使用 PoseNet 和实时深度学习项目进行姿势检测
介绍深度学习是机器学习和人工智能的一个子集,它模仿人类获取某些类型知识的方式。它本质上是一个具有三层或更多层的神经网络。深度学习有助于解决许多人工智能应用程序,这些应用程序有助于提高自动化程度,在无需人工干预的情况下执行分析和物理任务,从而创建智能的应用程序和技术
介绍深度学习是机器学习和人工智能的一个子集,它模仿人类获取某些类型知识的方式。它本质上是一个具有三层或更多层的神经网络。深度学习有助于解决许多人工智能应用程序,这些应用程序有助于提高自动化程度,在无需人工干预的情况下执行分析和物理任务,从而创建智能的应用程序和技术。其中一种应用是人体姿势检测,其中使用了深度学习。
目录
· 什么是Posenet ?
· PoseNet 是如何工作的?
· 实时姿势检测的应用
· 使用 PoseNet 实现姿势检测
先决条件
从头开始编写完整的项目
在 GitHub 上部署
· 尾注
什么是Posenet ?
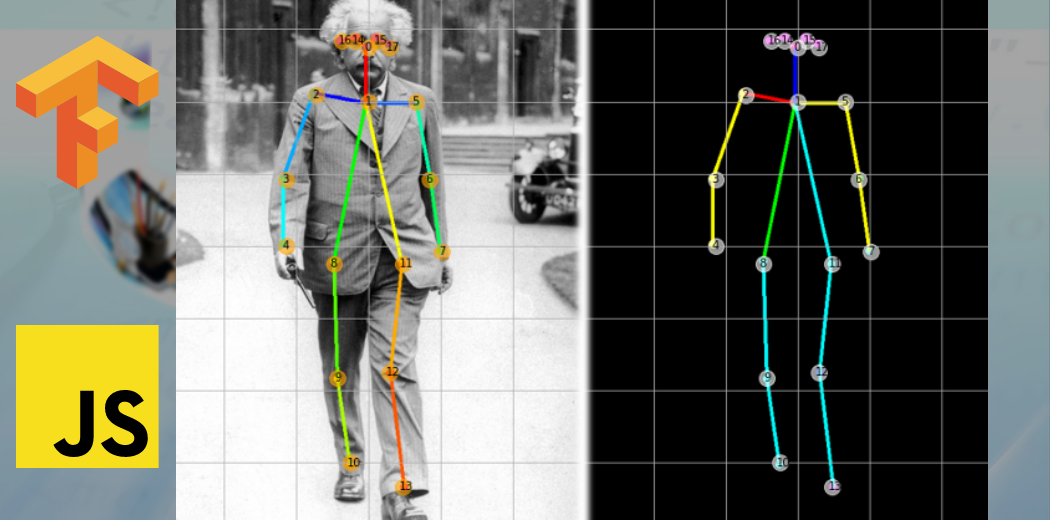
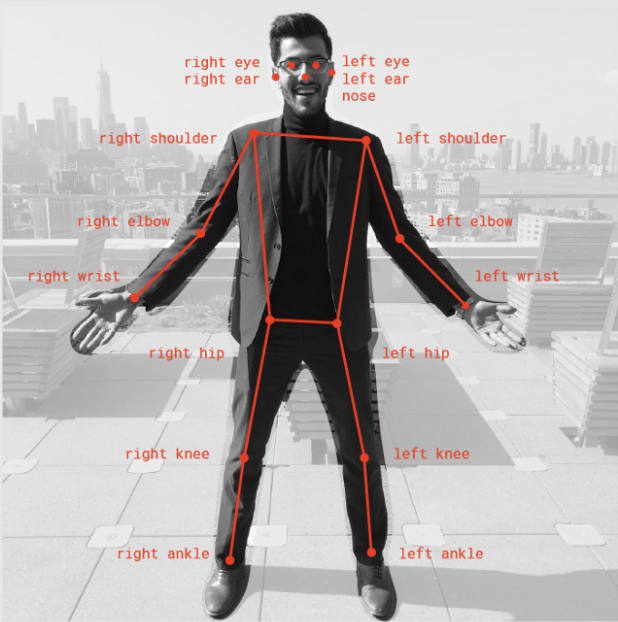
Posenet 是一种实时姿势检测技术,你可以使用它检测图像或视频中的人类姿势。它在两种情况下都可以作为单模式(单个人体姿势检测)和多姿势检测(多个人体姿势检测)工作。简单来说,Posenet 是一个深度学习 TensorFlow 模型,它允许你通过检测肘部、臀部、手腕、膝盖、脚踝等身体部位来估计人体姿势,并通过连接这些点形成姿势的骨架结构。
PoseNet 是如何工作的?
