一文了解如何在Python中使用自动编码器
介绍自动编码器实际上是一种人工神经网络,用于对以无监督方式提供的输入数据进行解压缩和压缩。解压缩和压缩操作是有损的且特定于数据的。数据特定意味着自动编码器将只能实际压缩已经训练过的数据。例如,如果你用狗的图像训练一个自动编码器,那么它会给猫带来糟糕的表现

介绍自动编码器实际上是一种人工神经网络,用于对以无监督方式提供的输入数据进行解压缩和压缩。解压缩和压缩操作是有损的且特定于数据的。数据特定意味着自动编码器将只能实际压缩已经训练过的数据。例如,如果你用狗的图像训练一个自动编码器,那么它会给猫带来糟糕的表现。自动编码器计划学习表示对整个数据集的编码。这可能会导致训练网络降低维数。重构部分也是通过这个学习的。
有损操作意味着重建图像的质量通常不如原始图像清晰或高分辨率,并且对于具有更大损失的重建,差异更大,这被称为有损操作。下图显示了如何使用特定损失因子对图像进行编码和解码。
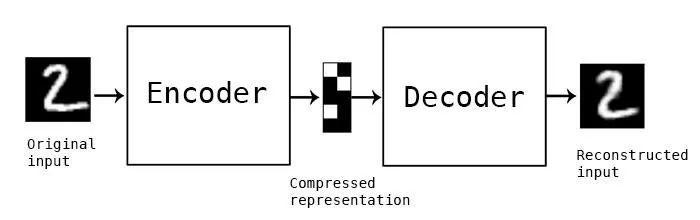
自动编码器是一种特殊类型的前馈神经网络,输入应该与输出相似。因此,我们需要一种编码方法、损失函数和解码方法。最终目标是以最小的损失完美地复制输入。输入将通过一层编码器,它实际上是一个完全连接的神经网络,它也构成代码解码器,因此像 ANN 一样使用相同的代码进行编码和解码。代码实现通过反向传播训练的 ANN 的工作方式与自动编码器相同。在本文中,我们将讨论 3 种类型的自动编码器,如下所示:简单的自动编码器深度 CNN 自动编码器去噪自动编码器对于自动编码器的实现部分,我们将使用流行的 MNIST 数字数据集。
1. 简单的自动编码器我们首先导入所有必要的库:import all the dependencies
from keras.layers import Dense,Conv2D,MaxPooling2D,UpSampling2D
from keras import Input, Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
然后我们将构建我们的模型,我们将提供决定输入将被压缩多少的维度数。维度越小,压缩越大。encoding_dim = 15
input_img = Input(shape=(784,))
# encoded representation of input
encoded = Dense(encoding_dim, activation='relu')(input_img)
# decoded representation of code
decoded = Dense(784, activation='sigmoid')(encoded)
# Model which take input image and shows decoded images
autoencoder = Model(input_img, decoded)
然后我们需要分别构建编码器模型和解码器模型,以便我们可以轻松区分输入和输出。# This model shows encoded images
encoder = Model(input_img, encoded)
# Creating a decoder model
encoded_input = Input(shape=(encoding_dim,))
# last layer of the autoencoder model
decoder_layer = autoencoder.layers[-1]
# decoder model
decoder = Model(encoded_input, decoder_layer(encoded_input))
然后我们需要用ADAM优化器和交叉熵损失函数拟合来编译模型。autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
然后你需要加载数据:(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
输出 :(60000, 784)
(10000, 784)
如果你想查看数据的实际情况,可以使用以下代码行:plt.imshow(x_train[0].reshape(28,28))
输出 :
然后你需要训练你的模型:autoencoder.fit(x_train, x_train,
epochs=15,
batch_size=256,
validation_data=(x_test, x_test))
输出 :Epoch 1/15
235/235 [==============================] - 14s 5ms/step - loss: 0.4200 - val_loss: 0.2263
Epoch 2/15
235/235 [==============================] - 1s 3ms/step - loss: 0.2129 - val_loss: 0.1830
Epoch 3/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1799 - val_loss: 0.1656
Epoch 4/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1632 - val_loss: 0.1537
Epoch 5/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1533 - val_loss: 0.1481
Epoch 6/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1488 - val_loss: 0.1447
Epoch 7/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1457 - val_loss: 0.1424
Epoch 8/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1434 - val_loss: 0.1405
Epoch 9/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1415 - val_loss: 0.1388
Epoch 10/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1398 - val_loss: 0.1374
Epoch 11/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1386 - val_loss: 0.1360
Epoch 12/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1373 - val_loss: 0.1350
Epoch 13/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1362 - val_loss: 0.1341
Epoch 14/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1355 - val_loss: 0.1334
Epoch 15/15
