分析计算机视觉模型的性能
最近了解了一个令人难以置信的工具,叫做Voxel51的FiftyOne,无法推荐它足够用于你的工作或研究。在文中,将解释如何使用该工具进行图像分类。介绍FiftyOne是一个开源工具,为数据集标记和计算机视觉模型分析提供了强大的图形界面
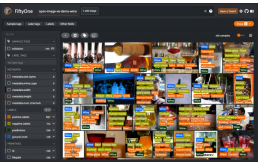
最近了解了一个令人难以置信的工具,叫做Voxel51的FiftyOne,无法推荐它足够用于你的工作或研究。在文中,将解释如何使用该工具进行图像分类。
介绍
FiftyOne是一个开源工具,为数据集标记和计算机视觉模型分析提供了强大的图形界面。“提高数据质量和了解模型的故障模式是提高模型性能的最有效方法。”[1]拥有一个标准化工具极大地加快和简化了数据和模型质量分析过程。作为一个开放源码项目是最重要的。该工具的官方文档写得很漂亮,可在以下位置获取:
该工具既可以作为独立应用程序运行,也可以在Jupyter笔记本中运行。
FiftyOne安装[1]
要安装FiftyOne,可以使用pip。使用以下命令创建名为fo的conda环境,然后使用pip安装FiftyOne库。
[注意:对于M1芯片的MacBooks,你需要手动设置MongoDB后端,因为捆绑的DB安装无法开箱即用。
conda create -n fo python=3.8 -y
conda activate fo
pip install fiftyone
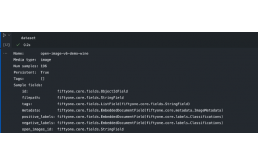
如果一切正常,你应该能够在python中加载包。接下来,我们将看两个基本的核心类,共有50个。
FiftyOne数据集和示例[2]
1.数据集:这个类是fiftyone的核心,具有强大的功能来表示数据,并使用python库和fiftyoneUI对其进行操作。你可以加载、修改、可视化和评估数据以及标签(分类、检测等)[2]
即使你有未标记的数据,也可以在FiftyOne应用程序中完成初始探索阶段。它还与CVAT和其他标签平台集成。数据集是Sample类的有序集合,它们被分配了用于检索的唯一ID。
你可以使用以下代码实例化名为“emotion-datase”的空数据集。
import fiftyone as fo
dataset = fo.Dataset("emotion-dataset")
dataset.persistent = True # Use this line if you want your dataset to be persistent and be avialable after system restarts.
2.示例:数据集由存储与任何给定数据示例相关的信息的示例类对象组成。每个示例都有一个文件路径作为必填字段。除此之外,只要数据类型在所有示例中一致,你可以添加任意多个关键字字段。让我们看看下面的一个例子。
sample = fo.Sample(filepath="/path/to/some/image.jpg", ground_truth="class1")
这将创建一个包含filepath和ground_truth字段的示例。请注意,对于整个数据集,ground_truth需要是字符串类名。如果要使用整数,则必须对整个数据集保持一致。
向数据集添加样本非常容易。
dataset.add_samples([sample]) #adds a list of samples to the dataset
方法论
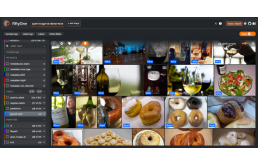
对于本教程,将使用FiftyOne库从Open Images v6数据集下载两个类[Wine,Bagel]。使用FiftyOne库是根据开放图像网站下载数据的推荐方法。
下面的代码将从验证拆分中下载Wine和Bagel类的图像,并将它们注册到open-image-v6-demo名称下。
import fiftyone as fo
dataset = foz.load_zoo_dataset("open-images-v6",
split="validation",
label_types=["classifications"],
classes=["Wine"],
