这届智能客服有点优秀
转载本文需注明出处:微信公众号EAWorld,违者必究。作为早期在国内实现落地的AI应用场景,智能客服从2007年开始,就逐渐被企业应用,但这种智能客服大多采用预编程的方式解决客户问题,呈现出过于死板,不能多轮对话等“伪智能”特点,现在我们可以称其为第一代智能客服


转载本文需注明出处:微信公众号EAWorld,违者必究。
作为早期在国内实现落地的AI应用场景,智能客服从2007年开始,就逐渐被企业应用,但这种智能客服大多采用预编程的方式解决客户问题,呈现出过于死板,不能多轮对话等“伪智能”特点,现在我们可以称其为第一代智能客服。最近几年,随着计算机硬件、大数据、云计算、深度学习等技术的发展,很多大型企业,包括一些中小企业都升级到了新一代智能客服。
一套完整的智能客服系统一般包含语音识别(ASR)、自然语言理解(NLU)、对话管理(DM)、自然语言生成(NLG)、语音转换(TTS)等五个主要的功能模块(这里仅体现自然语言交互这种主要的人机交互方式),新一代智能客服系统最大的优势是能降低企业客服运营成本、提升用户体验。其具体框架结构如下:
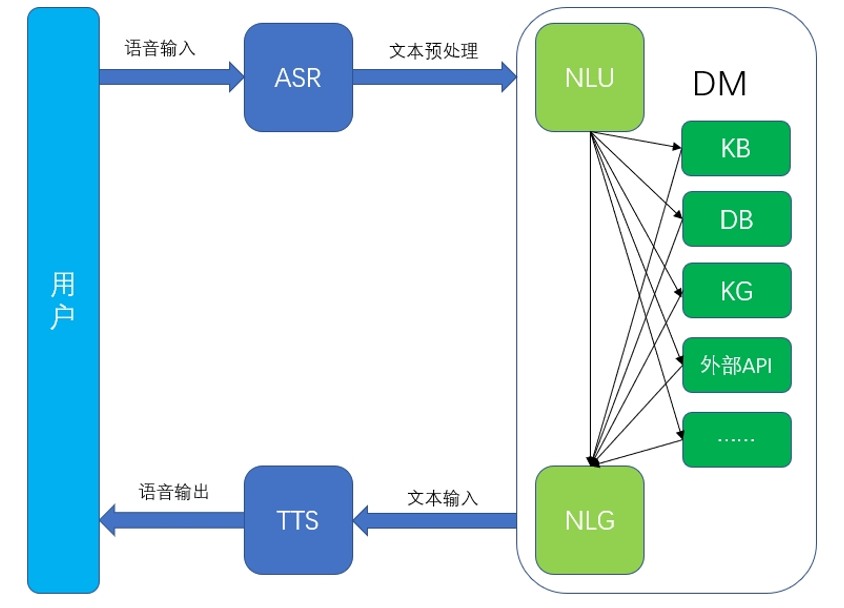
在这五大功能模块中,比较重要的模块是对话管理(DM)、自然语言理解(NLU)、自然语言生成(NLG),语音识别(ASR)与语音转换(TTS)是人机语音交互时才会使用到的模块。自然语言生成(NLG)由于其可控性较差,有时候生成的文本并不符合正常的语言逻辑,一般应用在对准确率要求不是太高的开放域对话中;而对话管理(DM)模块通常在多轮对话系统中才会用到,多轮对话系统作为人工智能领域的典型应用场景,也是一项极具挑战的任务,不仅涉及多方面异构知识的表示、抽取、推理和应用(如:语言知识、领域知识、常识知识等),还涉及包括自然语言理解(NLU),自然语言生成(NLG)在内的其他人工智能核心技术(如:用户画像, 情感分析等)的综合利用。
实现智能客服的方法,可以从最简单的“关键字匹配”,到最前沿的深度学习“端到端生成”应答。分别应用到不同的场景:问答(QA)、任务(垂直领域)、闲聊。
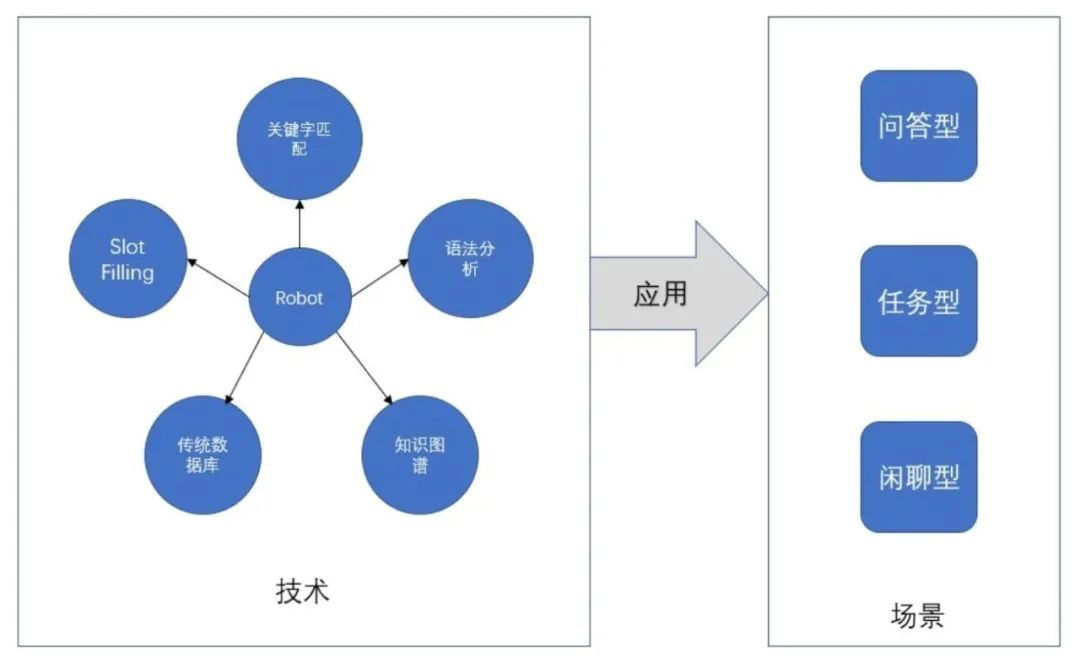
我们可以将对话系统从分成两层:
意图识别层:识别语言的真实意图,将意图进行分类并进行意图属性抽取。意图决定了后续的领域识别流程,因此意图层是一个结合上下文数据模型与领域数据模型不断对意图进行澄清与推理的过程。
响应匹配层:对问题进行匹配识别及生成答案的过程。由于用户问题的不可控特性,需要对用户问题进行初步的类型划分,并且依据问题类型采用不同的匹配流程和方法:
问答型:例如:“密码忘了怎么办?” ,可以采用基于知识图谱构建+检索模型的匹配方式。
任务型:例如:“订一张周五从北京到洛杉矶的机票。”,可以采用意图决策+slots filling的匹配方式。
闲聊型:例如“你的名字叫什么?” ,可以采用检索模型+一些Deep Learning相结合的方式。
意图识别:
语言的本质是为了传递人与人之间的信息(意图),那么,我们可以定义出N种意图分类。所以,一个语言模型就是一个多标签的数学模型,把自然语言转成具有结构化的表达,一般具有以下三个步骤:
文本预处理:分词、词向量、词义消解等。
样本准备:抽取一些有用信息。
序列模型:语言模型,如CNN与LSTM组合的神经网络或者其他的一些网络架构。
理解用户说话的意思,我们分为了三层:
第一层,是理解当前聊天处于哪一个话题,有没有切换话题;
第二层,是理解具体的内容,含有意图与实体;
第三层,是理解当前发言的情感,跟踪用户的情绪变化。
1)话题模型
话题模型是一个分类模型,与后面的应答引擎是有对应的关系,根据不同的话题,进入不同的业务流程,所以模型的标签的业务的分类。
2)意图理解
作为人机语言交互的重要核心技术意图理解也可看作是分类问题,为了能够准确识别用户当前的意图,一方面需要综合分析人机语言交互的上下文环境来决策用户意图,另一方面当意图不清时还需要运用响应的话术来引导用户澄清意图,比如在订票系统中“出发地、目的地、时间点、座位级别”等要素是离散地分布在一个会话中,在抽取保存这些关键信息的同时,还需要引导用户给出关键要素点。
为了能使单个Token充分地表示文本的局部特征以及全局的文本特征,自然语言处理领域的相关从业者把大量的工作重心放在了NLU上,传统模型的Pre-train手段就是语言模型,如ELMo模型就是以BiLSTM为基础架构、用两个方向的语言模型分别Pre-train两个方向的LSTM,后面的GPT、GPT2是用标准的、单向的语言模型来预训练。现在有了更多的Pre-train方法,比如Bert就用了“MLM-NSP”的方式来预训练,不过这是普通语言模型的一种变体;而XLNet则提出了更彻底的“Permutation Language Modeling”;还有UNILM模型,直接用单个Bert的架构做Seq2Seq,可以将它作为一种Pre-train手段,又或者干脆就用它来做 Seq2Seq任务……
