如何使用python+pandas+tensorflow实现Covid新冠病毒检测
介绍Covid 是一种致命的疾病,会影响呼吸系统。检测一个人是否患有新冠病毒非常重要。在本博客中,我们将确定一个人是否患有新冠肺炎。输入让我们导入执行任务所需的工具。import pandas as
介绍
Covid 是一种致命的疾病,会影响呼吸系统。检测一个人是否患有新冠病毒非常重要。在本博客中,我们将确定一个人是否患有新冠肺炎。
输入
让我们导入执行任务所需的工具。
import pandas as pd
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import ResNet50
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, Flatten, GlobalAveragePooling2D
from tensorflow.keras.applications import ResNet50
import tensorflow as tf
import matplotlib.pyplot as plt
读取数据
train_data=pd.read_csv("Training_set_covid.csv")
print(train_data)

由于我们只有图像文件的名称和它们的标签,让我们添加一个由它们的文件路径组成的列。我们可以使用 ImageDataGenerator 加载图像。train_data["filepath"]="train/"+train_data["filename"]
print(train_data)
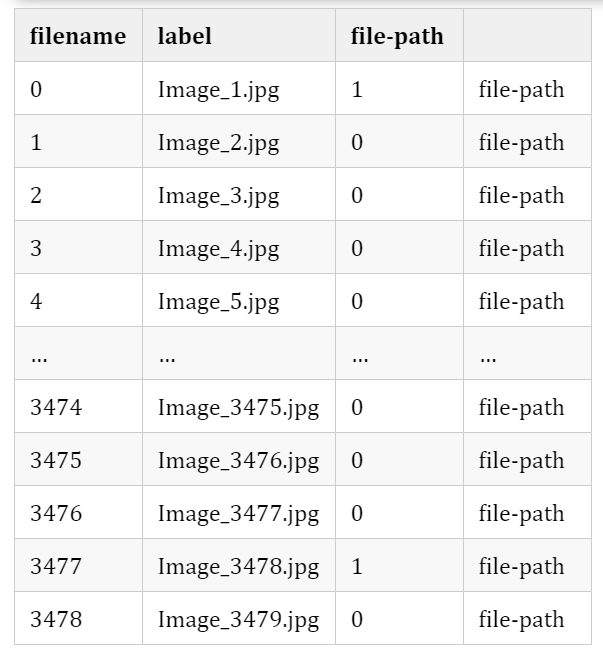
我已经用“file-path”替换了实际的文件路径。
数据增强由于我们的数据很少,我正在扩充我的数据并创建一个变量来存储训练和验证图像train_datagen=ImageDataGenerator(validation_split=0.2,zoom_range=0.2,rescale=1./255.,horizontal_flip=True)
在这里,我们将缩放范围设置为 0.2,并将图像重新缩放为 1/255 大小,并制作了训练图像的 20% 的验证集。train_data["label"]=train_data["label"].astype(str)
上面的代码会将我们的 int 标签转换为字符串类型。
加载图像
train_images=train_datagen.flow_from_dataframe(train_data,x_col="filepath",batch_size=8,target_size=(255,255),class_mode="binary",shuffle=True,subset='training',y_col="label")
valid_images=train_datagen.flow_from_dataframe(train_data,x_col="filepath",batch_size=8,target_size=(255,255),class_mode="binary",shuffle=True,subset='validation',y_col="label")
在这里,我们创建了 2 个数据流、1 个训练集和另一个验证集。为此我们设置了一些参数。参数如:Batch Size –> 8Target Size (Image size) –> (255,255)Shuffle –> TrueClass Mode –> Binary由于我们只有 2 个目标属性,因此我们设置了类模式 Binary。Resnet50 将 (255,255) 作为输入形状,因此我们的图像大小为 (255,255)。Shuffle 设置为 True,以足够好地对图像进行打乱,以便两个集合都有不同的图像。RESNET50让我们加载我们的 ResNet50 模型。但在进入代码路径之前,请了解 ResNet50 是什么以及它是如何工作的。base_model = ResNet50(input_shape=(225, 225,3), include_top=False, weights="imagenet")
for layer in base_model.layers:
layer.trainable = False
base_model = Sequential()
base_model.add(ResNet50(include_top=False, weights='imagenet', pooling='max'))
base_model.add(Dense(1, activation='sigmoid'))
base_model.compile(optimizer = tf.keras.optimizers.SGD(lr=0.0001), loss = 'binary_crossentropy', metrics = ['acc'])
base_model.summary()
让我们理解这个代码块。首先,我们将使用我们的输入形状和权重加载一个基本模型。在这里,我们使用了image-net权重。我们已经移除了顶部,因为我们将添加我们的输出层。然后,我们将所有基础模型层设置为不可训练,因为我们不想覆盖加载时导入的权重。现在,我们正在创建我们的基础模型,我们添加一个 50 个单元的 Dense 层来创建一个全连接层,该层连接到我们的输出密集层,具有 1 个单元和 Sigmoid 作为激活函数。然后我们用 SGD 优化器和一些微调和二进制交叉熵作为损失函数编译它。这是我们的模型的外观:Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resnet50 (Functional) (None, 2048) 23587712
_________________________________________________________________
dense_1 (Dense) (None, 1) 2049
=================================================================
Total params: 23,589,761
Trainable params: 23,536,641
Non-trainable params: 53,120
_________________________________________________________________
训练resnet_history = base_model.fit(train_images, validation_data = valid_images, steps_per_epoch =int(train_images.n/8), epochs = 20)
让我们用验证集训练我们的模型,训练图像并验证它们。有 20 个 epoch,每个 epoch 的步数设置为训练样本数/8 以进行平衡,批量大小为 8。Epoch 1/20
348/348 [==============================] - 162s 453ms/step - loss: 0.7703 - acc: 0.8588 - val_loss: 1.2608 - val_acc: 0.8791
