使用深度学习构建脑肿瘤分类器
介绍深度学习常常出现在我们的日常生活中。在现代社会中,我们的生活方式出现了各种变化,例如自动驾驶汽车、谷歌助理、Netflix 推荐、垃圾邮件检测等等。同样,深度学习在医疗保健领域也得到了发展,我们使用深度学习模型通过核磁共振扫描检测脑肿瘤,使用肺部 X 射线检测 covid 等
介绍
深度学习常常出现在我们的日常生活中。在现代社会中,我们的生活方式出现了各种变化,例如自动驾驶汽车、谷歌助理、Netflix 推荐、垃圾邮件检测等等。同样,深度学习在医疗保健领域也得到了发展,我们使用深度学习模型通过核磁共振扫描检测脑肿瘤,使用肺部 X 射线检测 covid 等。脑肿瘤是一种严重的疾病,每年记录的病例超过 100 万例。
如果一个人患有脑肿瘤,则使用核磁共振成像 (MRI) 扫描。脑瘤可以属于任何类别,对这数百万人进行核磁共振检查以确定一个人是否患有这种疾病,如果是,他的类别是什么,这可能是一项艰巨的任务。这就是深度学习模型发挥重要作用的地方,它可以通过使用神经网络提供患者大脑的 MRI 图像来判断患者是否患有脑肿瘤。
我们将使用 CNN(卷积神经网络)构建脑肿瘤分类器,该分类器因其高精度而广泛用于图像分类领域。我们将使用的编程语言是python。
数据集概述
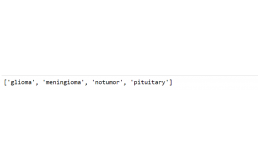
我们正在使用一个脑肿瘤图像分类器数据集,该数据集有 7022 张人脑 MRI 图像,分为训练集和测试集,它们分为 4 类:
胶质瘤(Glioma)
脑膜瘤 (Meningioma )
无肿瘤 (No tumor)
垂体(Pituitary)
这些图像的像素大小为 512 x 512,并且每个图像都有固定的标签。
让我们导入有助于我们对这些图像进行分类的基本库。
导入库
我们将首先探索数据集并使用图像数据生成器 ImageDataGenerator 对其进行预处理,我们将导入 Tensorflow。在 TensorFlow 中,我们将使用 Keras 库。
import pandas as pd
import numpy as np
import tensorflow
from tensorflow import keras
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator as Imgen
图像增强
当我们使用任何图像数据集来训练我们的模型时,有时它可能无法为我们提供准确的结果,因为其中的图像可能需要一些预处理,例如缩放、增加亮度、更改灰度值等。
就像二进制数据需要一些数据清理和预处理一样,图像数据集也需要数据预处理。为此,本文使用了 Keras 库中的图像数据生成器。
它通过实时数据增强生成批量张量图像数据,例如调整所有图像的大小,并调整它们的高度和宽度,从而使输入的图像数据是统一的。
Args rescale:(重新缩放因子)。默认为 None。否则,我们可以将数据乘以所提供的值。
Shear_range:剪切强度(以度为单位的逆时针方向的剪切角)
Zoom_range:随机缩放的范围
Height_shift_range : 总高度的分数, if < 1
Width_shift_range : 总宽度的分数, if < 1
Fill_mode:默认为“nearest”。根据给定的模式填充输入边界之外的点。
