Notebook与计算机视觉的未来
FiftyOne是一个开源的可视化数据集分析工具,最近添加了Jupyter notebook支持,该功能是我实现的,并且是其技术主管。完成后,我着手撰写一篇文章,描述此功能的重要性——为什么自动屏幕截
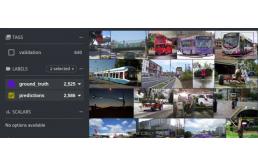
FiftyOne是一个开源的可视化数据集分析工具,最近添加了Jupyter notebook支持,该功能是我实现的,并且是其技术主管。
完成后,我着手撰写一篇文章,描述此功能的重要性——为什么自动屏幕截图非常适合与他人共享你的视觉发现,为什么将代码及其通常的视觉输出放在一个地方对于CV / ML如此重要,以及如何在notebook使用FiftyOne 可以开启notebook为CV / ML工程师和研究人员建立的更多范例。
本文希望做到所有这些事情,但从本质上讲,当我了解科学notebook的历史时,它也朝着另一个方向发展。从科学研究本身开始的历史。FiftyOne希望以此为基础。CV / ML社区需要比Jupyter Notebook更多的东西来进行视觉研究和分析。
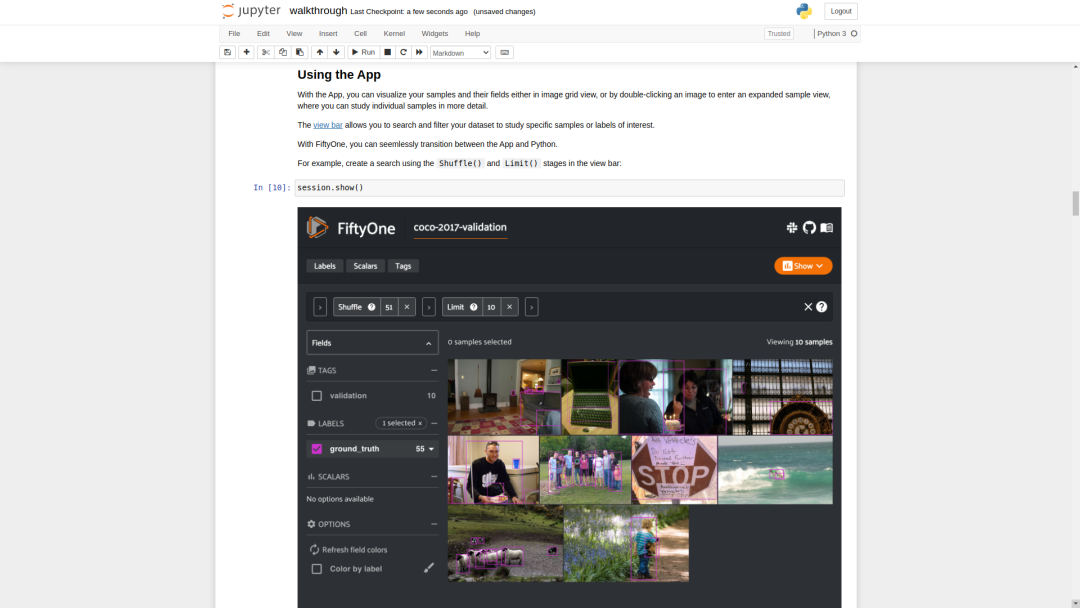
本文的最后一部分是在notebook中使用FiftyOne的分步指南,可帮助你发现可视数据集的问题。整个部分也可以通过Google的Colab找到。
Google’s Colab:https://colab.research.google.com/github/voxel51/fiftyone-examples/blob/master/examples/digging_into_coco.ipynb
我们将看到如何用很少的代码行来确认图像检测模型的常见故障模式并识别注释错误,同时在每一步的结果可视化的同时。但是在此之前,我会解释为什么CV / ML社区需要比Jupyter Notebook更多的东西来进行视觉研究和分析。科学状态科学论文的协同效率已经到达了瓶颈。
2018年4月,《大西洋》发表了一篇文章,宣布我们所知道的科学论文已经过时。实际上,这可能只是一个故意的预测,或者至少是互联网毫不客气的一种夸张说法。但是它勾勒出的科学出版历史是无可争议的。