Epoch 2/20
348/348 [==============================] - 84s 242ms/step - loss: 0.3550 - acc: 0.9198 - val_loss: 2.8488 - val_acc: 0.4518
Epoch 3/20
348/348 [==============================] - 84s 241ms/step - loss: 0.3501 - acc: 0.9229 - val_loss: 1.0196 - val_acc: 0.7007
Epoch 4/20
348/348 [==============================] - 84s 241ms/step - loss: 0.3151 - acc: 0.9207 - val_loss: 0.5498 - val_acc: 0.8633
Epoch 5/20
348/348 [==============================] - 85s 245ms/step - loss: 0.2376 - acc: 0.9281 - val_loss: 0.4247 - val_acc: 0.9094
Epoch 6/20
348/348 [==============================] - 86s 246ms/step - loss: 0.2273 - acc: 0.9248 - val_loss: 0.3911 - val_acc: 0.8978
Epoch 7/20
348/348 [==============================] - 86s 248ms/step - loss: 0.2166 - acc: 0.9319 - val_loss: 0.2936 - val_acc: 0.9295
Epoch 8/20
348/348 [==============================] - 87s 251ms/step - loss: 0.2016 - acc: 0.9389 - val_loss: 0.3025 - val_acc: 0.9281
Epoch 9/20
348/348 [==============================] - 87s 249ms/step - loss: 0.1557 - acc: 0.9516 - val_loss: 0.2762 - val_acc: 0.9281
Epoch 10/20
348/348 [==============================] - 85s 243ms/step - loss: 0.1802 - acc: 0.9418 - val_loss: 0.3382 - val_acc: 0.9353
Epoch 11/20
348/348 [==============================] - 84s 242ms/step - loss: 0.1430 - acc: 0.9586 - val_loss: 0.3222 - val_acc: 0.9324
Epoch 12/20
348/348 [==============================] - 85s 243ms/step - loss: 0.0977 - acc: 0.9695 - val_loss: 0.2110 - val_acc: 0.9410
Epoch 13/20
348/348 [==============================] - 85s 245ms/step - loss: 0.1227 - acc: 0.9572 - val_loss: 0.2738 - val_acc: 0.9281
Epoch 14/20
348/348 [==============================] - 86s 246ms/step - loss: 0.1396 - acc: 0.9558 - val_loss: 0.2508 - val_acc: 0.9439
Epoch 15/20
348/348 [==============================] - 86s 247ms/step - loss: 0.1173 - acc: 0.9578 - val_loss: 0.2025 - val_acc: 0.9381
Epoch 16/20
348/348 [==============================] - 86s 246ms/step - loss: 0.1038 - acc: 0.9604 - val_loss: 0.2658 - val_acc: 0.9439
Epoch 17/20
348/348 [==============================] - 86s 247ms/step - loss: 0.0881 - acc: 0.9707 - val_loss: 0.2997 - val_acc: 0.9309
Epoch 18/20
348/348 [==============================] - 87s 249ms/step - loss: 0.1036 - acc: 0.9627 - val_loss: 0.2527 - val_acc: 0.9367
Epoch 19/20
348/348 [==============================] - 87s 251ms/step - loss: 0.0848 - acc: 0.9736 - val_loss: 0.2461 - val_acc: 0.9439
Epoch 20/20
348/348 [==============================] - 87s 250ms/step - loss: 0.0742 - acc: 0.9736 - val_loss: 0.2483 - val_acc: 0.9439
我们有很好的结果。让我们看看它的图表。性能图精度图plt.plot(resnet_history.history["acc"],label="train")
plt.plot(resnet_history.history["val_acc"],label="val")
plt.title("Training Accuracy and Validation Accuracy")
plt.legend()
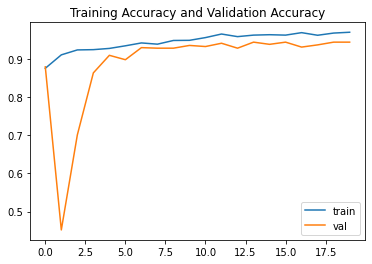
我们有很好的训练和验证准确性。损失plt.plot(resnet_history.history["loss"],label="train")
plt.plot(resnet_history.history["val_loss"],label="val")
plt.title("Training Loss and Validation Loss")
plt.legend()
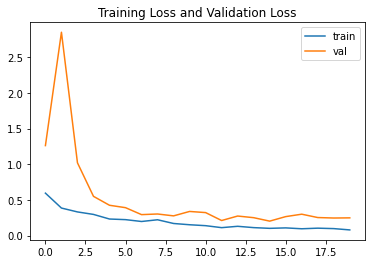
而且损失少。结论即使如此少的数据,ResNet50 也给出了令人满意的结果。

相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

