机器也能看图说话
机器看到图像或视频就能像人类一样进行精准地表述,这看似不可能,但已在深兰科学院诞生的“智慧交通协管员”,已把它变为了现实。
机器看到图像或视频就能像人类一样进行精准地表述,这看似不可能,但已在深兰科学院诞生的“智慧交通协管员”,已把它变为了现实。
这段视频的场景就是在城市繁忙的十字路口,尤其上下班高峰,行人违章现象非常多,即使有交警在路口执勤也很难做到面面俱到,此时“智慧交通协管员”将大大发挥作用。
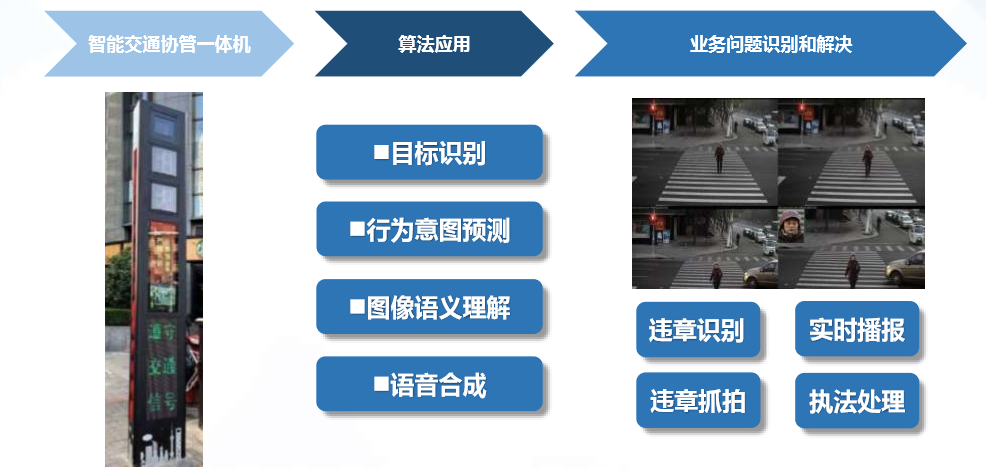
利用自主研发的图像语义识别算法,“智慧交通协管员”可以实时识别行人和非机动车违章行为,可识别的行为包括:
1. 行人闯红灯; 2. 非机动车闯红灯; 3. 非机动车在逆行; 4. 非机动车在斑马线骑行; 5. 非机动车在人行道骑行;
还可精确描述违章者特征,进行语音播报提醒,识别率可达80%以上。同时,支持个性化语音定制,可以利用现有的视频摄像头资源进行人脸识别违章抓拍,方便处罚,还可辅助对接车路协同系统。
其中涉及到的技术比较多,概括起来就是视觉理解、认知推理、自然语言生成和语音合成。接下来,我们会对其中的关键技术视觉理解和认知推理进行展开。
视觉理解+认知推理
一、认知智能概述
人工智能的发展可以粗略划分为三个阶段:计算智能、感知智能和认知智能。
计算智能通俗来说就是计算机能存储、记忆会运算,这方面,计算机的智能水平早已经远远超过人类。
感知智能就是计算机具备类似于人类的视觉和听觉等方面的能力,比如,听到了什么,对应语音识别;看到了什么,对应图像的分类检测和语义分割。其中人脸识别就是包含感知智能技术的一种人工智能应用,近年来,随着深度学习技术在视觉感知领域的蓬勃发展,目前机器感知智能的性能已经可与人类媲美,甚至在许多场景下已经超过人类。
认知智能强调知识、推理等技能,要求机器能理解、会思考,目前机器远不及人类。从计算智能到感知智能,标志着人工智能走向成熟;从感知智能到认知智能,是人工智能质的飞跃。认知智能,与人的语言、知识、逻辑相关,是人工智能的更高阶段,涉及到语义理解、知识表示、小样本学习甚至零样本学习、联想推理和自主学习等等。相比于计算智能和感知智能,认知智能是更复杂和更困难的任务,也是未来数十年最重要的任务。
二、视觉理解与推理
Image captioning的发展历程
1996-2000年 符号规则方法
追溯到1996年,Gerber发表了一篇知识表示的论文,限定于交通场景,在图像序列中用知识表示来进行自然语言描述的问题。2010年时,朱松纯(S.-C.Zhu)教授团队首次提出与或图(And-Or Graph)的模型。进一步与 D. Mumford 合作进行了框架的完善,融入随机上下文相关语法(Stochastic Context Sensitive Grammar),能对复杂物体的多层次构造特性(Hierarchical Compositionality)建模,完全表示图像语法(Image Grammar)。
与或图表示突破了传统单一模板(Template)的表示方法,对每类物体用多个图结构表示,该结构可以通过语法(Grammar)、产生规则(Production Rule)进行动态调制,从而可以用相对小的视觉字典(Visual Vocabulary),表达大量类间结构变化很大的物体的图像表现形式(Configuration)。
这些方法实际上都基于逻辑体系和规则的系统,对图像的内容设计很多规则,继而产生自然语言描述。由于强依赖于手工定制,人工特征工程的工作量就非常大,这也是当时亟待改善的问题。
2011-2013年 无明显进展
2014年至今 深度学习方法等
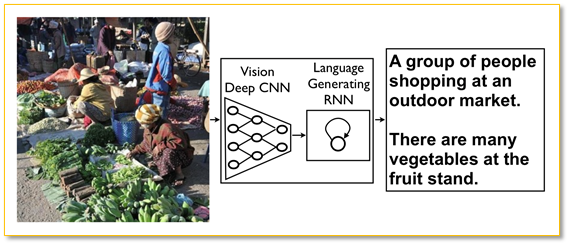
2014年,谷歌的Oriol Vinyals 等人公开论文《Show and Tell: A Neural Image Caption Generator》,并发表于2015年CVPR,开了深度学习在Image captioning中使用的先河。该方法来源于以前的机器翻译。
输入图形后,深度卷积神经网络对图形特征进行提取,通过固定长度矢量形成输入(Input)进入循环神经网络(RNN),经过一系列训练后,输出一段描述性的自然语言文字。按照时间序列的顺序,逐个词进行输出,条件依附于之前的词。
使用如下公式最大化给定图像的正确描述概率:

Encoding-Decoding 灵感来源于翻译模型。
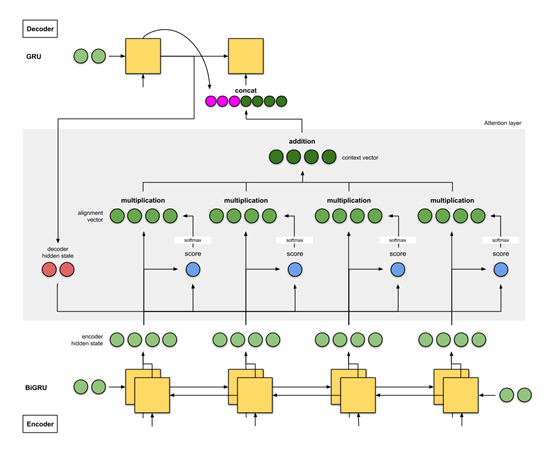
基于更复杂的视觉特征提取模型的Image Captioning。其中利用人的常识构建了一个知识库(ConceptNet),然后把它加入Encoding-Decoding模型里,赋予模型一定程度的常识能力。我们一直希望机器能有所谓的认知智能,实际上就是希望机器能够像人一样具有常识。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