Validation_split: 保留用于验证的图像的一部分(在 0 和 1 之间)。
#Augmenting the training dataset
traingen = Imgen(
rescale=1./255,
shear_range= 0.2,
zoom_range = 0.3,
width_shift_range = 0.2,
height_shift_range =0.2,
fill_mode = "nearest",
validation_split=0.15)
#Augmenting the testing dataset
testgen = Imgen(# rescale the images to 1./255
rescale = 1./255
)
现在,我们将获取目录的路径并生成批量增强数据。
trainds = traingen.flow_from_directory("Training/",
target_size = (130,130),
seed=123,
batch_size = 16,
subset="training"
)
valds = traingen.flow_from_directory("Training",
target_size = (130,130),
seed=123,
batch_size = 16,
subset="validation"
)
testds = testgen.flow_from_directory("Validation",
target_size = (130,130),
seed=123,
batch_size = 16,
shuffle=False)
这里使用的一些参数是,
Target_size:整数元组(height, width),默认为 (512, 512)。将调整所有图像的尺寸。
nearest:用于打乱和转换的可选随机种子。
Batch_size:数据批次的大小(默认值:32)。**Subset **:数据子集(“training” or “validation”)。
Shuffle:是否打乱数据(默认值:True)如果设置为 False,则按字母数字顺序对数据进行排序。
这一步将我们预处理的图像数据集分为训练集、验证集和测试集,其中我们的图像数据集分成训练集和验证集的比例为 80% - 20%,其中验证数据集包含 20% 的训练数据集。并且在测试集方面,数据集本身分为训练集和测试集文件夹,因此无需明确划分测试集。
验证数据集在构建深度学习模型以证实我们在训练期间的模型性能时非常重要。这个过程对于稍后根据其性能调整我们的模型很重要。
识别我们数据集的类别:
c = trainds.class_indices
classes = list(c.keys())
classes

我们对数据进行了扩充,分为训练集、验证集和测试集,并且我们已经确定了图像数据集的四个类别。
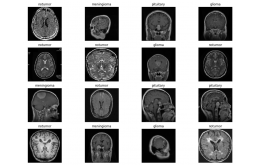
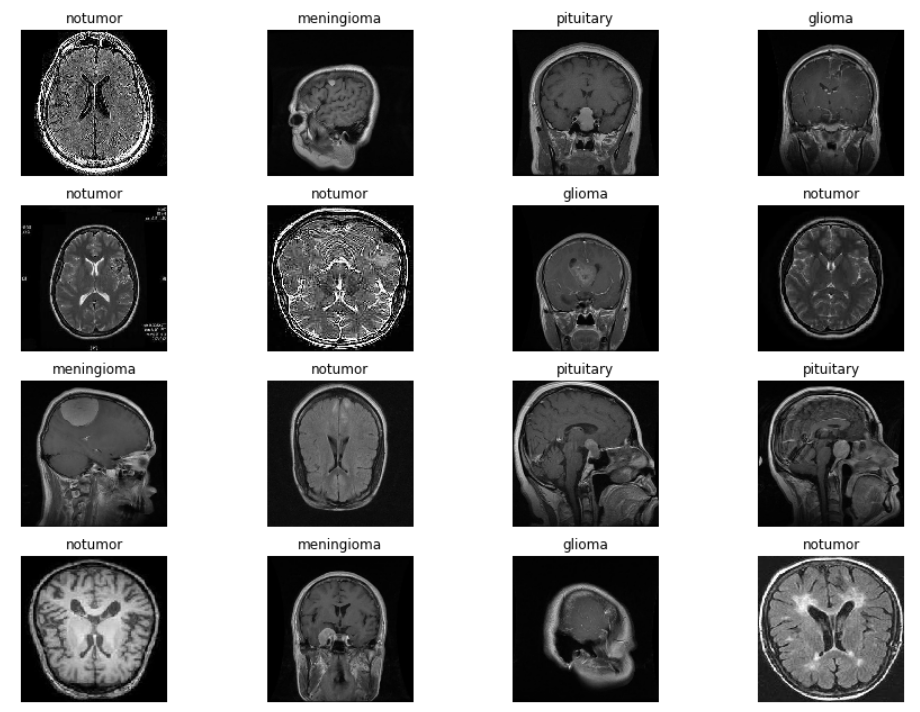
现在让我们可视化我们的图像,这样我们就可以看看图像增强是如何执行的,而且,我们还将使用我们的类来识别我们正在寻找的脑肿瘤类型。
x,y = next(trainds) #function returns the next item in an iterator.
