使用Numpy从头构建卷积神经网络
使用该网络对手写数字进行分类。所获得的结果不是最先进的水平,但仍然令人满意。现在想更进一步,我们的目标是开发一个仅使用Numpy的卷积神经网络(CNN)。这项任务背后的动机与创建全连接的网络的动机相同:尽管Python深度学习库是强大的工具,但它阻止从业者理解底层正在发生的事情

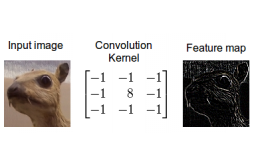
使用该网络对手写数字进行分类。所获得的结果不是最先进的水平,但仍然令人满意。现在想更进一步,我们的目标是开发一个仅使用Numpy的卷积神经网络(CNN)。
这项任务背后的动机与创建全连接的网络的动机相同:尽管Python深度学习库是强大的工具,但它阻止从业者理解底层正在发生的事情。对于CNNs来说,这一点尤其正确,因为该过程不如经典深度网络执行的过程直观。
解决这一问题的唯一办法是尝试自己实现这些网络。
打算将本文作为一个实践教程,而不是一个全面指导CNNs运作原则的教程。因此,理论部分很窄,主要用于对实践部分的理解。
对于需要更好地理解卷积网络工作原理的读者,留下了一些很好的资源。
什么是卷积神经网络?
卷积神经网络使用特殊的结构和操作,使其非常适合图像相关任务,如图像分类、对象定位、图像分割等。它们大致模拟了人类的视觉皮层,每个生物神经元只对视野的一小部分做出反应。此外,高级神经元对其他低级神经元的输出做出反应[1]。
正如我在上一篇文章中所展示的,即使是经典的神经网络也可以用于图像分类等任务。问题是,它们仅适用于小尺寸图像,并且在应用于中型或大型图像时效率极低。原因是经典神经网络需要大量的参数。
例如,200x200像素的图像具有40'000个像素,如果网络的第一层具有1'000个单位,则仅第一层的权重为4000万。由于CNN实现了部分连接的层和权重共享,这一问题得到了高度缓解。
卷积神经网络的主要组成部分包括:
· 卷积层
· 池化层
卷积层
卷积层由一组滤波器(也称为核)组成,当应用于层的输入时,对原始图像进行某种修改。滤波器是一种矩阵,其元素值定义了对原始图像执行的修改类型。类似以下的3x3内核具有突出显示图像中垂直边的效果:
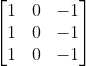
不同的是,该核突出了水平边:
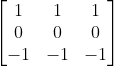
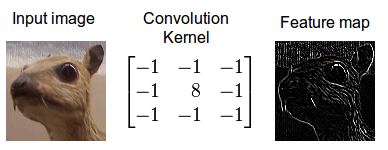
核中元素的值不是手动选择的,而是网络在训练期间学习的参数。
卷积的作用是隔离图像中存在的不同特征。Dense层稍后使用这些功能。
池化层
池化层非常简单。池化层的任务是收缩输入图像,以减少网络的计算负载和内存消耗。事实上,减少图像尺寸意味着减少参数的数量。
池化层所做的是使用核(通常为2x2维)并将输入图像的一部分聚合为单个值。例如,2x2最大池核获取输入图像的4个像素,并仅返回具有最大值的像素。
Python实现
此GitHub存储库中提供了所有代码。
这个实现背后的想法是创建表示卷积和最大池层的Python类。此外,由于该代码后来被应用于MNIST分类问题,我为softmax层创建了一个类。
每个类都包含实现正向传播和反向传播的方法。
这些层随后被连接在一个列表中,以生成实际的CNN。
卷积层实现
class ConvolutionLayer:
def __init__(self, kernel_num, kernel_size):
self.kernel_num = kernel_num
self.kernel_size = kernel_size
self.kernels = np.random.randn(kernel_num, kernel_size, kernel_size) / (kernel_size**2)
def patches_generator(self, image):
image_h, image_w = image.shape
self.image = image
for h in range(image_h-self.kernel_size+1):
for w in range(image_w-self.kernel_size+1):
patch = image[h:(h+self.kernel_size), w:(w+self.kernel_size)]