PoseNet 接受过 MobileNet 架构训练。MobileNet 是谷歌开发的卷积神经网络,在 ImageNet 数据集上训练,主要用于类别中的图像分类和目标估计。它是一个轻量级模型,它使用深度可分离卷积来加深网络并减少参数、计算成本并提高准确性。你可以在 google 上找到大量与 MobileNet 相关的文章。
预训练模型在浏览器中运行,这就是 posenet 与其他依赖API 的库的区别。因此,在笔记本电脑/台式机中配置有限的任何人都可以轻松使用此类模型并构建良好的项目。
Posenet 为我们提供了总共 17 个我们可以使用的关键点,从眼睛到耳朵,再到膝盖和脚踝。
如果我们提供给 Posenet 的图像不清晰,则posenet 会以JSON 响应的形式显示它对检测特定姿势的置信度分数。
PoseNet 现实世界中的应用
1. 在 Snapchat 过滤器中使用,你可以在其中看到舌头、侧面、快照、虚拟人脸等。
2. 像 cult 一样的健身应用程序,用于检测你的运动姿势。
3. 一个非常受欢迎的 Instagram Reels 使用姿势检测为你的脸和周围提供不同的特征。
4. 虚拟游戏来分析球员的投篮。
使用 PoseNet 实现姿势检测
现在我们有了对posenet的理论知识以及为什么使用它。让我们直接进入编码环境并实现姿势检测项目。
我们将如何实施项目
我们不会遵循 Python 的方式来实现这个项目,而是会使用 javascript,因为我们必须在浏览器中完成所有这些工作,而在浏览器中实现 Python 几乎是不可能的。你可以在服务器上运行 Python。Tensorflow 有一个流行的库名称tensorflow.js,它提供了在客户端系统上运行模型的功能。如果你还没有阅读或了解使用 javascript 进行机器学习,那么无需担心,代码量很少。
让我们开始吧
你可以使用任何 IDE 来实现项目,例如 Visual Studio 代码、sublime 文本等。
1) Boiler 模板
创建一个新文件夹并创建一个 HTML 文件,它将作为我们的网站供用户使用。在这里我们将导入我们将使用的 javascript 文件、机器学习和深度学习库。
<html>
<head>
<title>PoseNet Detection</title>
</head>
<body>
<h1 style="text-align:center">Posture Detection using PoseNet</h1>
</body>
</html>
使用 PoseNet 进行姿势检测
2) p5.js
它是一个用于创意编码的 javascript 库。有一种称为Processing 的软件,P5.js 正是基于该软件。
Processing 是用 Java 制作的,这有助于在桌面应用程序中进行创造性编码,但在那之后,当网站需要同样的东西时,就实现了 P5.js。
创意编码意味着它可以帮助你通过调用内置函数以创造性的方式(彩色或动画)在浏览器上绘制各种形状和图形,如线条、矩形、正方形、圆形、点等,并提供高度和宽度你想要的形状。
创建一个 javascript 文件,在这里我们将尝试学习 P5.JS,以及我们为什么使用这个库。在 javascript 文件中写入任何内容之前,首先导入 P5.js,在 HTML 文件中添加指向创建的 javascript 文件的链接。
<html>
<head>
<title>PoseNet Detection</title>
<script src="https://unpkg.com/ml5@latest/dist/ml5.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/p5@1.4.0/lib/p5.js"></script>
