深度强化学习“落地”高空,全自动环境监测或成现实
在电影《飞屋环游记》中,男主人公用一大堆气球将自己的小木屋带上天空,并通过增减气球、手动施力来改变气球的飞行方向,去实现他未曾实现的梦想......当然,电影世界具有一定的幻想色彩。但是,如今还真有这样一种巨型气球,它虽然不能带着小木屋飞上天空,却更加智能、用处更大——让全自动环境实时监测成为可能
在电影《飞屋环游记》中,男主人公用一大堆气球将自己的小木屋带上天空,并通过增减气球、手动施力来改变气球的飞行方向,去实现他未曾实现的梦想......
当然,电影世界具有一定的幻想色彩。但是,如今还真有这样一种巨型气球,它虽然不能带着小木屋飞上天空,却更加智能、用处更大——让全自动环境实时监测成为可能。

平流层气球(stratospheric balloon),又称高空气球,可以在大气平流层中自主飞行数月,具有低成本、高效益的特点,这使其成为通信、地球观测、收集气象数据和许多其他应用的宠儿。但是,如何实现高空气球的自主导航,一直是科学研究的一个难题。
近日,来自谷歌研究院(Google Research )和 Alphabet 旗下公司 Loon 的研究人员组成的科研团队,成功开发出的一种基于深度强化学习的高性能人工智能控制器,能让高空气球一连数周待在原地,并根据环境因素进行实时决策并实现自主导航。这一研究结果提高了全自动环境监测成为现实的可能性,代表深度强化学习向现实世界应用迈进了非常重要的一步。
该研究成果以“Autonomous navigation of stratospheric balloons using reinforcement learning”为题,于 12 月 3 日在线发表在顶级期刊 Nature 上。