yield patch, h, w
def forward_prop(self, image):
image_h, image_w = image.shape
convolution_output = np.zeros((image_h-self.kernel_size+1, image_w-self.kernel_size+1, self.kernel_num))
for patch, h, w in self.patches_generator(image):
convolution_output[h,w] = np.sum(patch*self.kernels, axis=(1,2))
return convolution_output
def back_prop(self, dE_dY, alpha):
dE_dk = np.zeros(self.kernels.shape)
for patch, h, w in self.patches_generator(self.image):
for f in range(self.kernel_num):
dE_dk[f] += patch * dE_dY[h, w, f]
self.kernels -= alpha*dE_dk
return dE_dk
构造器将卷积层的核数及其大小作为输入。我假设只使用大小为kernel_size x kernel_size的平方核。
在第5行中,我生成随机滤波器(kernel_num、kernel_size、kernel_size),并将每个元素除以核大小的平方进行归一化。
patches_generator()方法是一个生成器。它产生切片。
forward_prop()方法对上述方法生成的每个切片进行卷积。
最后,back_prop()方法负责计算损失函数相对于层的每个权重的梯度,并相应地更新权重值。注意,这里提到的损失函数不是网络的全局损失。相反,它是由最大池层传递给前一卷积层的损失函数。
为了显示这个类的实际效果,我用32个3x3滤波器实例化了一个卷积层对象,并将正向传播方法应用于图像。输出包含32个稍小的图像。
原始输入图像的大小为28x28像素,如下所示:
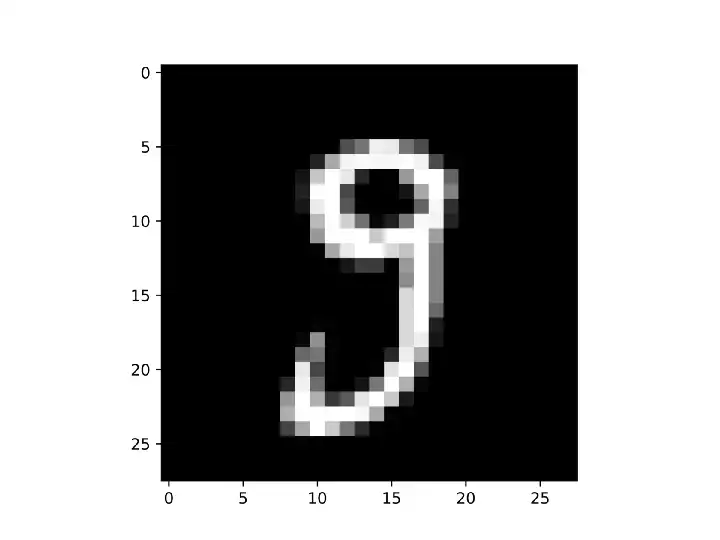
在应用卷积层的前向传播方法后,我获得了32幅尺寸为26x26的图像。这里我绘制了其中一幅:
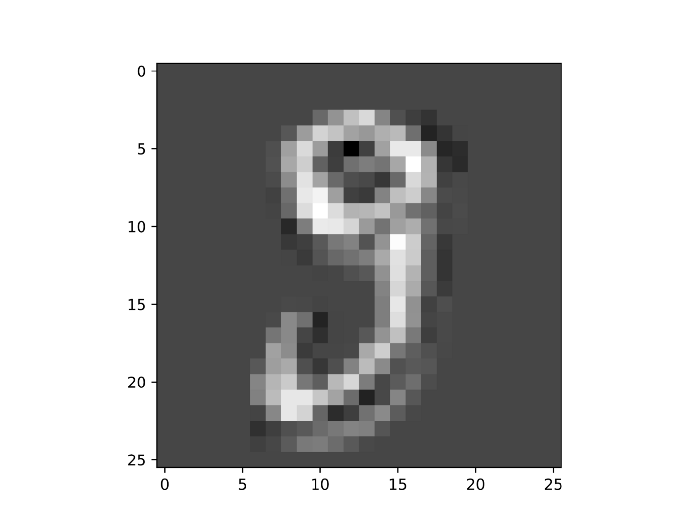
如你所见,图像稍小,手写数字变得不那么清晰。考虑到这个操作是由一个填充了随机值的滤波器执行的,所以它并不代表经过训练的CNN实际执行的操作。
尽管如此,你可以得到这样的想法,即这些卷积提供了较小的图像,其中对象特征被隔离。
最大池层实现
class MaxPoolingLayer:
def __init__(self, kernel_size):
self.kernel_size = kernel_size
def patches_generator(self, image):
output_h = image.shape[0] // self.kernel_size
output_w = image.shape[1] // self.kernel_size
self.image = image
for h in range(output_h):
for w in range(output_w):
patch = image[(h*self.kernel_size):(h*self.kernel_size+self.kernel_size), (w*self.kernel_size):(w*self.kernel_size+self.kernel_size)]
yield patch, h, w
def forward_prop(self, image):
image_h, image_w, num_kernels = image.shape
max_pooling_output = np.zeros((image_h//self.kernel_size, image_w//self.kernel_size, num_kernels))
for patch, h, w in self.patches_generator(image):