在科学论文创建近400年之后,其协作效率已达到瓶颈。大量的科研人员在阐述该文章时取得了稳定的进步。现在已不适合时代。现在,成百上千的研究人员在一个领域发表论文,而不是几十人。结果往往不再是手工计算,而是由计算机、软件和曾经难以理解的数据集来计算。由于这种论文发表的规模,可重复性现在比以往任何时候都变得更加重要。但通常情况下,为使研究人员能够重现自己的研究成果而采取的措施是不够的。通常情况下,提供的代码和数据是不完整的,如果提供了代码和数据,并且使用丰富的动态可视化语言描述复杂思想,这种动态可视化语言是用抽象的语言和简化的静态图表来描述的。共享研究的方式与完成研究的方式不再匹配。
Wolfram的围墙花园
现代研究的计算复杂性和规模一直是科学进步和技术创新的福音。与科学研究论文的顽固形式(即PDF)并列在一起,几十年来,这也是一个公认的问题。不过,一个解决方案已经存在了数十年。一种以相同方式甚至相同形式完成研究并共享的解决方案。该解决方案诞生于1988年,当时由史蒂芬·沃尔夫拉姆(Steven Wolfram)创立的沃尔夫拉姆研究中心(Wolfram Research)发布了Mathematica,成为了计算的“notebook” 。该界面由西奥多·格雷(Theodore Gray)牵头,由早期的苹果代码编辑器提供了信息,并且部分由史蒂夫·乔布斯(Steve Jobs)协助制定。
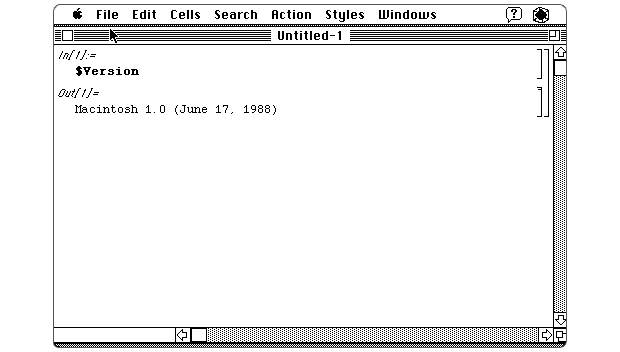
Wolfram Mathematica的版本1,于1988年发布。由Stephen Wolfram Blog提供。三十多年来,Mathematica一直在增加它可以为你解答的问题,可以可视化数据的数字方式以及可以使用的数据量。但是,自推出的第一个十年以来,增长一直很缓慢。许可证价格昂贵,发布商不想使用它们,而Mathematica支持的功能始于Wolfram Research。这是一个美丽而功能强大的围墙花园(Walled Garden)。
Python,Jupyter
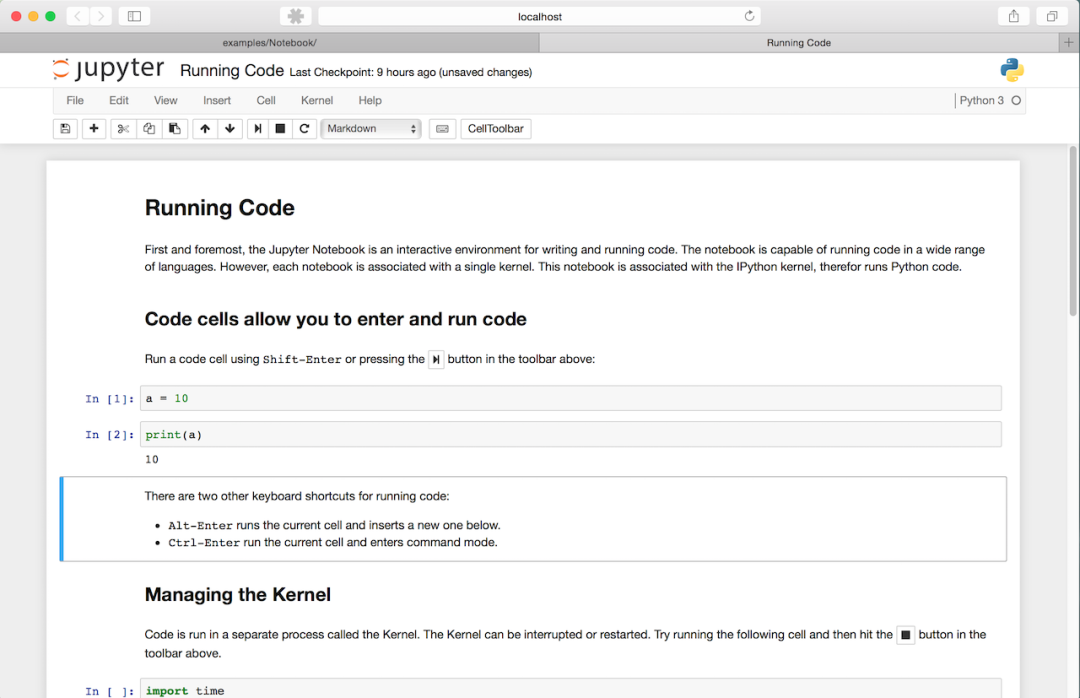
随着Mathematica继续朝着追求完美的方向前进,2001年初,物理学专业的研究生FernandoPérez发现自己对自己的研究能力已经感到厌倦,即使Mathematica任其支配也是如此。在《大西洋彼岸一书中,他迷上了新的编程语言Python,并在另外两名研究生的帮助下开始了一个名为IPython的项目,即 Jupyter 项目的基础。