seed=314,
dataset_name="open-image-v6-demo")
bagel_subset = foz.load_zoo_dataset("open-images-v6",
split="validation",
label_types=["classifications"],
classes=["Bagel"],
seed=314,
dataset_name="bagel-subset")
_ = dataset.merge_samples(bagel_subset)
在这一点上,我们有一个数据集,其中包含正标签和负标签字段以及其他一些字段。
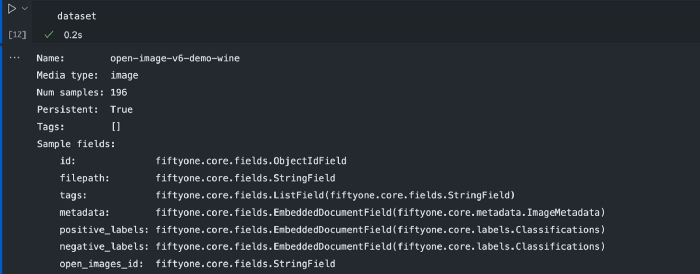
但是对于我们的示例评估,我们需要创建一个ground_truth字段,其中包含fo.Classification对象。
下面的代码将把ground_truth添加到所有感兴趣的相关示例中。我们首先基于Wine的positive_labels字段过滤数据集,然后向其添加ground_truth。
这里需要注意的是,你需要对每个样本调用save方法,以便将更改反映在数据库中。如果为一个示例创建了一个新字段,所有其他示例都将使用默认值None填充该字段。
通过这种方式,我们为数据集创建了Wine和Bagel ground_truth标签。
for sample in dataset.filter_labels("positive_labels" ,F("label")==("Wine")):
sample["ground_truth"] = fo.Classification(label="Wine") sample.save()
for sample in dataset.filter_labels("positive_labels" ,F("label")==("Bagel")):
sample["ground_truth"] = fo.Classification(label="Bagel") sample.save()
此时你可以启动FiftyOne应用程序,并开始查看下载的数据集。下面的代码将启动一个会话并让你查看数据。
session = fo.launch_app(dataset) # this will launch the fiftyone app
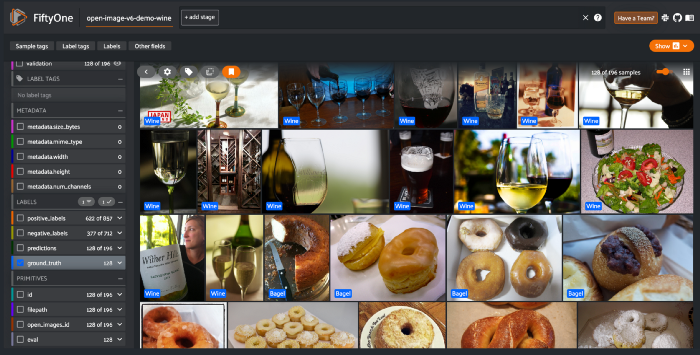
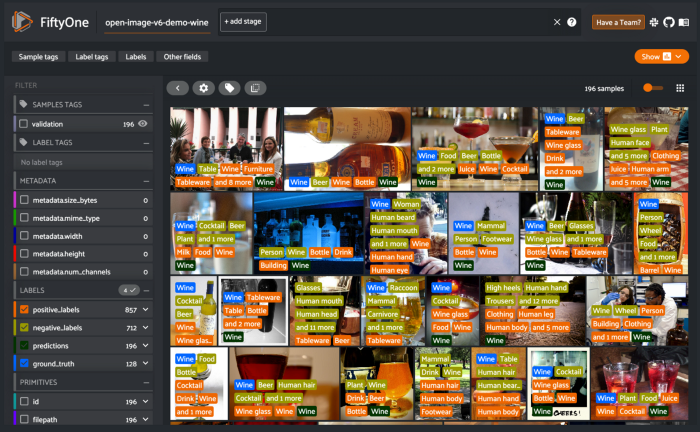
你可以快速滚动数据集并分析标签是否有意义。如果有任何错误的示例,你可以通过将鼠标悬停在图像上并选中复选框(或打开图像然后选择它)来选择它们。
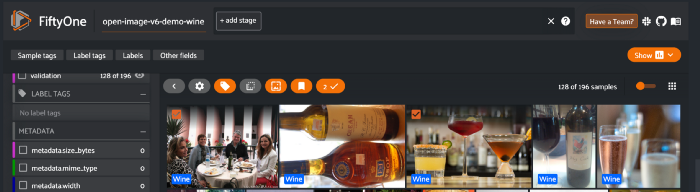
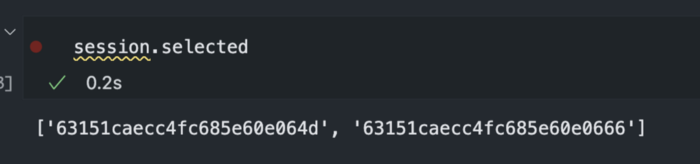
可以标记所有选定的图像以过滤掉这些图像。也可以使用session.selected属性访问选定的图像。这将为你提供所有选定样本的唯一ID。然后可以用来操纵这些样本。
现在我们需要使用一个模型来向数据集添加预测。Imagenet有三个类,称为“bagel”、“red wine”和“wine bottle”,可以用于我们从开放图像数据集下载的样本。
我们将使用预训练的模型对数据集进行预测,然后进行评估。我选择了在imagenet数据集上预训练的densenet169(PyTorch)模型。
import fiftyone.zoo as foz
model = foz.load_zoo_model("densenet169-imagenet-torch")
dataset.apply_model(model, label_field="predictions", store_logits=True)
此代码将向样本添加带有分类结果的预测标签字段。但是,它将为1000个imagenet类中的样本分配argmax类标签和置信度。
对于我们的用例,我们只需要与Wine和Bagel类别相关的那些。我们也通过指定store_logits=True将logits信息存储在预测字段中。接下来,我们找到感兴趣的类的相关类索引。