max_pooling_output[h,w] = np.amax(patch, axis=(0,1))
return max_pooling_output
def back_prop(self, dE_dY):
dE_dk = np.zeros(self.image.shape)
for patch,h,w in self.patches_generator(self.image):
image_h, image_w, num_kernels = patch.shape
max_val = np.amax(patch, axis=(0,1))
for idx_h in range(image_h):
for idx_w in range(image_w):
for idx_k in range(num_kernels):
if patch[idx_h,idx_w,idx_k] == max_val[idx_k]:
dE_dk[h*self.kernel_size+idx_h, w*self.kernel_size+idx_w, idx_k] = dE_dY[h,w,idx_k]
return dE_dk
构造函数方法只分配核大小值。以下方法与卷积层的方法类似,主要区别在于反向传播函数不更新任何权重。事实上,池化层不依赖于权重来执行。
Sigmoid层实现
class SoftmaxLayer:
def __init__(self, input_units, output_units):
self.weight = np.random.randn(input_units, output_units)/input_units
self.bias = np.zeros(output_units)
def forward_prop(self, image):
self.original_shape = image.shape
image_flattened = image.flatten()
self.flattened_input = image_flattened
first_output = np.dot(image_flattened, self.weight) + self.bias
self.output = first_output
softmax_output = np.exp(first_output) / np.sum(np.exp(first_output), axis=0)
return softmax_output
def back_prop(self, dE_dY, alpha):
for i, gradient in enumerate(dE_dY):
if gradient == 0:
continue
transformation_eq = np.exp(self.output)
S_total = np.sum(transformation_eq)
dY_dZ = -transformation_eq[i]*transformation_eq / (S_total**2)
dY_dZ[i] = transformation_eq[i]*(S_total - transformation_eq[i]) / (S_total**2)
dZ_dw = self.flattened_input
dZ_db = 1
dZ_dX = self.weight
dE_dZ = gradient * dY_dZ
dE_dw = dZ_dw[np.newaxis].T @ dE_dZ[np.newaxis]
dE_db = dE_dZ * dZ_db
dE_dX = dZ_dX @ dE_dZ
self.weight -= alpha*dE_dw
self.bias -= alpha*dE_db
return dE_dX.reshape(self.original_shape)
softmax层使最大池提供的输出体积变平,并输出10个值。它们可以被解释为与数字0–9相对应的图像的概率。
结论
你可以克隆包含代码的GitHub存储库并使用main.py脚本。该网络一开始没有达到最先进的性能,但在几个epoch后达到96%的准确率。
参考引用
原文标题 : 使用Numpy从头构建卷积神经网络
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

