重新思考视觉transformers的空间维度
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。前言:由于基于transformers的架构在计算机视觉建模方面具有创新性,因此对有效架构的设计约定的研究还较少。从 CNN 的成功设计原则出发


欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
前言:
由于基于transformers的架构在计算机视觉建模方面具有创新性,因此对有效架构的设计约定的研究还较少。从 CNN 的成功设计原则出发,我们研究了空间维度转换的作用及其对基于transformers的架构的有效性。
我们特别关注CNNs的降维原理;随着深度的增加,传统的 CNN 会增加通道维度并减少空间维度。我们凭经验表明,这种空间降维也有利于transformers架构,并在原始 ViT 模型上提出了一种新型的基于池化的视觉transformers (Pooling-based Vision Transformer--PiT)。
我们表明 PiT 实现了针对 ViT 的改进模型能力和泛化性能。在广泛的实验中,我们进一步表明 PiT 在图像分类、目标检测和鲁棒性评估等多项任务上优于baseline。
出发点
1. CNN 限制了空间交互,ViT 允许图像中的所有位置通过transformers层交互。
2. 虽然ViT 是一种创新架构,并且已经证明了其强大的图像识别能力,但它沿用了NLP中的 Transformer 架构,没有任何变化。
3. CNN 的一些基本设计原则在过去十年中已被证明在计算机视觉领域有效,但并未得到充分反映。
因此,我们重新审视了 CNN 架构的设计原则,并研究了它们在应用于 ViT 架构时的功效。
创新思路
CNN 以大空间尺寸和小通道尺寸的特征开始,并逐渐增加通道尺寸,同时减小空间尺寸。由于称为空间池化的层,这种维度转换是必不可少的。现代 CNN 架构,包括 AlexNet、ResNet和 EfficientNet,都遵循这一设计原则。
池化层与每一层的感受野大小密切相关。 一些研究表明,池化层有助于网络的表现力和泛化性能。 然而,与 CNN 不同的是,ViT 不使用池化层,而是在所有层中使用相同大小的空间。
首先,我们验证了 CNN 上池化层的优势。我们的实验表明,池化层证明了 ResNet 的模型能力和泛化性能。为了将池化层的优势扩展到 ViT,我们提出了一种基于池化的视觉transformers (PiT)。
PiT 是一种与池化层相结合的转换器架构。它可以像在 ResNet 中一样减少 ViT 结构中的空间大小。我们还研究了 PiT 与 ViT 相比的优势,并确认池化层也提高了 ViT 的性能。
最后,为了分析 ViT 中池化层的效果,我们测量了 ViT 的空间交互比,类似于卷积架构的感受野大小。我们展示了池化层具有控制自注意力层中发生的空间交互大小的作用,这类似于卷积架构的感受野控制。
Methods

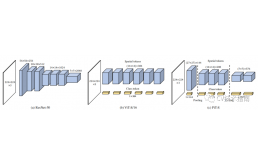
网络架构维度配置的示意图
我们将 ResNet50 、Vision Transformer (ViT) 和基于池化的 Vision Transformer (PiT) 可视化;(a) ResNet50 从输入到输出逐渐下采样特征;(b) ViT 不使用池化层,因此所有层都保持特征维度;(c) PiT 涉及将层汇集到 ViT 中。
Pooling-based Vision Transformer(PiT)

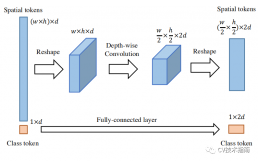
PiT 架构的池化层
PiT 使用基于深度卷积的池化层,以小参数实现通道乘法和空间缩减。

Effects of the pooling layer in vision transformer (ViT)
我们在网络架构的各个方面将我们的基于池化的视觉transformer (PiT) 与原始 ViT 进行了比较。PiT 在容量、泛化性能和模型性能方面优于 ViT。
Spatial interactio
self-attention层在交互token数量上也有限制,因此交互区域是根据空间大小来确定的。
我们使用 ImageNet 上的预训练模型测量了 ViT 和 PiT 的空间交互区域。空间交互的标准是基于注意力矩阵的 soft-max 之后的分数。我们使用 1% 和 10% 作为阈值,计算超过阈值的交互发生的空间位置的数量,并通过将交互位置的数量除以空间标记的总大小来计算空间交互比率。
在 ViT 的情况下,交互作用平均在 20%-40% 之间,并且由于没有池化层,因此数值不会因层而有显着变化。PiT 减少了token的数量,同时通过池化增加了头部。
因此,如图 5 (a) 所示,早期层的交互率很小,但后一层显示出接近 100% 的交互率。为了与 ResNet 进行比较,我们将阈值更改为 10%,结果如图 5 (b) 所示。

在 ResNet 的情况下,3x3 卷积意味着 3x3 空间交互。因此,我们将 3x3 除以空间大小,并将其作为近似值与注意力的交互率进行比较。虽然 ViT 的交互率在各层中是相似的,但 ResNet 和 PiT 的交互率随着它通过池化层而增加。
Architecture

该表显示了 ViT 和 PiT 的spatial sizes, number of blocks, number of heads, channel size, 和FLOPs。PiT 的结构设计为尽可能与 ViT 相似,并具有更少的 GPU 延迟。
Conclusion
我们验证了 PiT 在各种任务上提高了 ViT 的性能。在 ImageNet 分类中,PiT 和在各种规模和训练环境下都优于 ViT。此外,我们还比较了 PiT 与各种卷积架构的性能,并指定了 Transformer 架构优于 CNN 的规模。
我们使用检测头进一步测量 PiT 在目标检测方面的性能。 基于 ViT 和 PiT 的 DETR在 COCO 2017 数据集上进行训练,结果表明 PiT 作为主干架构甚至比 ViT 更适合图像分类以外的任务。最后,我们通过稳健性基准验证了 PiT 在各种环境中的性能。


本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
相关文章












 AIGC热点
热点
AIGC热点
热点
-
19打开,有戏