def plotImages(x,y):
plt.figure(figsize=[15,11]) #size of the plot
for i in range(16): #16 images
plt.subplot(4,4,i+1) #4 by 4 plot
plt.imshow(x[i])#Imshow() is a function of matplotlib displays the image
plt.title(classes[np.argmax(y[i])]) # Class of the image will be it's title
plt.axis("off")
plt.show()
现在我们将通过调用我们定义的函数来绘制我们的图像。
#Call the plotImages function
plotImages(x,y)
它会给我们这样的输出,
现在,该项目最重要的一步是开始使用卷积神经网络创建深度学习模型。
构建深度学习模型
神经网络因其准确性和无需明确编程即可检测数据的能力而被广泛用于几乎所有深度学习项目。根据项目需要使用不同种类的神经网络;例如,我们将使用人工神经网络 (ANN) 处理整数数据。
CNN 广泛用于对图像数据进行分类。CNN 的主要优点是它可以自动检测任何图像中的重要特征,而无需人工监督。这可能就是为什么 CNN 会成为计算机视觉和图像分类问题的完美解决方案。因此,特征提取对于 CNN 至关重要。
执行的特征提取包括三个基本操作:
针对特定特征过滤图像(卷积)
在过滤后的图像中检测该特征 (ReLU)
压缩图像以增强特征(最大池化)
让我们讨论一下CNN的每一个操作。
1. 卷积
卷积层执行过滤步骤。ConvNet 在训练期间学习的权重主要包含在其卷积层中。这些层称为核。核通过扫描图像并产生加权像素和来工作。
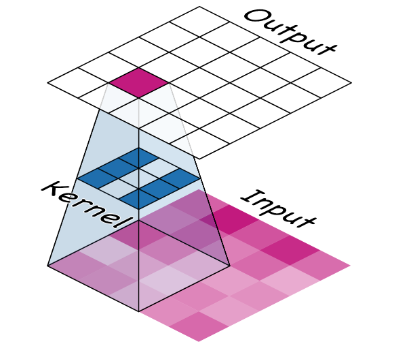
图片来源:

不同类型的核为每个图像产生不同的特征。
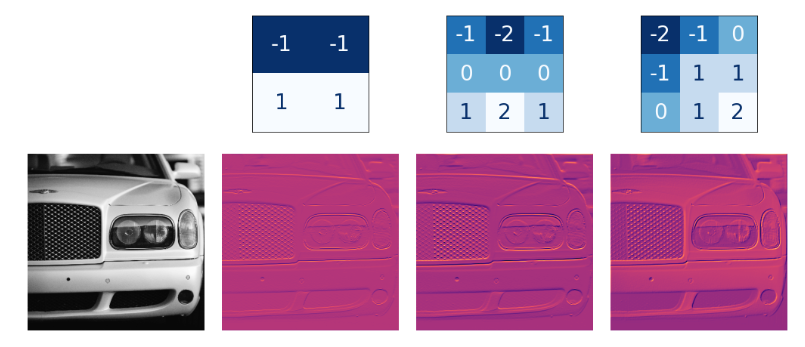
图片来源:

2. 激活函数
这是神经网络中最重要的部分。激活函数根据它接收到的输入来决定是否触发一个特定的神经元,并将其传递给下一层。整流线性单元或 ReLU 是最常用的激活函数,因为它实现简单,并且克服了由其他激活函数(如 Sigmoid)引起的许多其他障碍。
我们还在模型中使用了 Softmax 激活函数,因为它用于对多类数据集进行分类。
3. 最大池化
Max Pooling 是一个卷积过程,其中核提取其覆盖区域的最大值。像最大池化一样,我们可以使用平均池化。函数映射中的 ReLU (Detect) 函数最终会出现很多“死区”,我们想压缩函数映射以仅保留函数本身最有用的部分。
要构建模型,让我们首先导入创建模型所需的必要库。
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout, Conv2D, MaxPooling2D, Activation
from keras.metrics import categorical_crossentropy
from keras.optimizers import Adam
下面是CNN模型。
cnn = Sequential([
# first Layer
Conv2D(filters=16, kernel_size=(3, 3), padding = 'same', activation='relu', input_shape=(130, 130, 3)),
MaxPooling2D((2, 2)),
# second layer
Conv2D(filters=32, kernel_size=(3, 3), padding = 'same', activation='relu'),
MaxPooling2D((2, 2)),
Dropout(0.20),
Flatten(),
Dense(64, activation='relu'),
Dense(32, activation='relu'),
Dense(10, activation='relu'),
Dense(4, activation='softmax')
])
这里使用的一些基本术语是,
Dropout 层:该层用于任何隐藏层,但不能用于输出层。该层主要用于防止我们模型的过度拟合。
Flatten 层:该层主要用于将多维输入转换为一维输出。
Dense 层:每个神经网络相互连接的简单神经元层。
由于我们的输出将包括神经胶质瘤、脑膜瘤、无肿瘤和垂体这四类,因此我们为输出层提供了四个神经元。
以下是创建模型的架构。
cnn.summary()
Model: "sequential"
______________________________________
Layer (type) Output ShapeParam #
======================================
conv2d (Conv2D) (None, 130, 130, 16) 448
max_pooling2d (MaxPooling2D (None, 65, 65, 16) 0
)
