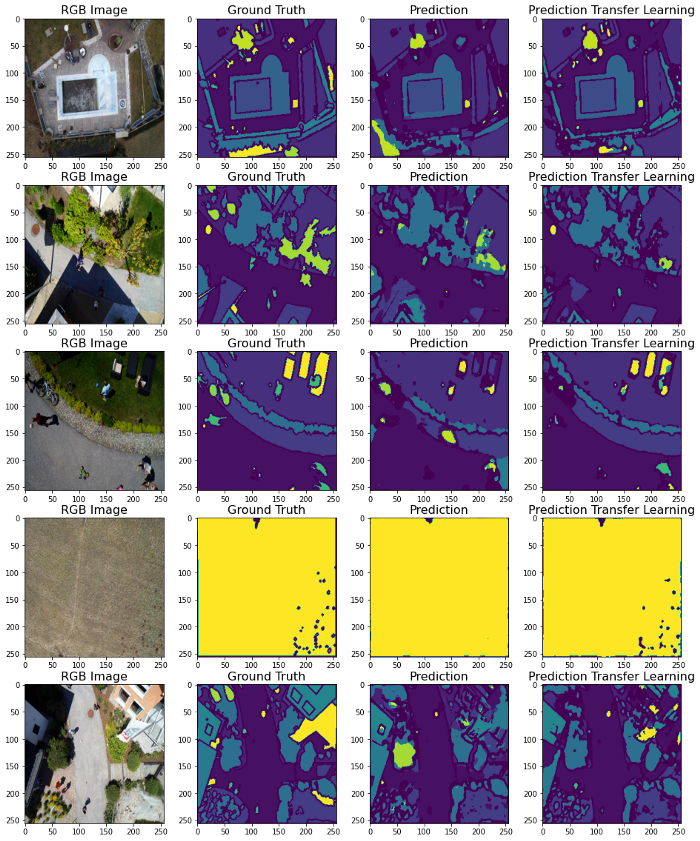
使用调整大小的数据集,评估了两种不同的方法,结果如图8所示。从Jaccard索引值来看,迁移学习方法得到的值为0.6545,而scratch构建模型得到的值为0.5532。可以看出,使用预训练模型得到的分割过程更为成功。
在以后的文章中,不同的编码方法将涵盖不同的方法。
参考引用
O. Ronneberger, P. Fischer, and T. Brox, “LNCS 9351 — U-Net: Convolutional Networks for Biomedical Image Segmentation,” 2015, doi: 10.1007/978–3–319–24574–4_28.
A. Arnab et al., “Conditional Random Fields Meet Deep Neural Networks for Semantic Segmentation,” IEEE Signal Process. Mag., vol. XX, 2018.
J. Y. C. Chen, G. F. Eds, and G. Goos, 2020_Book_VirtualAugmentedAndMixedReality. 2020.
J. Maurya, R. Hebbalaguppe, and P. Gupta, “Real-Time Hand Segmentation on Frugal Head-mounted Device for Gestural Interface,” Proc. — Int. Conf. Image Process. ICIP, pp. 4023–4027, 2018, doi: 10.1109/ICIP.2018.8451213.
原文标题 : 使用U-Net方法对航空图像进行语义分割
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