除了单向语言模型及其简单变体掩码语言模型之外,UNILM的Seq2Seq预训练、XLNet的乱序语言模型预训练,基本可以说是专为Transformer架构定制的。其奥妙主要在 Attention矩阵之上。Attention实际上相当于将输入的Token两两地做算相似度计算,这构成了一个n2×n2大小的相似度矩阵(即Attention矩阵,n是文本长度,本文的 Attention均指Self-Attention),这意味着它的空间占用量是O(n2)量级,相比之下,RNN模型、CNN模型只不过是 O(n),所以实际上Attention通常更耗显存。然而,有弊也有利,更大的空间占用也意味着拥有了更多灵活度,我们可以通过往这个 O(n2)级别的Attention矩阵加入各种先验约束,使得它可以做更灵活的任务。而加入先验约束的方式,就是对Attention矩阵进行不同形式的Mask。
在Attention矩阵的每一行事实上代表着输出,而每一列代表着输入,而Attention矩阵就表示输出和输入的关联。所以,只需要在Transformer的Attention矩阵中引入下三角形形式的 Mask,并将输入输出错开一位训练,就可以实现单向语言模型。乱序语言模型跟语言模型类似,都是做条件概率分解,但是乱序语言模型的分解顺序是随机的。原则上来说,每一种顺序都对应着一个模型,所以原则上就有n!个语言模型。而基于Transformer的模型,则可以将这所有顺序都做到一个模型中去!也就是说,实现一种顺序的语言模型,就相当于将原来的下三角形式的Mask以某种方式打乱。正因为Attention提供了这样的一个n×n的Attention矩阵,我们才有足够多的自由度去以不同的方式去Mask这个矩阵,从而实现多样化的效果,在引入了鲁棒性的同时也融入了上下文特征。
3)情绪识别模型
情绪识别模型同样是一个分类模型,把用户的发言分为了以下几种不同级别的情绪:脏话、愤怒、懊恼、生气、平和、赞扬等。同时可能还需要对用户进行用户画像以及对用户进行实时的情感分析来综合判别用户意图,比如在导购类型的客服中经常要用到相关技术。
