人工智能可以取代同传翻译吗?
前阵子,一位同传翻译员声讨科大讯飞“AI同传造假”,在网上引起了轩然大波。人工智能和同传翻译由此成为大家热议的话题。今天,我们来谈一谈“人工智能翻译是否真的可以取代同传翻译员”?


前阵子,一位同传翻译员声讨科大讯飞“AI同传造假”,在网上引起了轩然大波。人工智能和同传翻译由此成为大家热议的话题。今天,我们来谈一谈“人工智能翻译是否真的可以取代同传翻译员”?
同声传译有多难?
同声传译最早出现在一战后的巴黎和会上,英法两国代表借助同声传译人员的帮助,完成了紧张的谈判。
如今,该技术依然在国际会议上扮演着极其重要的角色。据统计,95%的国际会议都有专业同声传译人员助力。
同传翻译员在台上能够将同传能力运用自如,需要平时大量的艰苦练习,即使是双语运用自如的专业人员,在实战之前,也要进行数年的锻炼。他们不仅需要事先学习、熟悉会议资料,还需要随机应变的能力。同声传译的工作方式也比较特殊,因为压力巨大,一般多人协同,在一场数小时的过程中,每人轮流翻译几十分钟。
相较之下,普通的口译工作则要简单不少。机器翻译如能代替同声传译无疑具有巨大的价值。
人工智能翻译的水平如何?
那么,人工智能同传翻译的能力究竟怎样?会不会抢走同传翻译员的饭碗呢?
今年上半年的博鳌亚洲论坛上,首次出现了AI同传。然而,现场配备的系统却掉了链子,闹出词汇翻译不准确、重复等低级错误。
客观来讲,人工智能或机器翻译技术在自然语言处理上,的确有许多突破。这些突破给人希望,让人畅想未来,但是,短期内的价值,更多体现在辅助翻译等领域。
当然,目前机器翻译已经取得非常大的进步,在衣食住行等常用生活用语上的中英翻译可以达到大学六级的水平,能够帮助人们在一些场景处理语言交流的问题,但距离人工同传以及高水平翻译所讲究的“信、达、雅”,还存在很大的差距。
目前的差距是由现有技术水平的限制决定的,机器翻译,又称为自动翻译,是利用计算机将一种语言转换为另一种语言,机器翻译技术的发展与计算机技术、信息论、语言学等学科的发展紧密相关。从早期的词典匹配,到结合语言学专家梳理的知识规则,再到基于语料库的统计学方法,随着计算能力的提升和多语言信息的积累,机器翻译技术开始在一些场景中提供便捷的翻译服务。
新世纪以来,随着互联网的普及,互联网公司纷纷成立机器翻译研究组,研发了基于互联网大数据的机器翻译系统,从而使机器翻译真正走向实用,市场上开始出现比较成熟的自动翻译产品。近年来,随着深度学习的进展,机器翻译技术得到了进一步的发展,促进了翻译质量的提升,使得翻译更加地道、流畅。
机器翻译的难点在哪里?
