如何评估自动驾驶注释数据的有效性?
本文来源:智车科技/ 导读 /数据是现代机器学习应用程序中最重要的组成部分,包括自动驾驶汽车的感知系统都是依靠数据进行训练的。目前汽车都配备了许多传感器,这些传感器收集信息并输入到汽车计算机,然后信息必须进行实时处理和注释,以便汽车了解行驶中道路前方的情况
本文来源:智车科技
/ 导读 /
数据是现代机器学习应用程序中最重要的组成部分,包括自动驾驶汽车的感知系统都是依靠数据进行训练的。目前汽车都配备了许多传感器,这些传感器收集信息并输入到汽车计算机,然后信息必须进行实时处理和注释,以便汽车了解行驶中道路前方的情况。但是,汽车计算机上的算法需要接受有关如何进行分类的训练,所以数据标注的准确性变得很重要。以下是Annotell公司在数据标注上的一些探索。
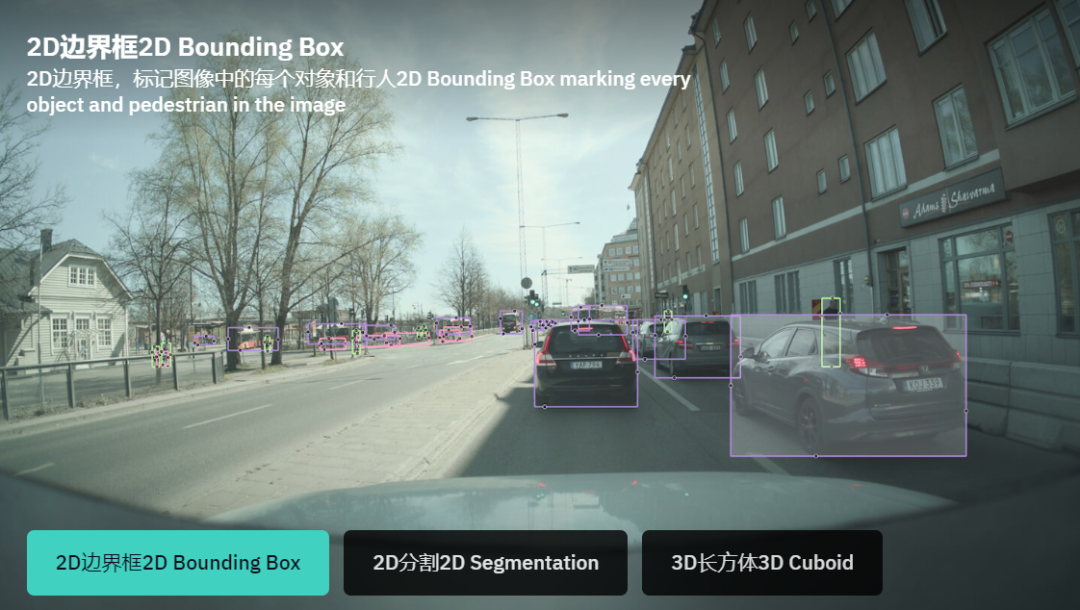

带注释的数据至关重要,它有两个目的:在汽车上的计算机上训练算法以解释收集的信息,并验证计算机确实已学会正确解释收集的信息。由于注释数据用于这两个关键目的,因此注释的质量至关重要。最终,低质量的注释可能会导致汽车误解道路上正在发生的事情。
注释数据的过程始终包括一些人为的决定,第一个挑战就是让人们同意对记录的数据进行正确的注释,而创建这样的注释准则有时并不像人们想象的那么容易。往往需要有效设计注释准则以提高质量方面具有丰富的经验。第二个挑战是在指南的指导下按比例执行注释。
如何判断数据集的有效性?
量化注释质量的一种方法是注释数据集的精度和召回率。考虑一下标注的类型,其中摄像机图像中的一个对象(如接近的车辆)由一个边界框标注。在对此类数据集的质量进行推理时,有两个重要的问题(i)感兴趣的对象是否已由边界框正确标注,以及(ii)边界框是否实际上包含感兴趣的对象。





上面示意图中出现了错误标注。而在完美注释的数据集中,以上两个错误均不存在。因此,定义质量的一种方法是计算这些错误在带注释的数据集中出现的程度。例如计算
实际表示对象的包围盒的比率。这称为精度。理想情况下,精度为1。用边界框正确注释的对象的比率。这就是所谓的召回。理想情况下,召回率为1。
但是,计算数据集的精度和召回率还需要对整个数据集中的每个帧进行人工批判性检查,这可能与注释过程本身一样昂贵!为了在计算精度和召回率时获得效率,因此Annotell团队依靠统计数据来推断精度和召回率。仅对所有注释的统计选择良好的子集进行人工批判性审查,并使用概率论得出有关整个数据集的结论。
更详细地讲,他们使用贝叶斯方法来计算后验分布,以提高精度并召回整个数据集,这取决于已经进行了严格审查的注释的子样本。它不仅提供了精确度和召回率的估计,而且还量化了这些估计中的不确定性。例如,我们可以计算所谓的95%可信度下限,这意味着可以确定95%的精度或召回率不低于此阈值。
Annotell公司提供了一种具有成本效益的工具,用于根据精度和召回级别以及对级别的确定性来衡量注释的质量。- End -
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