bagel_index = model.classes.index("bagel")
red_wine_index = model.classes.index("red wine")
wine_glass_index = model.classes.index("wine bottle")
现在,我们遍历数据集,并根据open image downloader生成的positive_label中的可用数据指定正确的ground_truth值。
我们通过添加“red wine”和“wine glass”softmax 值和 bagel_conficence 作为 bagel softmax 值来创建 wine_confidence。基于哪个置信度更大来分配预测标签。
for sample in dataset:
softmax_values = torch.softmax(torch.from_numpy(sample.predictions.logits),0).numpy()
wine_confidence = softmax_values[red_wine_index] + softmax_values[wine_glass_index]
bagel_confidence = softmax_values[bagel_index]
if wine_confidence>=bagel_confidence:
sample.predictions.label="Wine"
sample.predictions.confidence=wine_confidence
else:
sample.predictions.label="Bagel"
sample.predictions.confidence=bagel_confidence
sample.save()
现在我们已经在数据集中准备好了进行评估的一切。
FiftyOne性能评估
一旦为数据集中所有感兴趣的样本注册了ground_truth和预测,评估就非常快了。对于分类,我们可以查看分类报告和混淆矩阵进行分析。
我们对数据集进行过滤,只选择带有Wine或Bagel标签的ground_truth。然后使用这个过滤视图,我们运行evaluate_classifications方法。我们指定预测和ground_truth字段名以及eval键。这将计算sklearn风格的分类报告以及混淆矩阵。
oi_classes = ["Wine", "Bagel"]
eval_view = dataset.filter_labels("ground_truth" ,F("label").is_in(oi_classes))
results = eval_view.evaluate_classifications("predictions",
gt_field="ground_truth",
eval_key="eval")
要查看分类报告,我们可以简单地使用print_report方法。
results.print_report()
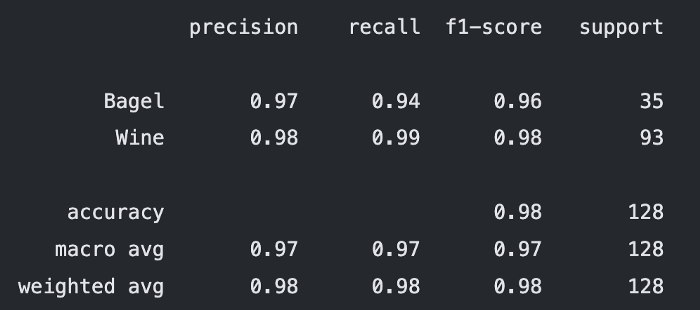
总是查看分类报告,以立即深入了解模型在类级别上的表现。在具有严重类别不平衡的数据集中,精度值可能会产生误导。然而,准确度、召回率和f1得分值显示了更真实的表现。查看此报告,你可以立即了解哪些类表现良好,哪些类表现不佳。
其次,混淆矩阵是分析分类器性能的另一个强大工具。使用ClassificationResults结果对象创建混淆矩阵。你可以使用plot_confision_matrix方法创建一个壮观的交互式热图对象。然后,可以将此绘图附加到会话中,以便进行交互式体验。
下面的代码创建了一个混淆矩阵并附加到会话中。
cm = results.plot_confusion_matrix()
cm.show()
session.plots.attach(cm)
你可以将鼠标悬停在矩阵中的每个单元格上,以查看总计数、真实标签和预测标签。
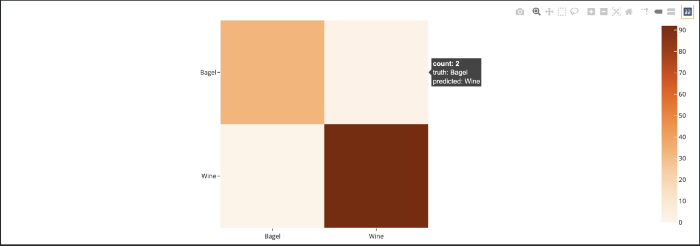
你还可以选择一个单独的单元格或一组单元格来动态过滤FiftyOneUI中的示例,以仅显示属于混淆矩阵中特定单元格的示例。这使得分析假阳性、假阴性和错误分类变得轻而易举!