<script src="sketch.js"></script> <!--js file-->
</head>
<body>
<h1 style="text-align:center">Posture Detection using PoseNet</h1>
</body>
</html>
你可以在 P5.js 中实现两件事。在javascript文件中编写以下代码。
a) setup :在这个函数中,你编写一个与你的界面中需要的基本配置相关的代码。你创建的一件事是画布并在此处指定其大小。你实现的所有东西只会出现在这个画布上。它的工作是设置所有的东西。
function setup() { // this function runs only once while running
createCanvas(800, 500);
}
b) 绘图:第二个功能是在你绘制所有你想要的东西的地方绘图,比如形状、放置图像、播放视频。所有的实现代码都放在这个函数中。将其理解为编译语言中的主要功能。它的工作是在屏幕上显示东西。让我们尝试绘制一些形状,并亲身体验 P5.Js 库。最好的是每个图形都有一个内置函数,你只需要调用并传递一些坐标即可绘制形状。为画布提供背景颜色调用背景函数并传递颜色代码。
*i) Point :*使用 point 函数绘制一个简单的点并传递 x 和 y 坐标
*ii)*line:线连接两点,只需调用直线函数,并传递2个点的坐标。
iii) rectangle :调用 rect 函数并传递高度和宽度。如果高度和宽度相同,那么它将是正方形。
用于创造力的一些其他功能是。
*i)stroke——*它定义了形状的外边界线
*ii)stroke-weight –*它定义了外线的宽度。
iii) fill ——你想在形状中填充的颜色
下面是一个代码片段,作为我们学习的每个函数的示例。尝试运行此代码,并通过像在实时服务器上一样运行 HTML 文件来观察浏览器中的变化和数字。

P5.js的一个重要特性是setup函数只运行一次设置,而draw函数代码无限循环运行,直到界面打开。你可以通过使用控制台日志命令打印任何内容来检查这一点。使用 P5js,你可以加载图像、捕获图像、视频等。

在draw函数和上面的new函数中运行上面注释的这段代码,观察浏览器的变化,体验P5.js库的神奇。
3) ML5.js
与他人共享代码应用程序的最佳方式是网络。只有共享URL,你才能使用系统上的其他应用程序。所以,ML5.js构建了一个围绕tensorflow.js的包装器,并通过使用一些函数使任务变得简单,你将间接地通过ML5.js处理tensorflow.js。你可以在Ml5.js的官方文档中读到同样的内容因此,它是由各种深度学习模型组成的主要库,你可以在这些模型上构建项目。在这个项目中,我们使用了这个库中也存在的 PoseNet 模型。让我们导入库并使用它。在 HTML 文件中粘贴以下脚本代码以加载库。现在让我们设置图像捕获并加载 PoseNet 模型。capture 变量是一个全局变量,我们将创建的所有变量都具有全局作用域。
let capture;

当我们加载并运行代码时,Posenet 将检测 17 个身体点(5 个面部点,12 个身体点)以及在图像中检测到该点的像素的信息。
如果你打印这些姿势,那么它将返回一个数组(python 列表),该数组由一个字典组成,其中有 2 个键作为我们评估过的姿势和骨架。
· 姿势 - 这又是一个字典,由各种键和一系列值组成,如关键点、左眼、左耳、鼻子等。
· 骨架 - 在骨架中,每个字典由两个子字典组成,分别为 0 和 1,它们具有置信度分数、部件名称和位置坐标。所以我们可以用它来制作一条线并构建一个骨架结构。
现在,如果你想在姿势前显示任何单个点,则可以通过在姿势中使用这些单独的点来实现。
我们将如何显示所有点并将它们连接为骨架?