(来源:Nature)
续航瓶颈,无法满足需求
高空气球中应用最广泛的当属“超压”气球,气球内填充氦气,常被用来在高层大气开展实验。这些气球遇到气流风时,往往会偏离航道,之后便只能返回地面驻点。而此次研究所采用的深度强化学习方法,可以训练人工智能系统进行实时决策。对于超压气球来说,这些决策包括采取哪些行动来保持其在空中的位置不变。
Loon 超压气球是谷歌于 2013 年成立的高空气球项目的成果之一,旨在将其作为通信中继平台,为还未接入互联网的偏远地区提供一种相对廉价的通信服务。传统上,Loon 的上下垂直飞行通过泵出固定体积的气囊来实现,而左右水平运动则由气球所处位置的风向所决定。因此,为了实现导航目的,飞行控制器必须通过上升和下降的方式,以找到并跟随对其有利的气流。
然而,这种简单的导航方式无法满足气球长时间(有时长达几个月)控制的目标。例如,传统“控位法”(Station-keeping)需要将气球固定在某个地面位置的正上方。为了完成这一任务,气球就必须不断地通过风场变化采取间接飞行路径,以保证位置不变。
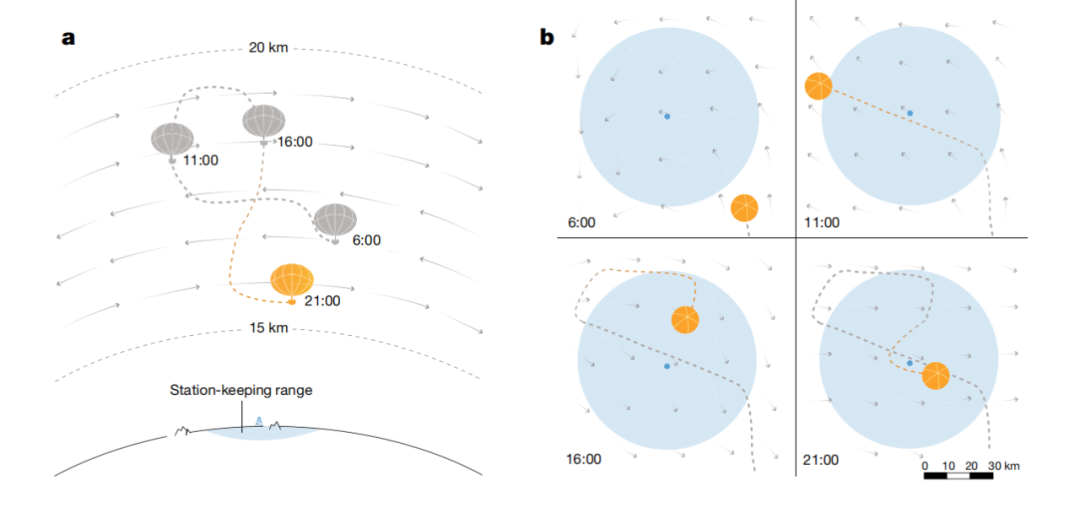
图|通过“控位法”保持超压气球位置。a) 超压气球在风场航行的原理图。气球通过不断移动来保持在离驻点较近的地方。其高度范围用上下虚线表示;b) 气球飞行路径平面示意图。蓝色区域表示驻点方圆 50 公里范围。阴影箭头代表风场。风场不断变化,要求气球实时规划路线。(来源:Nature)
不仅如此,气球还需要在昼夜交替中管理自身电力,由于气球下降时会使用存储在电池中的太阳能,一旦电力不够,气球也就无法再自主控制飞行。另外,一个好的飞行控制器必须能够权衡收集目标观测结果的性价比。因此,上述传统控制技术本身非智能化的性质就限制了其最终表现。
AI 赋能,带来质的飞跃
为提高超压气球的续航能力,论文作者之一、谷歌研究院科学家 Marc Bellemare 及其合作者训练了一种人工智能控制器,这种控制器能根据风的历史记录、预报、局部风向观测以及氦气损失和电池疲劳等其他因素,来实时决定气球是否需要移动。
首先,研究人员将 StationSeeker 算法用于这一人工智能控制器中。该算法为控制器提供了较好的“洞察力”,StationSeeker 会凭借风向与驻点形成的锐角来跟踪风向,只要气球处于驻点范围内,它就会主动去寻找移动较为缓慢的气流。
而后,研究人员对该控制器进行了模拟训练,在模拟试验中使用强化学习来训练飞行控制器。强化学习擅长自动产生控制策略,可以处理高维度的异质数据,并在需要长期观测时优化对应的控制策略。
为了获得最先进的控制器,研究人员结合了深度强化学习领域的最新进展,即强调在学习过程中使用深度神经网络。该控制器使用的神经网络分为 7 层、每层具有 600 个校正线性单元,而且试验证明,使用较小的网络或非分布算法会使得性能降低。

图|神经网络规模对 TWR50(气球位于驻点 50 公里以内范围时节省的时间)的影响(来源:Nature)
此次模拟试验包括对超压气球控制器在一个固定的位置上进行两天模拟,在此期间,控制器以 3 分钟的间隔接收输入数据和发出命令。因此,飞行控制器能够置身于昼夜循环场景中,这意味着气球必须从艰难的夜间条件中恢复工作,且最终产生的飞行路径则会接近真实场景。
最后,作者将该技术应用到分布于全球各地的 Loon 气球上,包括一项在太平洋上空进行的为期 39 天的受控实验(共 2884 飞行小时)。分析结果证明,受到 StationSeeker 控制的气球能够成功实现自主导航,一旦被吹偏航道,它们能以比传统控制器控制的气球更快的速度回到驻点。
其中,控制器最佳表现达到 55.1% TWR50。要知道,1% 的性能提升相当于节省 14.4 分钟的返回时间,因此,这一差异相当于每 24 小时内的返回时间平均减少 3.5 小时。
毫无疑问,此次研究成功将人工智能强化学习方法应用到了超压气球与环境的实时交互之中,拓宽了其在现实科学研究中的应用。
正如牛津大学物理系教授 Scott Osprey 所说:“Marc Bellemare 和同事的成果代表了强化学习在现实世界应用的一次巨大进步。”

相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