响应匹配:
目前主流的智能匹配技术分为如下4种方法:
1,基于模板匹配;
2,基于检索模型;
3,基于统计机器翻译模型;
4,基于深度学习模型;
在实际落地场景中大多采用基于模板匹配,检索模型以及深度学习模型为基础的方法原型来进行分场景(问答型、任务型、闲聊型等)的会话系统构建。
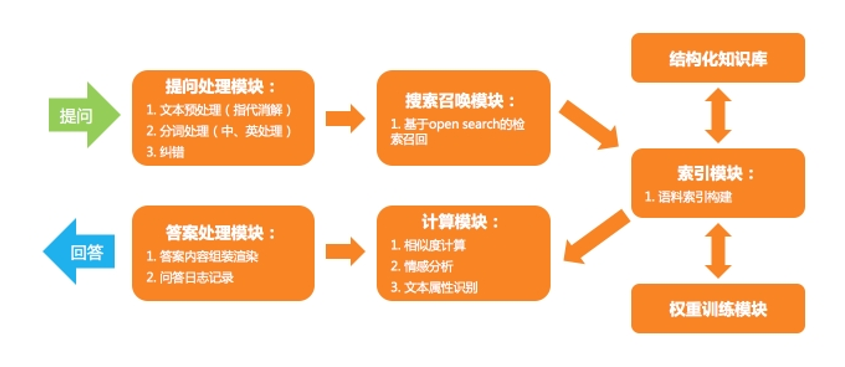
问答型场景一般解决方式为基于知识图谱构建+检索模型匹配。相应的使用到的技术是知识图谱构建+检索模型。模型的优点是在对话结构和流程的设计中支持实体间的上下文会话识别与推理准确率高。而缺点是知识图谱的构建是个耗时耗力的大工程,并且模型构建初期可能会存在数据的松散和覆盖率问题,导致匹配的覆盖率缺失等问题,而且比传统的QA Pair对知识维护上的成本高。
处理流程如下图:
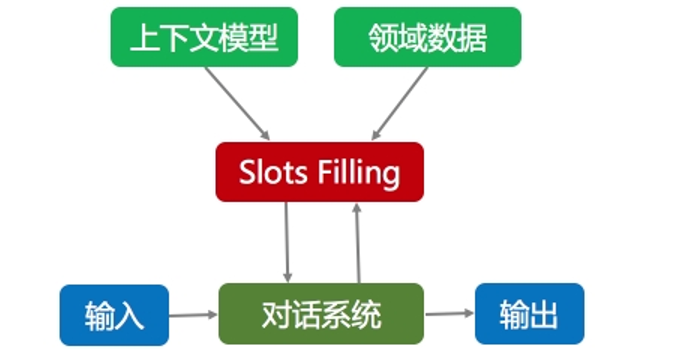
任务型场景一般的解决方式为意图决策+slot filling的匹配。应用到的相关技术有意图决策+slot filling。处理流程为首先按照任务领域进行本体知识的构建,例如机票的领域本体知识场景如下:
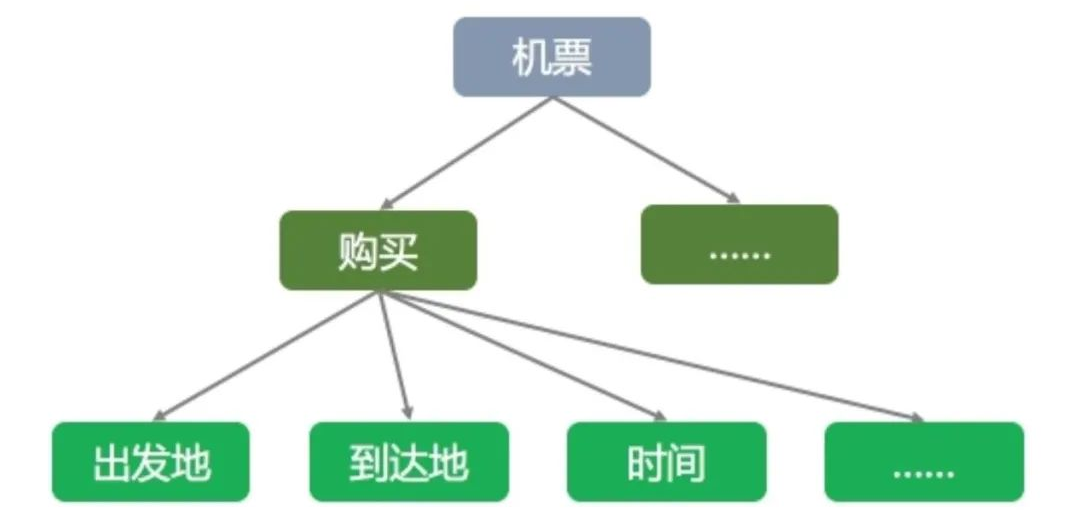
在问答匹配过程中结合上下文模型和领域数据模型不断在Query中进行slot属性的提取,并循环进行本体意图树的不断填充和修改,直到必选意图树填充完整后进行输出。
闲聊型场景一般解决方式为检索模型与Deep Learning结合。一般采用的技术为生成式模型+检索式模型方式。相应的处理流程是先通过传统的检索模型检索出候选集数据,然后通过Seq2Seq Model对候选集进行重排,重排序后超过制定的阈值就进行输出,不到阈值就通过Seq2Seq Model进行答案生成。

生成式模型的优点是可以通过深层语义方式进行答案生成,答案不受语料库规模限制,而缺点为模型的可解释性不强,且难以保证一致性和合理性回答,可控性较差。
检索模型的优点为答案在预设的语料库中,可控,匹配模型相对简单,可解释性强。相应的缺点为在一定程度上缺乏一些语义性,且有固定语料库的局限性。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