Jupyter并非在“技术层面”上而是在“社会层面”上胜过Mathematica。如今,Jupyter Notebook电脑的核心是Jupyter Notebook电脑。像Mathematica一样*,* Jupyter Notebook鼓励科学探索。但是与Mathematica不同*,它是任何人都可以贡献的开源项目。Jupyter并非在“技术层面”上而是在“社会层面”上胜过Mathematica*,正如诺贝尔奖获得者Paul Romer所指出的那样。Jupyter Notebooks的形式由活跃的开发人员和用户社区决定。计算机视觉领域完全属于科学研究领域。多年来,学术界和行业研究人员都在Jupyter Notebook电脑中发现了难以置信的价值。单个数据片段通常是图像和视频本身,需要对其进行查看和观看。notebook电脑提供了。可共享的可视化需要共享。notebook电脑提供了。Jupyter的开放生态系统允许开发人员轻松添加任何缺失的集成。
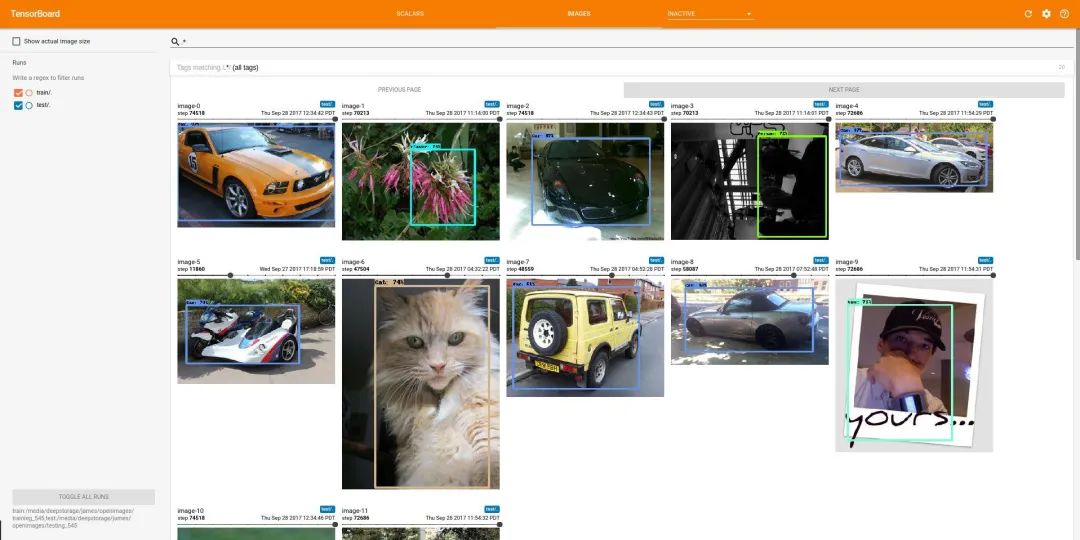
TensorBoard可以嵌入Jupyter Notebook中,用于对象检测实验。像matplotlib和opencv这样的软件包可用于显示需要检查的图像和视频。在训练机器学习模型时,类似tensorboard的软件包会提供示例可视化,将图像检查扩展到实验跟踪的范围内。matplotlib,opencv,tensorboard,和其他无数Python包与可视化功能都可以在Jupyter Notebook电脑中使用。理解数据质量需要对数据趋势有深刻的了解。但是,在CV / ML中,使用Jupyter Notebook时仍然存在一个明显的问题。数据质量对于构建出色的模型至关重要。要了解数据质量,就需要对数据趋势进行明智的了解。仅仅看一个甚至十几个图像几乎总是不足以了解模型的性能和故障模式。此外,在ground truth或gold standard标签中识别可能只在1,000张甚至100,000张图像中出现的单个错误,需要对数据集进行快速切片和切割,以缩小问题范围。从根本上说,目前还缺乏能够自然地处理notebook中可视化数据集的工具来解决这类问题。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

