利用生成对抗网络生成海洋塑料合成图像
问题陈述过去十年来,海洋塑料污染一直是气候问题的首要问题。海洋中的塑料不仅能够通过勒死或饥饿杀死海洋生物,而且也是通过捕获二氧化碳使海洋变暖的一个主要因素。近年来,非营利组织海洋清洁组织(Ocean Cleanup)多次尝试清洁环绕我们海洋的塑料

问题陈述
过去十年来,海洋塑料污染一直是气候问题的首要问题。海洋中的塑料不仅能够通过勒死或饥饿杀死海洋生物,而且也是通过捕获二氧化碳使海洋变暖的一个主要因素。
近年来,非营利组织海洋清洁组织(Ocean Cleanup)多次尝试清洁环绕我们海洋的塑料。很多清理过程的问题是,它需要人力,而且成本效益不高。
通过使用计算机视觉和深度学习检测海洋碎片,利用ROV和AUV进行清理,已经有很多研究将这一过程自动化。
这种方法的主要问题是关于训练计算机视觉模型的数据集的可用性。JAMSTEC-JEDI数据集收集了日本沿海海底的海洋废弃物。
但是,除了这个数据集,数据集的可用性存在巨大差异。因此,我利用了生成对抗网络的帮助。
DCGAN尤其致力于合成数据集,理论上,随着时间的推移,这些数据集可能与真实数据集非常接近。
GAN和DCGAN
2014年,伊恩·古德费罗等人提出了GANs或生成对抗网络。GANs由两个简单的组件组成,分别称为生成器和鉴别器。
该过程如下:生成器角色用于生成新数据,而鉴别器角色用于区分生成的数据和实际数据。在理想情况下,鉴别器无法区分生成的数据和真实数据,从而产生理想的合成数据点。
DCGAN是上述GAN结构的直接扩展,只是它在鉴别器和发生器中分别使用了深卷积层。Radford等人在论文中首次描述了深度卷积生成对抗网络的无监督表征学习。鉴别器由跨步卷积层组成,而生成器由卷积转置层组成。
PyTorch实现
在这种方法中,将在DeepTrash数据集。如果你不熟悉DeepTrash数据集,请考虑阅读论文。
DeepTrash是海洋表层和深海表层塑料图像的集合,旨在利用计算机视觉进行海洋塑料检测。
让我们开始编码吧!
代码
安装
我们首先安装构建GAN模型的所有基本库,比如Matplotlib和Numpy。
我们还将利用PyTorch的所有工具(如神经网络、转换)。
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
# Set random seem for reproducibility
manualSeed = 999
#manualSeed = random.randint(1, 10000) # use if you want new results
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
初始化超参数
这一步相当简单。我们将设置我们想要用来训练神经网络的超参数。这些超参数直接来自于论文和PyTorch的训练教程。
# Root directory for dataset
# NOTE you don't have to create this. It will be created for you in the next block!
dataroot = "/content/pgan"
# Number of workers for dataloader
workers = 4
# Batch size during training
batch_size = 128
# Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 64
# Number of channels in the training images. For color images this is 3
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 64
# Size of feature maps in discriminator
ndf = 64
# Number of training epochs
num_epochs = 300
# Learning rate for optimizers
lr = 0.0002
# Beta1 hyperparam for Adam optimizers
beta1 = 0.5
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
生成器和鉴别器
现在,我们定义生成器和鉴别器的体系结构。
# Generator
class Generator(nn.Module):
def __init__(self, ngpu)
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 2, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# Discriminator
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 4, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
定义训练函数
在定义生成器和鉴别器类之后,我们继续定义训练函数。
训练函数采用生成器、鉴别器、优化函数和epoch数作为参数。我们通过递归调用train函数来训练生成器和鉴别器,直到达到所需的epoch数。
我们通过迭代数据加载器,用生成器中的新图像更新鉴别器,并计算和更新损失函数来实现这一点。
def train(args, gen, disc, device, dataloader, optimizerG, optimizerD, criterion, epoch, iters):
gen.train()
disc.train()
img_list = []
fixed_noise = torch.randn(64, config.nz, 1, 1, device=device)
# Establish convention for real and fake labels during training (with label smoothing)
real_label = 0.9
fake_label = 0.1
for i, data in enumerate(dataloader, 0):
#*****
# Update Discriminator
#*****
## Train with all-real batch
disc.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
# Forward pass real batch through D
output = disc(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Train with all-fake batch
# Generate batch of latent vectors
noise = torch.randn(b_size, config.nz, 1, 1, device=device)
# Generate fake image batch with G
fake = gen(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = disc(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch
errD_fake.backward()
D_G_z1 = output.mean().item()
# Add the gradients from the all-real and all-fake batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
#*****
# Update Generator
#*****
gen.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another forward pass of all-fake batch through D
output = disc(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f'
% (epoch, args.epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
wandb.log({
"Gen Loss": errG.item(),
"Disc Loss": errD.item()})
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == args.epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = gen(fixed_noise).detach().cpu()
img_list.append(wandb.Image(vutils.make_grid(fake, padding=2, normalize=True)))
wandb.log({
"Generated Images": img_list})
iters += 1
监督和训练DCGAN
在我们建立了生成器、鉴别器和训练函数之后,最后一步就是简单地调用我们定义的eoich数的训练函数。我还使用了Wandb,它允许我们监控我们的训练。
#hide-collapse
wandb.watch_called = False
# WandB – Config is a variable that holds and saves
hyperparameters and inputs
config = wandb.config # Initialize config
config.batch_size = batch_size
config.epochs = num_epochs
config.lr = lr
config.beta1 = beta1
config.nz = nz
config.no_cuda = False
config.seed = manualSeed # random seed (default: 42)
config.log_interval = 10 # how many batches to wait before logging training status
def main():
use_cuda = not config.no_cuda and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
# Set random seeds and deterministic pytorch for reproducibility
random.seed(config.seed) # python random seed
torch.manual_seed(config.seed) # pytorch random seed
np.random.seed(config.seed) # numpy random seed
torch.backends.cudnn.deterministic = True
# Load the dataset
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=config.batch_size,
shuffle=True, num_workers=workers)
# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)
# Initialize BCELoss function
criterion = nn.BCELoss()
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr
config.lr, betas=(config.beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=config.lr, betas=(config.beta1, 0.999))
# WandB – wandb.watch() automatically fetches all layer dimensions, gradients, model parameters and logs them automatically to your dashboard.
# Using log="all" log histograms of parameter values in addition to gradients
wandb.watch(netG, log="all")
wandb.watch(netD, log="all")
iters = 0
for epoch in range(1, config.epochs + 1):
train(config, netG, netD, device, trainloader, optimizerG, optimizerD, criterion, epoch, iters)
# WandB – Save the model checkpoint. This automatically saves a file to the cloud and associates it with the current run.
torch.save(netG.state_dict(), "model.h5")
wandb.save('model.h5')
if __name__ == '__main__':
main()
结果
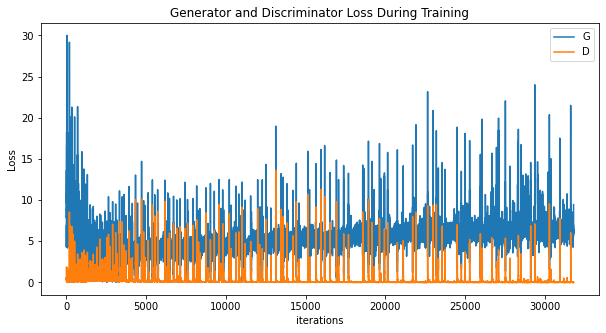
我们绘制了生成器和鉴别器在训练期间的损失。
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
我们还可以查看生成器生成的图像,以查看真实图像和虚假图像之间的差异。
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())
看起来像这样:
结论
在本文中,我们讨论了使用深度卷积生成对抗网络生成海洋塑料的合成图像,研究人员可以使用这些图像来扩展他们当前的海洋塑料数据集。这有助于让研究人员能够通过混合真实和合成图像来扩展他们的数据集。
从结果中可以看出,GAN仍然需要大量的工作。海洋是一个复杂的环境,光照、浑浊度、模糊度等各不相同。
原文标题 : 利用生成对抗网络生成海洋塑料合成图像
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