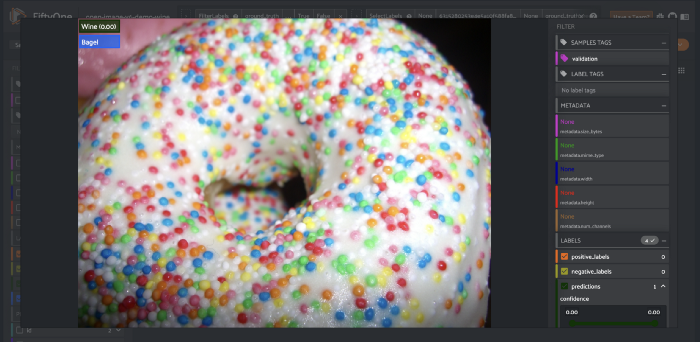
例如,如果我们想看到被错误分类为葡萄酒的百吉饼,我们只需点击右上角的单元格。
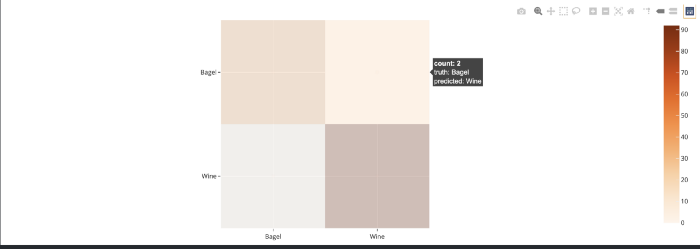
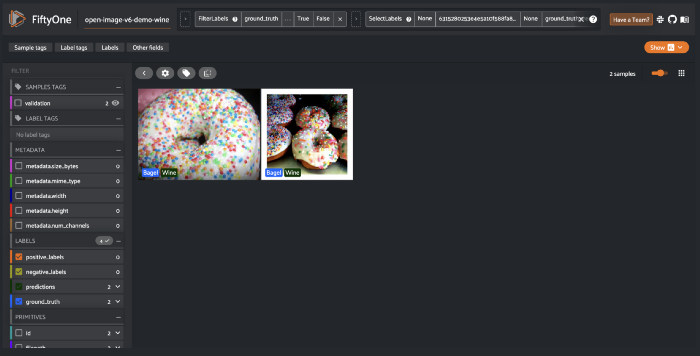
上图显示了单击混淆矩阵右上角单元格后的过滤视图。使用FiftyOne工具查找硬样本或发现错误注释是非常方便的。
访问这些示例非常简单。我点击了其中一张图片,观察到UI上显示的置信度为0.00。将鼠标悬停在详细浮动窗口中的标签上时,它显示的置信值为0.002。
但是,如果我们想以编程方式详细查看视图中的所有示例或某些选定的示例,我们可以轻松完成。
# if you want to iterate over all the samples in the current view
for sample in session.view:
softmax_values = torch.softmax(torch.from_numpy(sample.predictions.logits),0).numpy()
wine_confidence = softmax_values[red_wine_index] + softmax_values[wine_glass_index]
bagel_confidence = softmax_values[bagel_index]
print(wine_confidence, bagel_confidence)
# if you want to iterate over the selected samples in the datset
for sample in dataset[session.selected]:
softmax_values = torch.softmax(torch.from_numpy(sample.predictions.logits),0).numpy()
wine_confidence = softmax_values[red_wine_index] + softmax_values[wine_glass_index]
bagel_confidence = softmax_values[bagel_index]
print(wine_confidence, bagel_confidence)
这些样本可用于发现错误预测中的趋势和模式,并可用于获取新的训练数据以解决这些问题。
结论
总之,我们查看了FiftyOne库,这是一个用于分析模型性能的开源工具。
我们了解了Dataset、Samples和FiftyOne应用程序。接下来,我们从开放图像数据集[3]创建了一个数据集,并使用在图像网数据集[4]上预先训练的模型计算预测。我们还研究了如何创建分类报告和混淆矩阵。
FiftyOne中的混淆矩阵图是一个互动图。我们学习了如何将绘图附加到FiftyOne会话中,并交互式地过滤样本以分析错误的预测。
参考引用

原文标题 : 分析计算机视觉模型的性能
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