235/235 [==============================] - 1s 3ms/step - loss: 0.1348 - val_loss: 0.1328
训练后,你需要提供输入,你可以使用以下代码绘制结果:encoded_img = encoder.predict(x_test)
decoded_img = decoder.predict(encoded_img)
plt.figure(figsize=(20, 4))
for i in range(5):
# Display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(decoded_img[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
你可以分别清楚地看到编码和解码图像的输出,如下所示。
2. 深度 CNN 自动编码器由于这里的输入是图像,因此使用卷积神经网络或 CNN 确实更有意义。编码器将由一堆 Conv2D 和最大池化层组成,解码器将由一堆 Conv2D 和上采样层组成。代码 :model = Sequential()
# encoder network
model.add(Conv2D(30, 3, activation= 'relu', padding='same', input_shape = (28,28,1)))
model.add(MaxPooling2D(2, padding= 'same'))
model.add(Conv2D(15, 3, activation= 'relu', padding='same'))
model.add(MaxPooling2D(2, padding= 'same'))
#decoder network
model.add(Conv2D(15, 3, activation= 'relu', padding='same'))
model.add(UpSampling2D(2))
model.add(Conv2D(30, 3, activation= 'relu', padding='same'))
model.add(UpSampling2D(2))
model.add(Conv2D(1,3,activation='sigmoid', padding= 'same')) # output layer
model.compile(optimizer= 'adam', loss = 'binary_crossentropy')
model.summary()
输出 :Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 30) 300
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 30) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 15) 4065
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 15) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 7, 7, 15) 2040
_________________________________________________________________
up_sampling2d (UpSampling2D) (None, 14, 14, 15) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 14, 14, 30) 4080
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 28, 28, 30) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 28, 28, 1) 271
=================================================================
Total params: 10,756
Trainable params: 10,756
Non-trainable params: 0
_________________________________________________________________
现在你需要加载数据并训练模型(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
model.fit(x_train, x_train,
epochs=15,
batch_size=128,
validation_data=(x_test, x_test))
输出 :Epoch 1/15
469/469 [==============================] - 34s 8ms/step - loss: 0.2310 - val_loss: 0.0818
Epoch 2/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0811 - val_loss: 0.0764
Epoch 3/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0764 - val_loss: 0.0739
Epoch 4/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0743 - val_loss: 0.0725
Epoch 5/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0729 - val_loss: 0.0718
Epoch 6/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0722 - val_loss: 0.0709
Epoch 7/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0715 - val_loss: 0.0703
Epoch 8/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0709 - val_loss: 0.0698
Epoch 9/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0700 - val_loss: 0.0693
Epoch 10/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0698 - val_loss: 0.0689
Epoch 11/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0694 - val_loss: 0.0687
Epoch 12/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0691 - val_loss: 0.0684
Epoch 13/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0688 - val_loss: 0.0680