conv2d_1 (Conv2D) (None, 65, 65, 32) 4640
max_pooling2d_1 (MaxPooling (None, 32, 32, 32) 0
2D)
dropout (Dropout) (None, 32, 32, 32) 0
flatten (Flatten) (None, 32768) 0
dense (Dense) (None, 64) 2097216
dense_1 (Dense) (None, 32) 2080
dense_2 (Dense) (None, 10) 330
dense_3 (Dense) (None, 4) 44
======================================
Total params: 2,104,758
Trainable params: 2,104,758
Non-trainable params: 0
______________________________________
编译借助以下参数创建的模型,
cnn.compile(loss="categorical_crossentropy",
optimizer = "Adam",metrics=["accuracy"])
我们这里选择的损失函数是分类交叉熵。在开发深度学习模型以测量预测输出和实际输出之间的差异时,损失函数是必不可少的,这样神经网络就可以调整其权重以提高其准确性。当图像要在许多类别中分类时,使用分类交叉熵。
神经网络中的优化器主要用于调整神经网络的权重,提高模型的学习速度以减少损失。在这里,Adam 是最常用的优化器。
让我们将数据拟合到我们创建的 CNN 模型中。
history = cnn.fit(trainds,validation_data=valds,epochs=10, batch_size=16, verbose=1)
Epoch 1/10
304/304 [==============================] - 126s 413ms/step - loss: 0.5149 - accuracy: 0.7813 - val_loss: 0.6445 - val_accuracy: 0.7801
Epoch 2/10
304/304 [==============================] - 122s 400ms/step - loss: 0.3672 - accuracy: 0.8526 - val_loss: 0.6240 - val_accuracy: 0.7591
Epoch 3/10
304/304 [==============================] - 122s 401ms/step - loss: 0.2541 - accuracy: 0.9004 - val_loss: 0.6677 - val_accuracy: 0.7953
Epoch 4/10
304/304 [==============================] - 122s 399ms/step - loss: 0.1783 - accuracy: 0.9343 - val_loss: 0.6279 - val_accuracy: 0.8187
Epoch 5/10
304/304 [==============================] - 122s 400ms/step - loss: 0.1309 - accuracy: 0.9502 - val_loss: 0.6373 - val_accuracy: 0.8292
Epoch 6/10
304/304 [==============================] - 121s 399ms/step - loss: 0.1069 - accuracy: 0.9613 - val_loss: 0.7103 - val_accuracy: 0.8444
Epoch 7/10
304/304 [==============================] - 121s 399ms/step - loss: 0.0768 - accuracy: 0.9712 - val_loss: 0.6353 - val_accuracy: 0.8409
Epoch 8/10
304/304 [==============================] - 122s 400ms/step - loss: 0.0540 - accuracy: 0.9827 - val_loss: 0.6694 - val_accuracy: 0.8456
Epoch 9/10
304/304 [==============================] - 121s 399ms/step - loss: 0.0530 - accuracy: 0.9813 - val_loss: 0.7373 - val_accuracy: 0.8374
Epoch 10/10
304/304 [==============================] - 122s 399ms/step - loss: 0.0304 - accuracy: 0.9872 - val_loss: 0.7529 - val_accuracy: 0.8655