这里,简单介绍一下机器翻译的难点。整个机器翻译的过程,可以分为语音识别转换、自然语言分析、译文转换和译文生成等阶段。在此,以比较典型的、基于规则的机器同传翻译为例(参见下图),模块包含了:语音识别(语音转换为文本)、自然语言处理(语法分析、语义分析)、译文转换、译文生成和语音生成等模块。其中的技术难点主要是:语音识别、自然语言处理和译文转换等步骤。
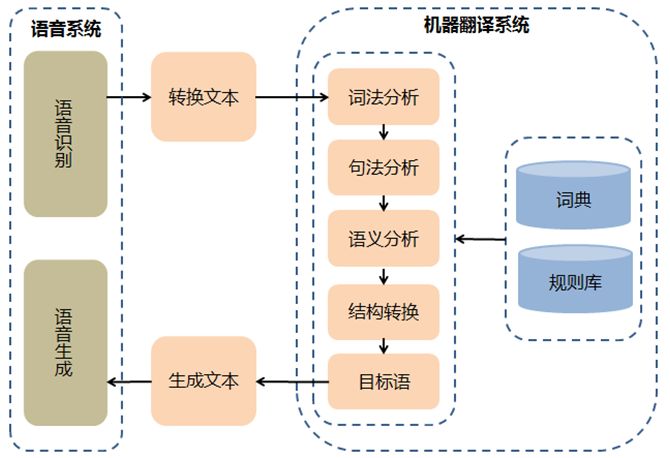
第一个技术难点是语音识别。近二十年来,语音识别技术取得了显著进步,开始进入家电、汽车、医疗、家庭服务等各个领域。常见的应用系统有:
语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;
语音控制系统,即用语音来控制设备的运行,相对于手动控制来说更加快捷、方便,可以用在诸如工业控制、语音拨号系统、智能家电、声控智能玩具等许多领域;
智能对话查询系统,根据客户的语音进行操作,为用户提供自然、友好的数据库检索服务,例如家庭服务、旅行社服务系统、订票系统、银行服务等。
可以说,语音识别技术与其他自然语言处理技术相结合,可以构建出很多复杂的应用。
然而,语音识别的主要难点就是对自然语言的识别和理解。首先必须将连续的讲话分解为词、音素等单位,其次要建立一个理解语义的规则。由于语音信息量大,语音模式不仅对不同的说话人不同,对不同场景的同一说话人也是有差异的。
例如,一个人在随意说话和认真说话时的语音特征是不同的。另外,说话者在讲话时,不同的词可能听起来是相似的,这也是常见现象。单个字母或词、字的语音特性,受上下文的影响,以致改变了重音、音调、音量和发音速度等。最后,环境噪声和干扰对语音识别也有较大影响,致使识别率低。
第二个技术难点是语义解析,这是智能化的机器翻译系统的核心部分。目前,机器翻译系统可划分为基于规则和基于语料库两大类。前者以词典和语言知识规则库为基础;后者由经过划分并具有标注的语料库构成知识源,以统计学的算法为主。
机译系统是随着语料库语言学的兴起而发展起来的。目前,世界上绝大多数机译系统都采用以规则库为基础的策略,一般分为语法型、语义型、知识型和智能型。不同类型的机译系统,由不同的成分构成。抽象地说,所有机译系统的处理过程都包括以下步骤:对源语言的分析或理解,在语言的语法、语义和语用等平面进行转换,按目标语言结构规则生成目标语言。
当前,Google 的在线翻译已经为人熟知,其第一代的技术即为基于统计的机器翻译方法,基本原理是通过收集大量的双语网页作为语料库,然后由计算机自动选取最为常见的词与词的对应关系,最后给出翻译结果。
不过,采用该技术目前仍无法达到令人满意的效果,经常闹出各种翻译笑话。因为,基于统计的方法,需要建立大规模的双语语料库,而翻译模型、语言模型参数的准确性直接依赖于语料的规模及质量,翻译质量直接取决于模型的质量和语料库的覆盖面。
除了上述传统的方式,2013年以来,随着深度学习的研究取得较大进展,基于人工神经网络的机器翻译逐渐兴起。就当前而言,广泛应用于机器翻译的是长短时记忆循环神经网络。该模型擅长对自然语言建模,把任意长度的句子转化为特定维度的浮点数向量,同时“记住”句子中比较重要的单词,让“记忆”保存比较长的会话时间。该模型较好地解决了自然语言句子向量化的难题。
其技术核心是通过多层神经网络,自动从语料库中学习知识。一种语言的句子被向量化之后,在网络中层层传递,经过多层复杂的传导运算,生成译文。这种翻译方法最大的优势在于译文流畅,更加符合语法规范。相比之前的翻译技术,质量有较高的提升。
智能同传翻译离我们还有多远?
需要说明的是,很多人对机器翻译有误解,认为机器翻译偏差大。其实,机器翻译运用语言学知识,自动识别语法,模拟语义理解,进行对应翻译,因语法、语义、语用的复杂性,出现错误是难免的。就已有的成果来看,全场景通用的机器翻译,其翻译质量离终极目标仍相差甚远。
随着全球化网络时代的到来,语言障碍已经成为二十一世纪社会发展的重要瓶颈,实现任意时间、任意地点、任意语言的无障碍自由沟通是人类追求的一个梦想。这仅是全球化背景下的一个小缩影。在社会快速发展的进程中,机器翻译将扮演越来越重要的角色。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