Epoch 14/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0685 - val_loss: 0.0680
Epoch 15/15
469/469 [==============================] - 3s 7ms/step - loss: 0.0683 - val_loss: 0.0676
现在你需要提供输入并绘制以下结果的输出pred = model.predict(x_test)
plt.figure(figsize=(20, 4))
for i in range(5):
# Display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(pred[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
输出 :
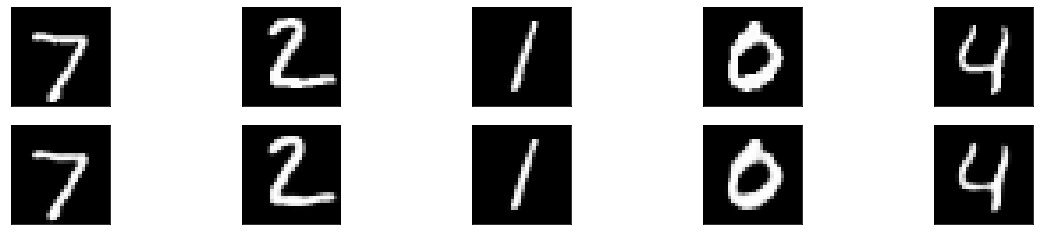
3. 去噪自动编码器现在我们将看到模型如何处理图像中的噪声。我们所说的噪声是指模糊的图像、改变图像的颜色,甚至是图像上的白色标记。noise_factor = 0.7
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
Here is how the noisy images look right now.
plt.figure(figsize=(20, 2))
for i in range(1, 5 + 1):
ax = plt.subplot(1, 5, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
输出 :

现在图像几乎无法识别,为了增加自动编码器的范围,我们将修改定义模型的层以增加过滤器,使模型性能更好,然后拟合模型。model = Sequential()
# encoder network
model.add(Conv2D(35, 3, activation= 'relu', padding='same', input_shape = (28,28,1)))
model.add(MaxPooling2D(2, padding= 'same'))
model.add(Conv2D(25, 3, activation= 'relu', padding='same'))
model.add(MaxPooling2D(2, padding= 'same'))
#decoder network
model.add(Conv2D(25, 3, activation= 'relu', padding='same'))
model.add(UpSampling2D(2))
model.add(Conv2D(35, 3, activation= 'relu', padding='same'))
model.add(UpSampling2D(2))
model.add(Conv2D(1,3,activation='sigmoid', padding= 'same')) # output layer
model.compile(optimizer= 'adam', loss = 'binary_crossentropy')
model.fit(x_train_noisy, x_train,
epochs=15,
batch_size=128,
validation_data=(x_test_noisy, x_test))
输出 :Epoch 1/15
469/469 [==============================] - 5s 9ms/step - loss: 0.2643 - val_loss: 0.1456
Epoch 2/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1440 - val_loss: 0.1378
Epoch 3/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1373 - val_loss: 0.1329
Epoch 4/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1336 - val_loss: 0.1305
Epoch 5/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1313 - val_loss: 0.1283
Epoch 6/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1294 - val_loss: 0.1268
Epoch 7/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1278 - val_loss: 0.1257
Epoch 8/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1267 - val_loss: 0.1251
Epoch 9/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1259 - val_loss: 0.1244
Epoch 10/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1251 - val_loss: 0.1234
Epoch 11/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1241 - val_loss: 0.1234
Epoch 12/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1239 - val_loss: 0.1222
Epoch 13/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1232 - val_loss: 0.1223
Epoch 14/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1226 - val_loss: 0.1215
Epoch 15/15
469/469 [==============================] - 4s 8ms/step - loss: 0.1221 - val_loss: 0.1211
训练结束后,我们将提供输入并编写绘图函数以查看最终结果。pred = model.predict(x_test_noisy)
plt.figure(figsize=(20, 4))
for i in range(5):
# Display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(pred[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
输出 :

尾注我们已经了解了自动编码器工作的结构,并使用了 3 种类型的自动编码器。自动编码器有多种用途,如降维图像压缩、电影和歌曲推荐系统等。模型的性能可以通过训练更多的 epoch 或增加我们网络的维度来提高。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