正如我们所见,我们提出的 CNN 模型在训练数据上的准确率达到了 98%!在验证数据上,我们获得了超过 86% 的准确率。现在让我们在测试数据集上评估这个模型。
cnn.evaluate(testds)
82/82 [==============================] - 9s 113ms/step - loss: 0.2257 - accuracy: 0.9458
正如我们所看到的,我们提出的 CNN 模型在测试数据上表现得非常好。在拟合模型时,我们在上面的代码中将训练数据声明为“trainds”,并保持 epochs 为 10,这意味着我们的模型使用训练数据训练神经网络十次,并将 Verbose 设置为 1 ,以实时查看一个epoch后模型的拟合情况。
现在让我们可视化我们的一些结果。
使用深度学习进行可视化
我们将在我们达到的准确度和 epoch 数之间绘制图表,以了解我们的训练和验证准确度如何提高。
epochs = range(len(history.history['accuracy']))
plt.plot(epochs, history.history['accuracy'], 'green', label='Accuracy of Training Data')
plt.plot(epochs, history.history['val_accuracy'], 'red', label='Accuracy of Validation Data')
plt.xlabel('Total Epochs')
plt.ylabel('Accuracy achieved')
plt.title('Training and Validation Accuracy')
plt.legend(loc=0)
plt.figure()
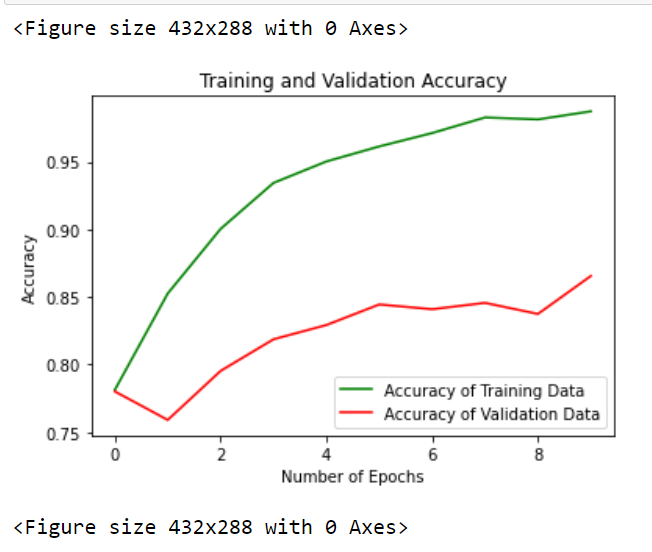
通过这个图表,我们可以假设我们的模型与训练和验证数据非常一致。现在我们将借助我们创建的模型对一些样本图像进行分类。
使用深度学习进行预测
为了借助我们的模型预测一些样本图像,我们首先需要导入该图像,对该图像执行归一化,并将其转换为数组以进行平滑预测。
from matplotlib.pyplot import imshow
from PIL import Image, ImageOps
data = np.ndarray(shape=(1, 130, 130, 3), dtype=np.float32)
image = Image.open("image(2).jpg")
size = (130, 130)
image = ImageOps.fit(image, size, Image.ANTIALIAS)
image_array = np.asarray(image)
display(image)
normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
data[0] = normalized_image_array
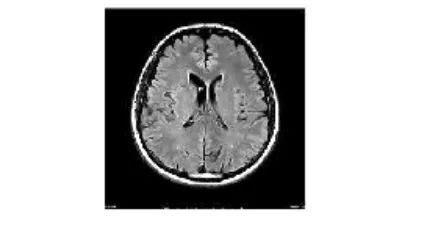
在这里,我们使用了 matplotlib 的 imshow,它可以帮助我们显示图像,以及 Python Imaging Library (PIL),它处理所有类型的图像操作。在 PIL 中,我们使用 ImageOps,这是一个用于多种成像和图像预处理操作的模块。
现在我们将使用我们的 CNN 模型预测上述图像的类别,即肿瘤类型。
prediction = cnn.predict(data)
print(prediction)
predict_index = np.argmax(prediction)
print(predict_index)
1/1 [==============================] - 0s 142ms/step
[[0. 0. 1. 0.]]
2
确认我们的上述归一化图像属于第二类,即没有肿瘤,这是正确的答案。让我们输出这个答案。
print("There's {:.2f} percent probability that the person has No Tumor".format(prediction[0][2]*100))
There's 100.00 percent probability that the person has No Tumor
通过这种方式,我们可以肯定地说,我们的 CNN 模型能够以最大的准确度有效地预测任何类型的脑肿瘤数据。你可以将上述任何脑肿瘤数据集用于给定的模型架构。
结论
正如我们所见,技术如何极大地影响了我们的生活方式和文化。使用技术来改善我们的生活是它所能做的最好的事情。在医疗保健中使用深度学习是最佳选择。与上述用于脑肿瘤分类的深度学习模型一样,我们可以通过应用某些修改在每个领域使用这些模型。
在本文中,我们学习了如何将 Tensorflow 和 Keras 用于这个深度学习模型和不同的技术来帮助提高我们的准确性,并且还进行了数据可视化。
原文标题 : 使用深度学习构建脑肿瘤分类器
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