我们有一个关键点名称字典,其中包含每个点的 X 和 y 坐标。所以我们可以在其中遍历关键点字典和访问位置字典,并在其中使用 x 和 y 坐标。现在要画线,我们可以使用第二个字典作为骨架,它由坐标的所有点信息组成,以连接两个身体部位。
function draw() {
// images and video(webcam)
image(capture, 0, 0);
fill(255, 0, 0);
if(singlePose) { // if someone is captured then only
// Capture all estimated points and draw a circle of 20 radius
for(let i=0; i<singlePose.keypoints.length; i++) {
ellipse(singlePose.keypoints[i].position.x, singlePose.keypoints[i].position.y, 20);
}
stroke(255, 255, 255);
strokeWeight(5);
// construct skeleton structure by joining 2 parts with line
for(let j=0; j<skeleton.length; j++) {
line(skeleton[j][0].position.x, skeleton[j][0].position.y, skeleton[j][1].position.x, skeleton[j][1].position.y);
}
}
}
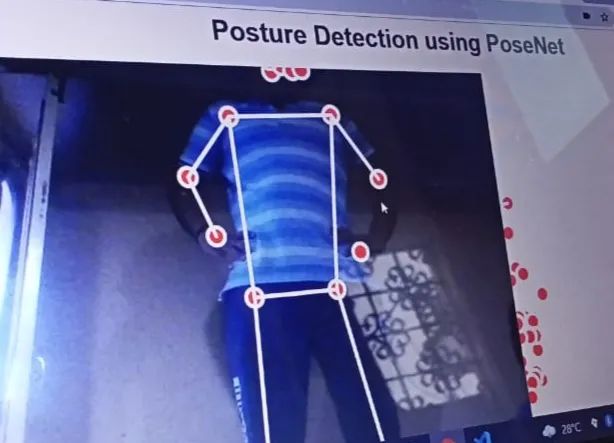
在光线充足的情况下,它有时无法在模糊或黑暗的背景下准确捕捉。
如何强加图像?
现在我们将学习如何将图像强加到脸部或你在不同过滤器中看到的任何其他位置。看起来有点模糊和有趣,但这个应用程序正在作为许多社交媒体的助推器。只需在 setup 函数中加载图像,并使用 image 函数调整图像作为坐标,你希望在绘制函数中在循环骨架结束后显示该图像。假设我们正在显示规格和雪茄图像。
specs = loadImage('images/spects.png');
smoke = loadImage('images/cigar.png');
// Apply specs and cigar
image(specs, singlePose.nose.x-40, singlePose.nose.y-70, 125, 125);
image(smoke, singlePose.nose.x-35, singlePose.nose.y+28, 50, 50);
所有的图像都保存在一个名为图像的单独文件夹中,我们使用加载图像功能加载每个图像。规格将在鼻子上方,雪茄在鼻子下方。完整的代码链接如下,大家可以参考。
部署项目
由于该项目在浏览器上,因此你可以简单地将其部署在 Github 上并使其可供其他人使用。只需将所有文件和图像上传到 Github 上的新存储库,就像它们在本地系统中一样。上传后访问存储库的设置并访问 Github 页面。将 none 更改为 main 分支,然后单击保存。它将为你提供一个项目的 URL,该项目将在一段时间后生效,你可以与他人共享。
尾注
欢呼!我们使用预训练的 PoseNet 模型创建了一个完整的端到端姿势检测项目。我希望能够轻松掌握所有概念,因为我可以理解,如果你第一次看到使用 JavaScript 进行机器学习会感觉有点困难。但是相信我,这是一件简单的事情,并再次阅读文章并使用不同的配置,不同的设计自己尝试。我们已经进行了单人姿势检测,我鼓励你进行多人姿势检测。你可以尝试添加不同的选项,调整适用于所有相机的点。你可以在这个项目上继续推进很多事情。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

